CS 질문
개요
면접 질문들을 정리한 문서이다. 웹 개발, 시스템 / 네트워크 프로그래밍, 보안에 대한 면접 질문이 섞여 있어 필요한 부분만 찾아보는 것을 추천한다.
자세한 내용은 Ctrl + F 로 찾아보는 것을 권한다.
CS 질문
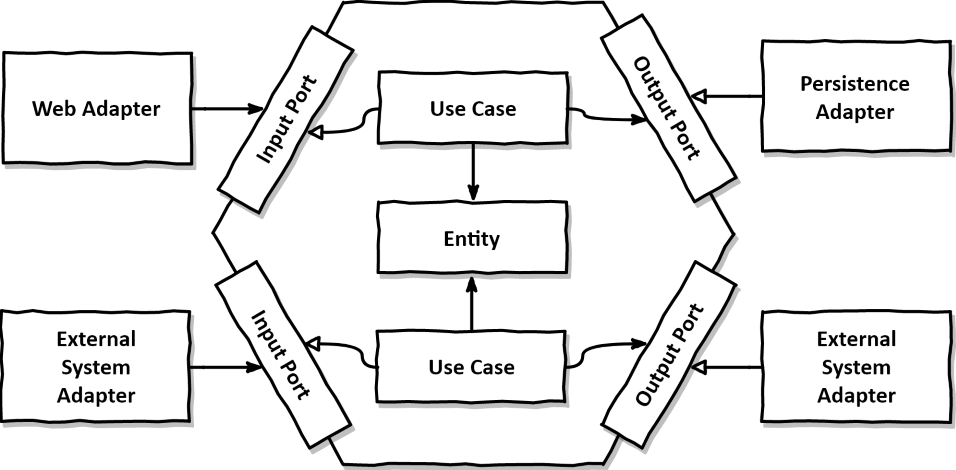
헥사고날 아키텍쳐
응용 프로그램의 비즈니스 로직을 외부 세계로부터 격리시켜 유연하고 테스트하기 쉬운 구조를 만드는 것 이를 위해 핵심 비즈니스 로직은 중앙의 도메인 영역에 위치하며, 입력과 출력을 처리하는 포트와 어댑터를 통해 외부와 소통합니다.
SOLID (객체 지향 설계의 5가지 원칙)
- S: Single Responsibility Principle (단일 책임 원칙)
- 하나의 클래스는 하나의 책임만 가져야 한다.
- O: Open/Closed Principle (개방-폐쇄 원칙)
- 확장에는 열려있고, 변경에는 닫혀있어야 한다.
- 기능이 변하거나 확장 가능하지만, 해당 기능의 코드는 수정하면 안 된다. (기능을 확장하기 위해 기존 코드의 수정이 필요하지 않는 것.)
- ex) JDBC: db 변경 시 connection 객체 부분만 변경해주면 된다.
- L: Liskov Substitution Principle (리스코프 치환 원칙)
- 자식 클래스는 부모 클래스를 대체할 수 있어야 한다.
- 부모 클래스의 행동 규약을 자식 클래스가 위반하면 안 된다.
- 부모 클래스의 인스턴스를 자식 클래스의 인스턴스로 대체해도 프로그램의 원래 동작에 영향을 주지 않아야 한다.
- 자식 클래스는 부모 클래스를 대체할 수 있어야 한다.
- I: Interface Segregation Principle (인터페이스 분리 원칙)
- 클라이언트는 자신이 사용하지 않는 인터페이스에 의존하지 않아야 한다.
- 하나의 큰 인터페이스보다는 여러 개의 작은 인터페이스로 나누어야 한다.
- D: Dependency Inversion Principle (의존성 역전 원칙 - DIP)
- 추상화에 의존해야 하고, 구체화에는 의존하지 말아야 한다.
- 구체화에 의존하면 변경이 어려워진다.
- 추상화에 의존하면 변경이 용이해진다.
- Spring Framework 및 각종 웹 프레임워크에서 의존성 역전 원칙이 적용되어 있다.
- 의존성 주입
- ex) 개발자가 비즈니스 로직을 상세하게 구현 (구체화) 한 뒤, 웹 프레임워크에서 제공한 추상화 인터페이스에 연결해 의존성을 주입한다.
- 의존성 주입
디자인 패턴
경력직 한정 각 디자인 패턴을 어느정도는 알고 있어야 한다.
각 패턴을 하나하나 상세히 설명하면, 내용이 매우 길어지므로 간략한 설명으로 대체한다. 디자인 패턴의 경우, 3~5줄 정도의 매우 단순한 예제코드로는 표현할 수 조차 없고, 특정한 상황을 직접 겪어 보거나 예제 코드를 직접 작성해보지 않으면 이해하기 어렵기 때문에 다른 책이나 온라인 자료를 참고하는 것을 추천한다.
(행구생)
- 생성 패턴
-
싱글톤 (Singleton)
- 하나의 클래스 인스턴스를 전역에서 접근 가능하게 하면서 해당 인스턴스가 한 번만 생성되도록 보장하는 패턴
-
팩토리 메서드 (Factory Method)
- 객체를 생성하기 위한 인터페이스를 정의하고, 서브클래스에서 어떤 클래스의 인스턴스를 생성할지 결정
- 추상 팩토리 (Abstract Factory)
- 관련된 객체들의 집합을 생성하는 인터페이스를 제공하며, 구체적인 팩토리 클래스를 통해 객체 생성을 추상화하는 패턴
-
빌더 (Builder)
- 복잡한 객체의 생성 과정을 단순화하고, 객체를 단계적으로 생성하며 구성하는 패턴
- 프로토타입 (Prototype)
- 객체를 복제하여 새로운 객체를 생성하는 패턴으로, 기존 객체를 템플릿으로 사용하는 패턴
-
싱글톤 (Singleton)
- 구조 패턴
- 어댑터 (Adapter)
- 인터페이스 호환성을 제공하지 않는 클래스를 사용하기 위해 래퍼(Wrapper)를 제공하는 패턴
- 브리지 (Bridge)
- 추상화와 구현을 분리하여 두 가지를 독립적으로 확장할 수 있는 패턴
- 컴포지트 (Composite)
- 개별 객체와 복합 객체를 동일하게 다루어, 트리 구조의 객체를 구성하는 패턴
- 데코레이터 (Decorator)
- 객체에 동적으로 새로운 기능을 추가하여 객체를 확장할 수 있는 패턴
- 퍼사드 (Facade)
- 서브시스템을 더 쉽게 사용할 수 있도록 단순한 인터페이스를 제공하는 패턴
- 플라이웨이트 (Flyweight)
- 공유 가능한 객체를 통해 메모리 사용을 최적화하는 패턴
- 프록시 (Proxy)
- 다른 객체에 대한 대리자(Proxy)를 제공하여 접근 제어, 지연 로딩 등을 구현하는 패턴
- 어댑터 (Adapter)
- 행위 패턴
- 책임 연쇄 (Chain of Responsibility)
- 요청을 보내는 객체와 이를 처리하는 객체를 분리하여, 다양한 처리자 중 하나가 요청을 처리하는 패턴
- 커맨드 (Command)
- 요청을 객체로 캡슐화하여 요청을 매개변수화 하고, 요청을 큐에 저장하거나 로깅하고 실행을 지연시키는 패턴
- 옵저버 (Observer)
- 객체 간의 일대다 종속 관계를 정의하여 한 객체의 상태 변경이 다른 객체들에게 알려지도록 하는 패턴
- 인터프리터 (Interpreter)
- 언어나 문법에 대한 해석기를 제공하여, 주어진 언어로 표현된 문제를 해결하는 패턴
- 방문자 (Visitor)
- 객체 구조를 순회하면서 다양한 연산을 수행하게 만드는 패턴
- 중재자 (Mediator)
- 객체 간의 상호 작용을 캡슐화하여, 객체 간의 직접적인 통신을 방지하는 패턴
-
반복자 (Iterator - 이터레이터)
- 컬렉션 내의 요소들에 접근하는 방법을 표준화하여 컬렉션의 내부 구조에 독립적으로 접근할 수 있는 패턴 (C++의 Iterator)
-
전략 (Strategy)
- 알고리즘을 정의하고, 실행 중에 선택할 수 있게 하는 패턴
- 상태 (State)
- 객체의 상태를 캡슐화하고, 상태 전환을 관리하는 패턴
-
템플릿 메서드 (Template Method)
- 알고리즘의 구조를 정의하면서 하위 클래스에서 각 단계의 구현을 제공하는 디자인 패턴
- 메멘토 (Memento)
- 객체의 내부 상태를 저장하고 복원할 수 있는 기능을 제공하는 패턴
- 책임 연쇄 (Chain of Responsibility)
출처: https://ittrue.tistory.com/550
설계 질문
동시성 처리
웹 백엔드 질문 MSA (Micro Service Architecture) 에서 아래 동시성 문제를 처리할 수 있는 방법이나 설계에 대해 고민해 볼 것.
- 따닥 문제 (중복 호출 문제)
- API가 중복으로 호출되었을 경우에 대한 처리
- ex) 결제 API가 두 번 호출되어 사용자는 결제 버튼을 한번 눌렀지만 두 번 결제됨.
- ex) 결제 버튼을 매우 빠른 시간안에 따닥 하고 두번 (더블클릭) 하자, 두 번 결제됨.
- 프론트에서 물론 막을 수 있겠지만, 버그가 발생하거나 특정 상황에서 API가 두 번 호출될 수 있는 문제를 해결해야 한다.
- 예시: (사용자가 결제 도중 뒤로가기를 눌렀다가 다시 결제 페이지로 오는 경우는 막을 수 없음.)
- 근본적인 설계 등의 변경으로 해당 상황의 완전 방지가 필요함.
- https://blog.wadiz.kr/%EB%B6%84%EC%82%B0-%ED%99%98%EA%B2%BD-%EC%86%8D%EC%97%90%EC%84%9C-%EB%94%B0%EB%8B%A5%EC%9D%84-%EC%99%B8%EC%B9%98%EB%8B%A4/
- API가 중복으로 호출되었을 경우에 대한 처리
- 선착순 문제
- 선착순 이벤트(선착순 100명 버튼)을 개발하는 방법 (이 때, 사용자가 매우 많이 몰린다고 가정한다.)
- ex) 쿠폰 발급 선착순 이벤트 100명 중 99명이 완료된 상태. 이후 1명이 남은 상태에서 2명이 동일한 시각에 쿠폰발급 버튼을 눌렀다.
- 요청한 2명 모두에게 쿠폰을 발급할 수 없다. (쿠폰은 정확히 100개로, 101개 또는 그 이상의 개수를 발급할 수 없는 상황)
캐시 처리 질문
- 캐시 관통
- 데이터베이스에서 읽었는데도 캐싱 되지 않는 상황
- 보통 DB에 값이 없을 때 null을 받아오면 캐시를 채우지 않도록 구현하는데, ‘값이 없다’ 라는 정보를 캐싱하지 않으면 계속 불필요한 요청을 하게된다.
- https://toss.tech/article/cache-traffic-tip
- 해결방법: 널 오브젝트 패턴 (Null Object Pattern)
- 이 객체를 대체할 특정 값을 지정해야 한다.
- 예를 들어 양수만 존재하는 정수 타입의 데이터를 캐시해야하는 경우, 음수의 정수인 최소값으로 ‘값이 없음’을 나타내기로 애플리케이션에서 약속할 수 있다.
- 캐시 쇄도
- 캐시가 전부 같은 시간에 만료되도록 하면 발생하는 이슈
- 해결 방법
- 지터(jitter): 캐시 만료 시간에 0~10초 사이의 무작위 지연 시간을 추가하여 설정
- 캐시 시스템 장애
- 트래픽이 큰 상황에서 캐시 시스템이 장애가 날 경우 복구 되기 전까지 DB에 과부하가 걸릴 수 있다.
- 해결방법: 대체 작동 (Failover - 이중화 설계에 대해 더욱 자세히 설명함.)
- 현실적으로 반드시 동작해야하는 핵심 기능을 제외하고 부가 기능은 운영을 중단하는게 옳다.
- 핫키 만료
- 핫키: 많은 요청이 집중되는키
- 핫키가 만료되는 순간 여러 요청이 동시에 DB를 조회하게 된다. 캐시 만료기한을 없애거나 주기적으로 새값을 적용해서 만료되지 않도록 하는 것이 좋다. 하지만 핫키가 아닌 데이터로 인해 캐시 저장소가 낭비될 수 있다.
- 해결 방법: 분산락(Distributed Lock)
- 멀티 스레드 프로그래밍에서 공유 자원을 다룰 때 락을 사용하는 것과 비슷한 원리.
- 캐시 미스가 발생했을 때 락을 설정하고 캐싱한 후에 락을 해제함으로써 단 한번의 쓰기 작업만 허용할 수 있다.
- Redis 를 사용한다면 적용하기 쉽다. (레드락 알고리즘)
단일 장애 지점 (SPOF - Single Point of Failure)
- 코드 레벨의 SPOF
- 원인: 과도한 의존성 문제
- 특정 외부 서비스나 API에 의존할 경우, 애플리케이션의 중요 기능이 중단될 위험이 있다. 특히 결체 처리나 사용자 인증과 같은 핵심 기능을 담당하는 외부서비스에 이런 위험이 크다
- 해결 방안
- 외부 서비스에 대한 타임 아웃 호출에 대한 타임 아웃 설정을 하거나, 서킷 브레이커 패턴을 사용해서 서비스 장애 시 자동으로 대체 서비스로 전환되도록 구상한다. 이는 장애 발생 시 즉시 대응할 수 있게 해 준다. 또한 한 서비스만에 만 의존하는 대신 여러 서비스 제공자를 사용함으로써 의존성을 분산시킨다.
- 서킷 브레이커 패턴
- 다른 서비스에 장애가 발생하였는데도 계속 요청을 주어 장애 복구를 힘들게 만드는 상황을 방지하고자, 장애가 발생한 서비스를 탐지하고 요청을 보내지 않도록 차단하는 것. 즉, 실패할 수 있는 작업을 계속 시도하지 않도록 방지한다 만약 계속 장애가 나는 서비스를 요청하면 타임아웃만큼 대기시간이 생기고 스레드와 메모리 등 CPU의 자원을 점유하여 결국 시스템 리소스를 부족하게 만들어 장애를 유발할 수 있다. Java 진영의 서킷 브레이커 라이브러리로는 Resilence4J라는 것이 대표적이다.
- 단일 데이터베이스의 SPOF
- 원인: 하나의 데이터베이스에 의존 -> 해당 데이터베이스가 장애
- 하나의 데이터베이스에 의존하게 되면 서버 장애 시 데이터 처리가 중단되고 전체 시스템에 영향을 준다.
- 해결 방안: 여러 해결책이 있는데 대표적으로 레플리케이션, 샤딩, 클러스터링이 있다.
- 레플리케이션, 샤딩, 클러스터링은 밑에서 설명
- 클러스터링은 Redis의 redis 클러스터링이 대표적이다. (master-slave 구조를 참고한다.)
- 레플리케이션, 샤딩, 클러스터링은 밑에서 설명
- 서버 SPOF
- 원인: 하나의 서버에 의존 -> 해당 서버가 장애
- 하나의 서버에 의존하게 되면 서버 장애 시 서비스 제공이 어렵다.
- 해결 방법: 서버를 여러 대 띄워 1번 서버 장애 시 2번 서버가 처리를 진행하는 등 이중화나 FailOver 구성 로드밸런서 등과 함께 이용하여 부하분산을 할 수 있다.
이중화 (HA - High Availability) & 백업 (Backup)
- Active / Standby (FailOver)
실제 동작하는 서버와 예비용 서버 (장애를 대비한 서버) 를 둔다. 일반적인 환경에서는 Active (실제 동작 중인 장비) 가 동작한다. 해당 서버가 장애 시 Standby 서버가 Active 서버로 전환된다.
- Active / Active
동작하는 서버를 두 대 준비하여 해당 두 서버가 모두 동시에 요청을 처리한다. 이 때, 두 서버는 동일한 데이터를 가지고 있어야 하는 등 동기화나 데이터 일관성 문제 등 여러 문제가 발생할 수 있어, 많이 사용되지는 않는다.
- 하드웨어의 이중화
- 디스크 이중화
- 네트워크 이중화 …
- DB 이중화
- 백업 방법
로그와 모니터링
- 로그의 수집과 관리, 분석 방법
- 사례: 사용자들의 로그를 수집해 발빠른 이슈 분석, 장애 상황 대응, 특정 시간의 부하율, 사용자의 행동 패턴을 파악해 서비스 성능 향상시키고, 노출 알고리즘을 최적화하여 광고 수익 향상 등
- 위와 같은 사례 등으로 인해 로그의 수집, 관리, 분석이 중요해졌다.
- 큰 규모의 서비스 제공자는 초당 GB, TB 수준의 로그가 모이는 경우가 많다. 이러한 로그를 처리할 수 있게끔 시스템을 설계하는 방안을 고민해 볼 것.
- 모니터링 서비스 및 환경 구축 (DataDog)
- DataDog는 로그 수집, 분석, 모니터링 서비스를 제공한다.
- 부하나 트래픽 몰림 현상 발생 시 자동으로 AutoScale 등을 진행하는 환경 구축 방안을 고민해 볼 것.
- observability (관찰 가능성)에 대한 인사이트
- 시스템의 내부 상태를 외부에서 관찰할 수 있는 능력
우리가 만든 시스템이 지금 어떤 상태인지, 뭔가 문제가 생겼을 때 왜 그런 문제가 발생했는지를 파악할 수 있는 정도
- 3가지 기둥
- 로그 (Logs)
- 시스템에서 발생하는 이벤트들의 기록
- 언제, 무엇이, 어떻게 일어났는지 알려줌
- 디버깅할 때 가장 기본적으로 확인하는 정보
- 메트릭 (Metrics)
- 시스템의 성능, 지표를 숫자로 표현
- CPU 사용률, 메모리 사용량, 응답 시간 등
- 시간에 따른 변화를 추적
- 트레이스 (Traces)
- 하나의 요청이 시스템을 통과하는 전체 경로를 추적
- 마이크로서비스 환경에서 특히 중요
- 어디에서 병목이 발생했는지 파악 가능
- 로그 (Logs)
- 모니터링 vs 관찰가능성
- 모니터링
- “뭔가 잘못되었다.” 라는 것을 알려주는 것
- 관찰 가능성
- “왜 잘못되었는가?” 를 파악할 수 있게 해주는 것.
- “어디서, 언제, 왜” 명확하게 알 수 있음.
- 모니터링
- 왜 중요한가?
- 빠른 문제 해결
- 장애 발생 시, 원인을 빠르게 찾을 수 있음.
- 성능 최적화
- 시스템의 병목 지점을 정확히 파악
- 사용자 경험 개선
- 실제 사용자가 경험하는 문제들을 이해
- 예방적 대응
- 문제가 커지기 전에 미리 감지
- 빠른 문제 해결
Auto Scale
급작스런 부하 발생 시, 이를 처리할 수 있는 설계에 대해 고민해 볼 것.
- Scale Up
- 서버의 성능을 높이는 것
- 더 빠른 CPU, 더 큰 메모리, 더 빠른 디스크 등을 사용하는 것
- Scale Out
- 서버의 수를 늘리는 것
- 더 많은 서버를 사용하여 부하를 분산하는 것
- 클라우드 환경에서 부하 분산을 위해 자주 사용되는 방법
배포
- 무중단 배포
- 서비스를 중단하지 않고 업데이트 하는 설계
- Jenkins
- Github Actions
TDD (Test Driven Development)
- 테스트 주도 개발
- 테스트 코드를 먼저 작성하고, 테스트를 통과하는 코드를 작성하는 방식
- 유닛 테스트 (Unit Test) 의 중요성
TDD의 개념을 모른다면, “테스트 주도 개발 (켄트 벡)” (Test-Driven Development By Example - Kent Beck) 책을 읽어볼 것.
- 유닛 테스트가 탄탄하다면, 코드 신뢰도를 높이고 리팩토링에 대한 부담을 줄일 수 있다. (리팩토링으로 인한 사이드이펙트)
개발 방법론
개발 방법론과 협업에 대한 질문이 많이 나온다. (특히 협업의 경우, 사람 대 사람으로 인해 발생하는 문제가 많이 발생하기 때문에, 인문학적 지식이 많을수록 좋다.)
- 기존 개발방법론
- 폭포수 모델
- V 모델
- 프로토타입 모델
- 나선형 모델 등
- 애자일 개발 방법론 (애자일적 방법론 - Agile)
- 스크럼과 스프린트
- XP (Extreme Programming)
- 페어 프로그래밍
-
코드 리뷰에 대한 질문 (협업 관련 질문 무조건 함.)
- 코드 리뷰 어떻게 했는지?
- 협업이나 코드 리뷰 하면서 불편한 점이나 마찰이 발생할 경우 어떻게 해결했는지
- 특정인이 개발한 로직에서의 버그로 인해 “너의(Your) 잘못이야.” 라고 단정짓는 것이 아닌, “팀의(Our) 잘못.” 이라는 생각과, 재발 방지를 위한 회고 등이 필요.
- 회고 내용 예시
- 코드 리뷰나 코드 상에서의 버그를 사전에 예방할 수는 없는지.
- 방어적 프로그래밍 (방어 운전에서 따옴)
- 객체 지향 설계의 원칙 (SOLID) 과 디자인 패턴
- 사이드이펙트 발생 시: 유닛 테스트와 같은 코드 안정성 검증
- 관찰가능성, 이슈가 발생했을 때의 빠른 이슈 파악을 위한 여러 방법을 고민해볼 것.
- 특정인에게 책임을 묻지 않는 문화가 중요하다고 생각함.
- 특정인에게 책임을 묻게 되는 순간, 코드 수정이나 리팩토링에 꺼려지게 되고, 이로 인해 기술 부채가 쌓일 수 있다.
- 코드 리뷰나 코드 상에서의 버그를 사전에 예방할 수는 없는지.
- 나의 단점 (협업에서)
- 예시 답변
- 직설적으로 말함. -> 최대한 순화해서 말하려고 노력함.
- 딱딱한 표정. -> 리뷰 시 최대한 입꼬리를 올리며 웃는 상을 유지하려고 노력함.
- 예시 답변
히스토리 관리와 문서화
형상 관리 도구 (Version Control System), 특히 Git에 대한 철저한 사용법을 익힐 것.
많이 쓰이는 명령어
- git init
- git clone
- git add
- git commit
- git push
- git pull
- git fetch
- git merge
- git rebase
- git stash
- git cherry-pick
- git checkout
- git reset
- git revert
- git tag
- git branch
git remote
- Git의 로컬 저장소와 원격 저장소
- fetch와 pull의 차이
- Git의 merge와 rebase의 차이
- ff (fast-forward) 머지에 대해서도 알아볼 것
- 현재 브랜치의 HEAD가 대상 브랜치의 HEAD까지로 옮기는 merge
- 브랜치 전략이 머지 전략인가? 아니면 리베이스 전략인가? 에 따라 나뉘므로 merge와 rebase는 구분이 필요하다.
- ff (fast-forward) 머지에 대해서도 알아볼 것
- Git
- Git의 브랜치 전략 등
- release 브랜치와 develop 브랜치를 분리하여 개발
- 특정 기능 개발 시, feature 브랜치에서 개발 후, develop 브랜치로 머지
- develop 브랜치에서 테스트 후, release 브랜치로 머지
- release 브랜치와 develop 브랜치를 분리하여 개발
- Git을 통한 개발 프로세스 등
- 예시 (일반적인 개발 프로세스)
- Github의 Issue 창에 사용자가 Issue를 등록
- 개발자가 해당 tag 또는 버전에서 이슈를 재현
- 현재 최신 릴리즈 (release 브랜치) 또는 develop 버전 (develop 브랜치) 에서 이슈 재현 확인
- 이슈 재현 확인 후, 해당 이슈를 수정 (feature 브랜치)
- 수정 후 테스트하여 Pull Request를 생성해 develop 브랜치로 머지 요청
- 코드리뷰와 여러 사람의 검증 후 develop으로 최종 머지
- release 항목 산정 후 버그 또는 기능을 develop에서 release 브랜치로 머지
- 모든 작업이 완료되면, release 브랜치를 최종 배포하고 브랜치를 tag로 추가한 뒤 버전을 기입.
- 예시 (일반적인 개발 프로세스)
- Git의 브랜치 전략 등
- Github
- Github의 Issue / Pull Request (Gitlab의 Merge Request) 등
- 이슈 관리 툴
- Jira
1px은 몇 비트인가
#ffffff (255,255,255) 로 24비트 (3byte) 이다.
흑백 이미지는 0~255 로 값을 표현하기 때문에 1byte만을 필요로 한다.
jpg, png의 차이점
- png는 투명도를 표현할 수 있고, jpg는 투명도를 표현할 수 없다.
- png는 무손실 압축 방법을 사용하고, jpg는 손실 압축 방법을 사용한다. (이러한 손실 압축으로 인해 디지털 풍화가 발생할 수 있음.)
이미지 보간법이란?
이미지에 변형을 줄 때 픽셀과 픽셀 사이의 값을 채워주는 것
- 이미지의 크기를 키우거나 (리사이징) 등
- 최근접 보간법
- 주변값에 가장 가까운 값으로 채워주는 방식이다
- 이중선형보간법
- 3차원 스플라인 보간법
HTTP/2의 HPack 알고리즘에 대해 설명해보세요.
- Huffman coding(혹은 Huffman code)을 활용한다
- 무손실 압축 알고리즘으로, 심볼의 출현 빈도를 기준으로 코드를 부여해 출현 빈도 수를 가지고 압축한다.
- 따라서 HTTP의 헤더 데이터와 같이 출현 빈도가 높은 데이터는 더 짧은 코드를 부여받아 압축률이 높다.
DB의 인덱스란?
- 인덱스 (B+트리)
CREATE INDEX idx_name ON table_name (column_name1, …); CREATE UNIQUE INDEX idx_name ON table_name (column_name1, column_name2, …);
- 인덱스를 찾는 것은 B+트리와 바이너리 서치를 사용한다.
- column_name1 을 먼저 정렬해 찾고, column_name2 를 정렬해 찾는다.
- 따라서 멀티 컬럼 인덱스(multicolumn index)는 컬럼 순서를 정하는 것이 중요하다.
- 조회를 하는 것은 상당히 빠르나, B+트리를 만들고 정렬해야 하기 때문에 삽입/삭제 등에는 오버헤드가 크다.
- table에 write 할 때 마다 index도 변경 발생
- 추가적인 저장 공간 차지
- 따라서 불필요한 인덱스를 만들지 말자.
- Covering Index
- 인덱스 컬럼을 포함하는 인덱스
- 인덱스 컬럼을 포함하는 인덱스를 사용하면 조회 속도가 빠르다.
- ex ) USER 테이블에
id,name,email,phone,address컬럼이 있을 때,id,name을 인덱스로 설정했다.- 조회 시 인덱스에 설정 된
id,name컬럼을 조회할 경우, 인덱스에 있는 컬럼들로 covering이 가능하기 때문에 테이블을 참조 할 필요가 없어 조회 속도가 더 빠르다.
- 조회 시 인덱스에 설정 된
- Hash Index
- 해시 테이블을 사용해서 인덱스를 구현함
- 조회 시간복잡도가 O(1) 이라서 빠르다.
- rehashing에 대한 부담이 존재.
- rehashing 이란?
- 해시 테이블의 크기를 조정하는 것
- 데이터가 많아져 여유 공간이 줄어들수록 해시 충돌이 자주 발생하며 탐색의 효율이 떨어지므로 이를 해결할 필요가 있다. 재해싱은 이러한 문제를 해결하는 방법 중 하나로, 해시 테이블의 크기를 늘리고 늘어난 해시 테이블의 크기에 맞춰 테이블 내의 모든 데이터를 다시 해싱
- rehashing 이란?
- 해시다 보니 equality(=) 비교만 가능, range(>, <, >=, <=) 비교는 불가능하다.
- multicolumn index의 경우, attributes 에 대한 조회만 가능하다.
- Full scan이 더 좋은 경우
- table에 대한 데이터가 조금 있을 때 (몇십 몇백건 정도?)
- 조회하려는 데이터가 테이블의 상당 부분을 차지할 때
SELECT * FROM player WHERE mobile_carrier = 'SKT';- mobile_carrier 칼럼에서 SKT 데이터로 인한 출력 값이 막 100만건 이상 출력되는 등 조회 데이터가 많을 때
- order by나 group by 에도 index가 사용될 수 있다.
- foreign key에는 index가 자동으로 생성되지 않을 수 있다. (join 관련)
이미 데이터가 몇 백만건 이상 있는 테이블에 인덱스를 생성하는 경우, 시간이 몇 분 이상 소요될 수 있고 DB 성능에 안좋은 영향을 끼칠 수 있다.
- 인덱스는 기본적으로 RDBMS Optimizer(RDBMS마다 다를 수 있음.)가 기본적으로 알맞게 지정해서 사용한다.
- 인덱스 권장
SELECT * FROM player USE INDEX (idx_name) WHERE column_name1 = 'value1' AND column_name2 = 'value2';
- 인덱스 반강제 (사용하지 못할 경우에는 사용 안함.)
SELECT * FROM player FORCE INDEX (idx_name) WHERE column_name1 = 'value1' AND column_name2 = 'value2';
- 인덱스 제외
SELECT * FROM player IGNORE INDEX (idx_name) WHERE column_name1 = 'value1' AND column_name2 = 'value2';
- select, join
- 쿼리 최적화 / 쿼리 튜닝
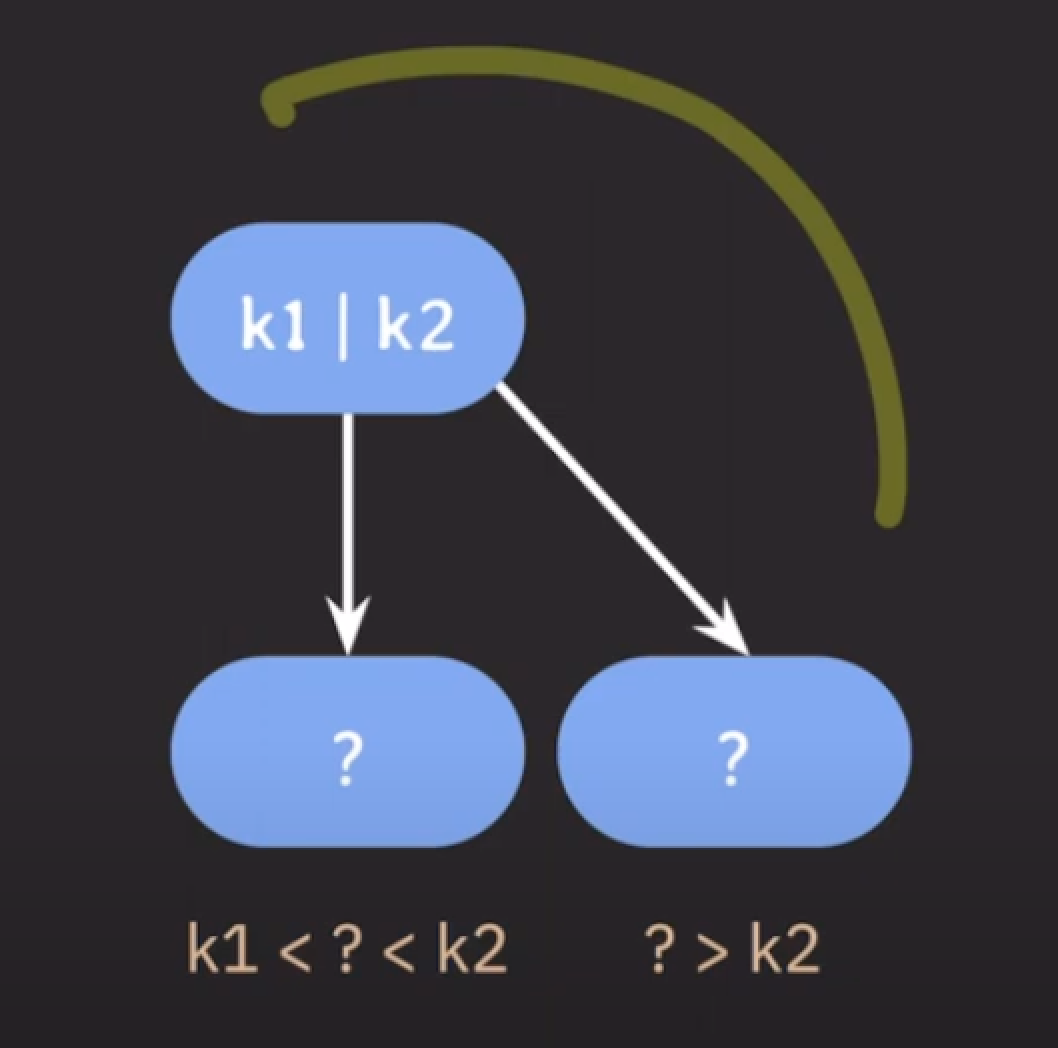
B Tree / B+ Tree
- 이진 탐색 트리 : 왼쪽은 부모 노드보다 작은 값을, 오른쪽은 부모 노드보다 큰 값을 가진다.
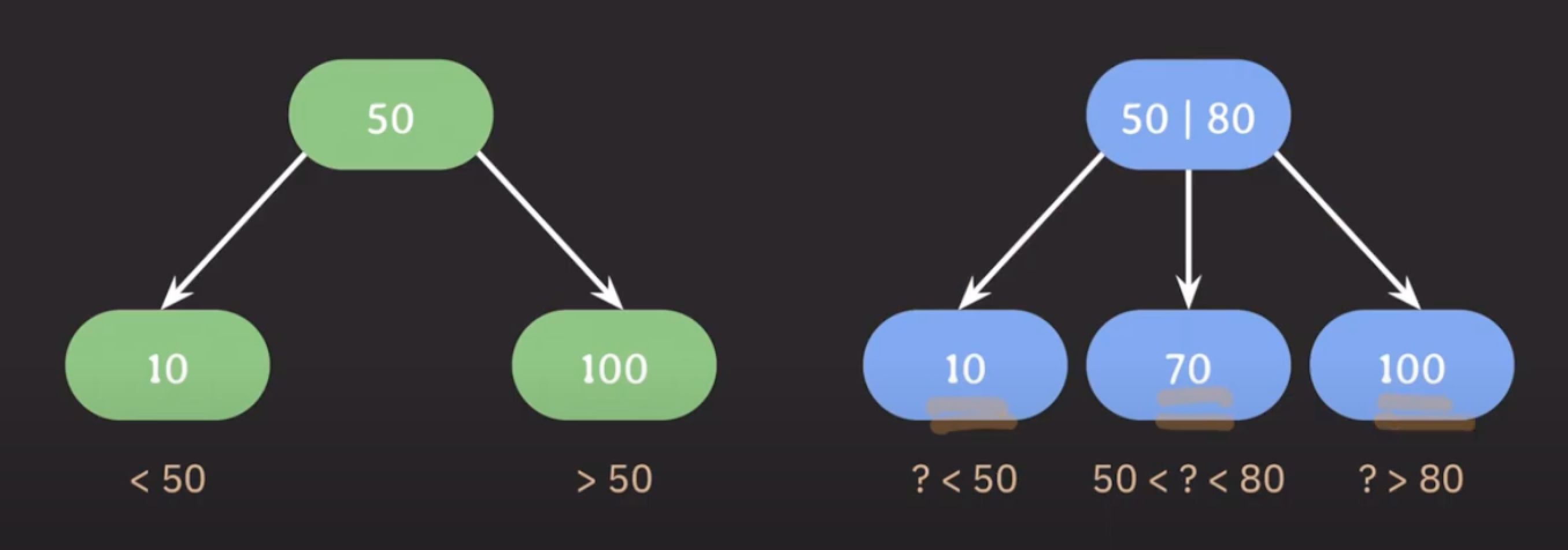
- B Tree는 이진 탐색 트리의 확장판이다.
- 자녀 노드의 최대 개수를 늘리기 위해서 부모 노드에 key를 하나 이상 저장한다.
- 부모 노드의 key들을 오름차순으로 정렬한다.
- 정렬된 순서에 따라 자녀 노드들의 key 값의 범위가 결정된다.
-> 이런 방식을 사용하면 자녀 노드의 최대 개수를 입맛에 맞게 결정해서 쓸 수 있다 -> B Tree 는 BST를 일반화한 트리!
- 최대 몇 개의 자녀 노드를 가질 것인지가 B tree를 사용할 때 중요한 파라미터
-
M: 각 노드의 최대 자녀 수- 최대
M개의 자녀 노드를 가질 수 있는 B tree를M차 B tree라고 한다.
- 최대
-
M-1: 각 노드의 최대 key 수-
M값이 결정되면 자동으로 결정되는 값
-
-
⌈M/2⌉: 각 노드의 최소 자녀 수 (홀수가 나올 경우 값을 올림)- 루트(root), 리프(leaf) 노드는 제외된다.
-
⌈M/2⌉-1: 각 노드의 최소 key 수- 루트(root) 노드는 제외됨.
-
이 방식은 불가능하다.
- internal node의 key 수가 x개라면, 자녀 노드의 수는 언제나 x+1개 이다.
- 노드가 최소 하나의 key는 가지기 때문에 몇 차 B tree 인지와 상관없이 internal 노드는 최소 두 개의 자녀는 가진다.
-
M이 정해지면 root 노드를 제외하고 internal 노드는 최소⌈M/2⌉개의 자녀 노드를 가질 수 있게 된다.
-
B Tree 데이터 삽입
- 추가는 항상 리프(leaf) 노드에서 이루어진다.
- 노드가 넘치면 가운데(median) key를 기준으로 좌우 key들은 분할하고, 가운데 key는 승진한다. (부모 노드로 옮긴다.)
-
https://www.youtube.com/watch?v=bqkcoSm_rCs
17:00참고 - 모든 리프 노드들은 같은 레벨에 있다. (B Tree의 특징)
- B Tree는 Balanced Tree (자가 균형 트리) 이다.
- 검색 avg/worst case
O(logN)
- B Tree (B+ Tree, B* Tree)
- avg/worst case에 대해 조회/삽입/삭제 모두
O(logN)을 보장한다.
- avg/worst case에 대해 조회/삽입/삭제 모두
- self-balancing BST
- 하지만 self-balanceing BST 또한 시간 복잡도가 B Tree와 같다.
- AVL Tree
- avg/worst =
O(logN)
- avg/worst =
- Red-Black Tree
- avg/worst =
O(logN)
- avg/worst =
- RAM : 평균 속도 40~50GB/s
- SSD : 3 ~ 5GB/s
HDD : 0.2~0.3GB/s
- Secondary Storage
- Block 단위로 데이터를 읽고 쓴다.
- 불필요한 데이터까지 읽어올 가능성이 있다.
- Block 단위로 데이터를 읽고 쓴다.
- DB에서 데이터를 조회할 때, Secondary Storage에 최대한 적게 접근하는 것이 성능 면에서 좋다.
- Block 단위로 읽고 쓰기 때문에 연관된 데이터를 모아서 저장하면 더 효율적으로 읽고 쓸 수 있다.
BTree는 데이터(key)를 모아서(연관되어) 저장하기 때문에 데이터를 조회할 때 더 효율적으로 읽을 수 있다.
- 101차 B Tree의 경우 네 게의 level 만으로 수백만, 수천만 개의 데이터를 저장할 수 있다.
- root 노드에서 가장 멀리 있는 데이터도 세 번의 이동만으로 접근할 수 있다.
- DB는 기본적으로 secondary storage에 저장된다.
- B tree index는 self-balancing BST 에 비해 secondary storage에 접근하는 횟수가 적다.
B tree 노드는 block 단위의 저장 공간을 알차게 사용할 수 있다.
- hash index는 삽입/삭제/조회의 시간 복잡도가 O(1) 이지만 equality(=) 조회만 가능하고, 범위 기반 검색이나 정렬에는 사용될 수 없다는 단점이 있다.
정규화
- 데이터 중복과 isertion, update, deletion anomaly를 최소화하기 위해 일련의 normal forms (NF)에 따라 relational DB를 구성하는 과정
Normal Forms
정규화되기 위해 준수해야 하는 몇 가지 rule들이 있는데 이 각각의 rule을 normal form(NF) 이라고 부른다.
- FD와 key 만으로 정의되는 normal forms
- 3NF 까지 도달하면 정규화 되었다고 말하기도 함.
보통 실무에서는 3NF 혹은 BCNF 까지 진행 (많이 해도 4NF 정도까지만 진행)
- super key : 테이블에서 tuple들을 unique 하게 식별할 수 있는 attributes set
- (candidate) key : 어느 한 attribute 라도 제거하면 unique 하게 tuples를 식별할 수 없는 super key
- {account_id} - 슈퍼키, {bank_name, account_num} - 후보키이면서 슈퍼키
- primary key : table에서 tuple들을 unique 하게 식별하려고 선택된 (candidate) key
- {account_id}
- prime attribute : 임의의 key에 속하는 attribute
- account_id, bank_name, account_num
- non-prime attribute : 어떠한 key에도 속하지 않는 attribute
정규화 과정
도부이결다조
- 제 1 정규화
- 도메인을 원자값으로
- 제 2 졍규화
- 부분 종속을 제거
- 기본 키 중 일부 키에만 종속되는 값이 없어야 한다.
- 제1 정규형을 만족한 테이블에 대해서 완전 함수 종속을 만족하도록 테이블을 분리하는 것
- 부분 종속을 제거
- 제 3 정규화
- 이행 종속을 제거
- 이행적 종속이란 A->B, B->C가 성립할 때 A->C가 성립되는 것을 의미한다.
- 제2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분해하는 것이다.
- 이행 종속을 제거
- BCNF
- 모든 결정자가 후보키가 되도록 테이블을 분리
- 결정자가 후보키가 아닌 함수 종속을 제거한다.
- 모든 결정자가 후보키가 되도록 테이블을 분리
- 제 4 정규화
- 다중 값(다치) 종속을 제거
- 다치 종속이란?
- 같은 테이블 내의 독립적인 두 개 이상의 컬럼이 또 다른 컬럼에 종속되는 것을 말한다.
- 즉, A → B 인 의존성에서 단일 값 A와 다중 값 B가 존재한다면 다치 종속이라고 할 수 있다. 이러한 종속을 A ↠ B 로 표기한다. (다치 종속은 이중 화살표(double arrow) ↠ 로 표기한다.)
- 다치 종속은 최소 2개의 컬럼이 다른 컬럼에 종속되어야 하기 때문에 최소 3개의 컬럼이 필요하다.
- 다치 종속이란?
- 다중 값(다치) 종속을 제거
- 제 5 정규화
- 조인 종속을 제거
- 조인 종속이란?
- 하나의 릴레이션을 여러개의 릴레이션으로 분해하였다가, 다시 조인했을 때 데이터 손실이 없고 필요없는 데이터가 생기는 것을 말한다.
- 조인 종속성은 다치 종속의 개념을 더 일반화한 것이다.
- 더 이상 비손실 분해를 할 수 없어야 한다.
- 조인 종속이란?
- 조인 종속을 제거
제 6 정규화
- 반정규화
- 데이터베이스의 성능 향상을 위하여, 데이터 중복을 허용하고 조인을 줄이는 데이터베이스 성능 향상 방법
DBCP (DataBase Connection Pool - 커넥션 풀)
- 일반적으로 DB의 내용이 필요할 때 마다 TCP 커넥션을 맺고 끊으면 비용이 많이 든다.
- 3way handshake / 4way handshake 등, 매번 커넥션을 열고 닫는 과정을 거쳐야 하기 때문이다.
- 따라서 커넥션을 미리 맺어두고 필요할 때 마다 사용하여 이러한 비용을 줄일 수 있다.
- connection을 재사용하여 열고 닫는 시간을 절약시킬 수 있다.
- 이를 DataBase Connection Pool이라고 부른다.
- 아래 설명되는 내용은 Spring Boot의 HikariCP, Mysql 의 예시를 설명한다.
- DB Connection은 backend server와 DB server 사이의 연결을 의미하기 때문에, backend server와 DB 서버 각각에서의 설정(configure) 방법을 잘 알고 있어야 한다.
- MySQL에서는 중요한 두가지 파라메터가 있다.
- max_connections
- client와 맺을 수 있는 최대 커넥션 수
- 만약 max_connection 수가 4, DBCP의 최대 커넥션 수가 4라면?
- MSA에서, 만약 웹서버를 증설시킬 경우, 새로운 웹서버는 DB와 커넥션을 맺을 수 없다.
- (이미 기존 서버가 4개의 커넥션을 맺었기 때문에)
- wait_timeout
- connection이 inactive 할 때, 다시 요청이 오기까지 얼마의 시간을 기다린 뒤에 close 할 것인지를 결정하는 파라메터
- 비정상적인 상황을 방지하기 위해 사용된다.
- 비정상적인 connection 종료
- connnection을 다 쓰고 반환이 되지 않는 경우 (릭)
- 네트워크 단절
- 비정상적인 상황을 방지하기 위해 사용된다.
- connection이 inactive 할 때, 다시 요청이 오기까지 얼마의 시간을 기다린 뒤에 close 할 것인지를 결정하는 파라메터
- max_connections
- DBCP 설정 (HikariCP)
- minimumIdle과 maximumPoolSize는 값이 동일함.
- 그리고 이 값을 동일하게 설정하는 것을 권장함.
- 그 말인 즉슨, 커넥션 갯수를 고정하는 것이다.
- 커넥션을 맺는 것 자체가 시간과 비용이 걸리므로, 트래픽이 몰려올 때에서야 커넥션을 추가로 맺게 되면 비용이 발생할 수 있어 서버가 빠르게 대응하지 못할 수 있다.
- 그리고 이 값을 동일하게 설정하는 것을 권장함.
- minimumIdle
- pool에서 유지하는 최소한의 idle connection 수
- idle connection 수가 minimumIdle 보다 작고, 전체 connection 수도 maximumPoolSize 보다 작으면 신속하게 추가로 connection을 맺는다.
- maximumPoolSize
- pool이 가질 수 있는 최대 connection 수
- idle(유휴, 노는 커넥션)과 active(in-use) connection 합쳐서 최대 수
- maximumPoolSize가 minimumIdle 값 보다 우선순위가 높다.
- maxLifetime
- pool에서 connection의 최대 수명
- maxLifetime을 넘기면 idle일 경우 pool에서 바로 제거
- active인 경우 pool로 반환된 후 제거
- pool로 반환이 안되면, maxLifetime 동작 안함.
- 다 사용한 connection은 pool로 반환을 잘 시켜주는 것이 중요하다!
- DB의 connection time limit 보다 몇 초 짧게 설정해야 한다.
- 만약, DB의 wait_timeout이 60초, DBCP의 maxLifetime이 60초라면?
- 타이밍적인 이슈로 인해 서버와 DB가 통신하는 사이 커넥션이 끊어질 수 있다.
- 따라서 안전하게 maxLifetime을 몇 초 짧게 설정해야 한다.
- 만약, DB의 wait_timeout이 60초, DBCP의 maxLifetime이 60초라면?
- connectionTimeout
- pool에서 connection을 받기 위한 대기시간
- 만약 connectionTimeout이 30초라면?
- 부하가 발생하여 모든 커넥션을 사용한 상황에서 30초까지 대기하게 된다.
- 30초를 넘으면 timeout exception을 발생시킨다.
- 부하가 발생하여 모든 커넥션을 사용한 상황에서 30초까지 대기하게 된다.
- 일반적인 사용자로부터 오는 요청의 경우 30초도 너무 길다. (일반 사용자는 3~5초 대기하다가, 응답이 오지 않으면 새로고침하거나 나가는 등의 행동을 하기 때문.)
- 즉 connectionTimeout을 몇 초 정도로 줄 것인지 잘 생각해 보아야 한다.
- minimumIdle과 maximumPoolSize는 값이 동일함.
적절한 connection 수를 찾기 위한 과정
- 모니터링 환경 구축 (서버 리소스, 서버 스레드 수, DBCP 등등)
- 백엔드 시스템 부하 테스트
- nGrinder
- request per second, avg response time 확인
- RPS가 늘어나다가 어느 순간부터는 늘어나지 않음.
- ARPT도 똑같음.
- 이후 응답 시간이 계속 늘어남.
- 백엔드 서버, DB 서버의 CPU, MEM 등등 리소스 사용률 확인
- cpu, mem 등의 사용률이 급격히 치솟으면 웹서버 증설이 필요
- db 서버의 cpu, mem 사용률이 높으면?
- select 쿼리가 많을 경우 secondary 추가
- cache layer 추가
- sharding 추가 등등
- db 서버의 cpu mem 사용률도 높지 않은데… 응답 시간이 늘어난다면?
- thread per request 모델이라면 active thread 수 확인!
- 스레드 카운트가 너무 없어서 발생하는 문제일 수도 있음!
- thread pool 이 100개 인데 active thread 수가 50개면? 이것도 문제 없다.
- DBCP의 active connection 수를 확인
- maximumPoolSize 를 늘려서 확인
db의 max_connections 수도 늘려서 적절히 확인
- 사용할 백엔드 서버 수를 고려하여 DBCP의 max pool size를 결정
- 적당히 여유분이 있는 수치로 설정하는 것이 좋을듯
파티셔닝, 샤딩, 레플리케이션
https://youtu.be/P7LqaEO-nGU?si=uJeWNKBX2oGWek9P
파티셔닝
- database table을 더 작은 table들로 나누는 것
- table을 목적에 따라 작은 table들로 나누는 방식
- vertical partitioning (수직 분할)
- 컬럼(column)을 기준으로 나누는 것
- 정규화도 어떻게 보면 수직 분할 (vertical partitioning) 으로 볼 수 있다.
- ex ) 게시글에서 content(본문, 게시글 내용)의 경우 데이터가 많은데, 이를 따로 빼서 저장하는 것이다.
- 게시글을 게시글정보 테이블에 함께 저장할 경우, 인덱스 등을 사용하지 않고 Full Scan할 경우 유의미한 성능 저하가 발생할 수 있다.
- 테이블 조회 시, select로 특정 정보만 내가 가져오는 경우에도, 테이블의 모든 정보를 io에서 불러오기 때문이다.
- 이 경우, 게시글정보와 본문 정보를 따로 저장하여 수직분할 하는 것이 좋다.
- 그 외에도 민감한 정보 등을 따로 저장할 때 테이블을 분리하여 virtical partitioning을 사용한다.
- horizontal partitioning (수평 분할, 샤딩이랑 비슷함 - 그럼 샤딩은 왜함?)
- 레코드(row)를 기준으로 나누는 것
- hash function을 사용해서 레코드를 분할시킬 수 있다.
- ex ) 구독 서비스 정보를 저장할 때, 몇억, 몇십억 건의 데이터를 저장할 경우
- subscription_0, subscription_1, subscription_2, … 로 테이블을 분리하여 저장하는 것이다.
- 이 때 어떤 테이블에 저장될지를 hash function을 사용해서 결정한다.
- 가장 많이 사용될 패턴에 따라 partition key를 정하는 것이 중요하다.
- 데이터가 균등하게 분배될 수 있도록 hash function을 잘 정의하는 것도 중요하다.
- row 를 나누는 종류에는 여러가지 방법이 있을 수 있다.
- hash based
- range based
- 그 외…
Sharding (샤딩)
horizontal partitioning으로 나누어진 table들을 각각의 DB 서버에 저장하는 방식
- horizontal partitioning 처럼 동작함.
- 그러나, 각 partition이 독립된 DB 서버에 저장된다.
- 수평적 분할과 달리 다른 DB에 저장함으로서, 부하 분산을 시킬 수 있다.
- 부하 분산이 목적
- partiton key를 shard key라고 부름.
- 각 파티션(partition)을 shard라고 부름.
replication
DB를 복제해서 여러 대의 DB 서버에 저장하는 방식
- 기존 데이터베이스의 정보를 copy하여 다른 DB 서버에 저장하는 것
- 저장되는 서버를 (slave/secondary/replica) 라고 부름
- 고가용성을 위해 사용됨
- 기존 database가 장애가 생기면 빠르게 replica된 database를 사용할 수 있도록 하는 것이다.
- (fail over) 이중화 방식
- 고가용성 (High Availability - HA)
- 고가용성 뿐만 아니라, DB에 가중되는 부하를 분산시키는 목적으로도 사용된다.
- SELECT 와 같은 read only 쿼리는 replica DB에서 처리할 수 있지만,
- write 트래픽이 많은 경우 replica를 통한 부하 분산은 효과적이지 않다.
- 이 경우, multi-master, sharding 과 같은 방법을 사용할 수 있음.
- replication의 copy 방식에는 여러 방식이 존재한다.
Database Transaction
Transaction
- 단일한 논리적인 작업 단위 (a single logical unit of work)
- 논리적인 이유로 여러 SQL 문들을 단일 작업으로 묶어서 나눠질 수 없게 만든 것이 transaction
- transaction의 SQL 문들 중에 일부만 성공해서 DB에 반영되는 일은 일어나면 안된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
CREATE TABLE account (
...,
balance INT,
check (balance >= 0)
);
START TRANSACTION;
UPDATE account SET balance = balance - 200000 WHERE id = 'J';
UPDATE account SET balance = balance + 200000 WHERE id = 'H';
COMMIT;
-- 지금까지 작업한 내용을 DB에 영구적으로 (permanently) 저장하라.
-- transaction을 종료한다.
START TRANSACTION;
UPDATE account SET balance = balance - 200000 WHERE id = 'J';
ROLLBACK;
-- 지금까지 작업들을 모두 취소하고 transaction 이전 상태로 되돌린다.
-- transaction을 종료한다.
-- 각각의 SQL문을 자동으로 transaction 처리해주는 개념
-- SQL문이 성공적으로 실행하면 자동으로 commit 된다.
-- 실행 중에 문제가 있었다면 알아서 rollback 된다.
-- MySQL에서는 default로 auto commit이 켜져있다.
-- 다른 DBMS에서도 대부분 같은 기능을 제공한다.
SELECT @@AUTOCOMMIT; -- 현재 auto commit 상태를 확인할 수 있다.
SET autocommit = 0; -- auto commit을 끈다.
DELETE FROM account WHERE balance <= 1000000;
ROLLBACK;
-- AUTO COMMIT이 비활성화 되었기 때문에 DELETE가 롤백된다.
-- 따라서 이 경우 COMMIT 명령어를 명시적으로 호출해야 한다.
- ACID
- Atomicity (원자성)
- 트랜잭션이 모두 완료되거나 완료되지 않아야 함.
- ALL or NOTHING
- transaction은 논리적으로 쪼개질 수 없는 작업 단위이기 때문에 내부의 SQL 문들이 모두 성공해야 한다.
- 중간에 SQL문이 실패하면, 지금까지의 작업을 모두 취소하여 아무 일도 없었던 것처럼 rollback 해야 한다.
- commit 실행 시, DB에 영구적으로 저장하는 것은 DBMS가 담당하는 부분이다.
- rollback 실행 시 이전 상태로 되돌리는 것도 DBMS가 담당하는 부분이다.
- 개발자는 언제 commit 하거나 rollback 할지를 결정해야 한다.
- Consistency (일관성)
- 데이터의 일관성을 보장
- transaction은 DB상태를 consist 상태에서 또 다른 consist 상태로 바꿔줘야 한다.
- constrains, trigger 등을 통해 정의된 rule을 transaction이 위반했다면 rollback 해야 한다.
- transaction이 DB에 정의된 rule을 위반했는지는 DBMS가 commit 하기 전에 확인하고 알려준다.
- 그 외에 application 관점에서 transaction이 consistent 하게 동작하는지는 개발자가 챙겨야 한다.
- Isolation (독립성)
- 여러 트랜잭션이 동시에 처리될 때에도 독립성을 보장
- 여러 transaction들이 동시에 실행될 때에도 혼자 실행되는 것처럼 동작하게 만든다.
- DBMS는 여러 종류의 isolation level을 제공한다.
- 개발자는 isolation level 중에 어떤 level로 transaction을 동작시킬지 설정할 수 있다.
- isolation level이 낮을 경우 동시에 여러 transaction이 실행될 수 있지만, 동시성 문제가 발생할 가능성이 높아짐.
- 개발자는 isolation level 중에 어떤 level로 transaction을 동작시킬 지 설정할 수 있다.
- concurrency control의 주된 목표가 isolation이다.
- Durability (지속성, 영존성)
- DB 서버에 문제가 발생했을 때에도 commit 된 데이터는 손실되지 않는 지속성
- commit된 transaction은 DB에 영구적으로 저장되어야 한다.
- 즉, DB system에 문제 (power fail, DB crash 등)가 생겨도 commit된 transaction은 DB에 남아 있어야 한다.
- 영구적으로 저장한다 라고 할 때에는 일반적으로 ‘비휘발성 메모리(HDD, SSD…)에 저장함’을 의미한다.
- 기본적으로 transaction의 durability는 DBMS가 보장한다.
- Atomicity (원자성)
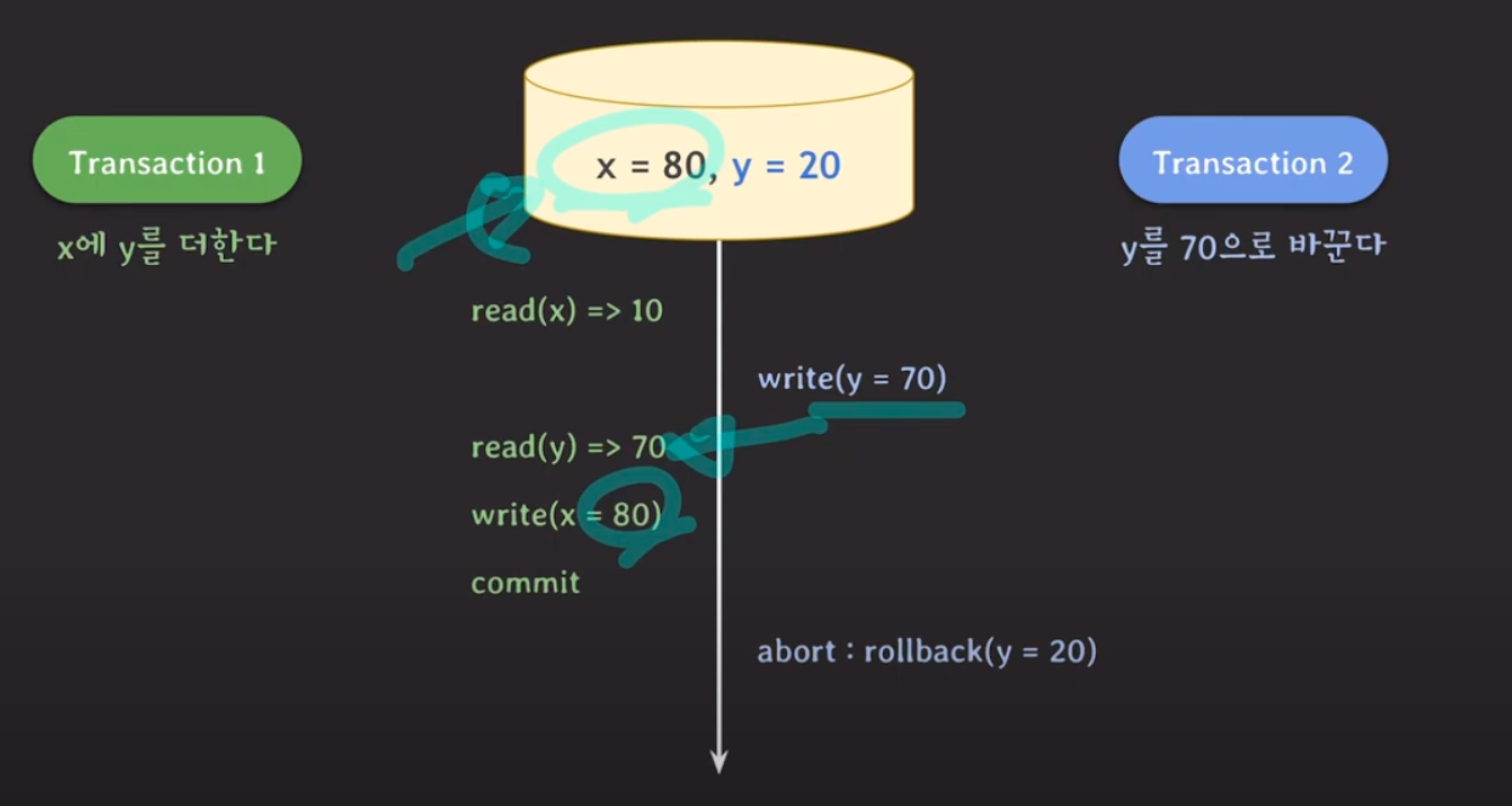
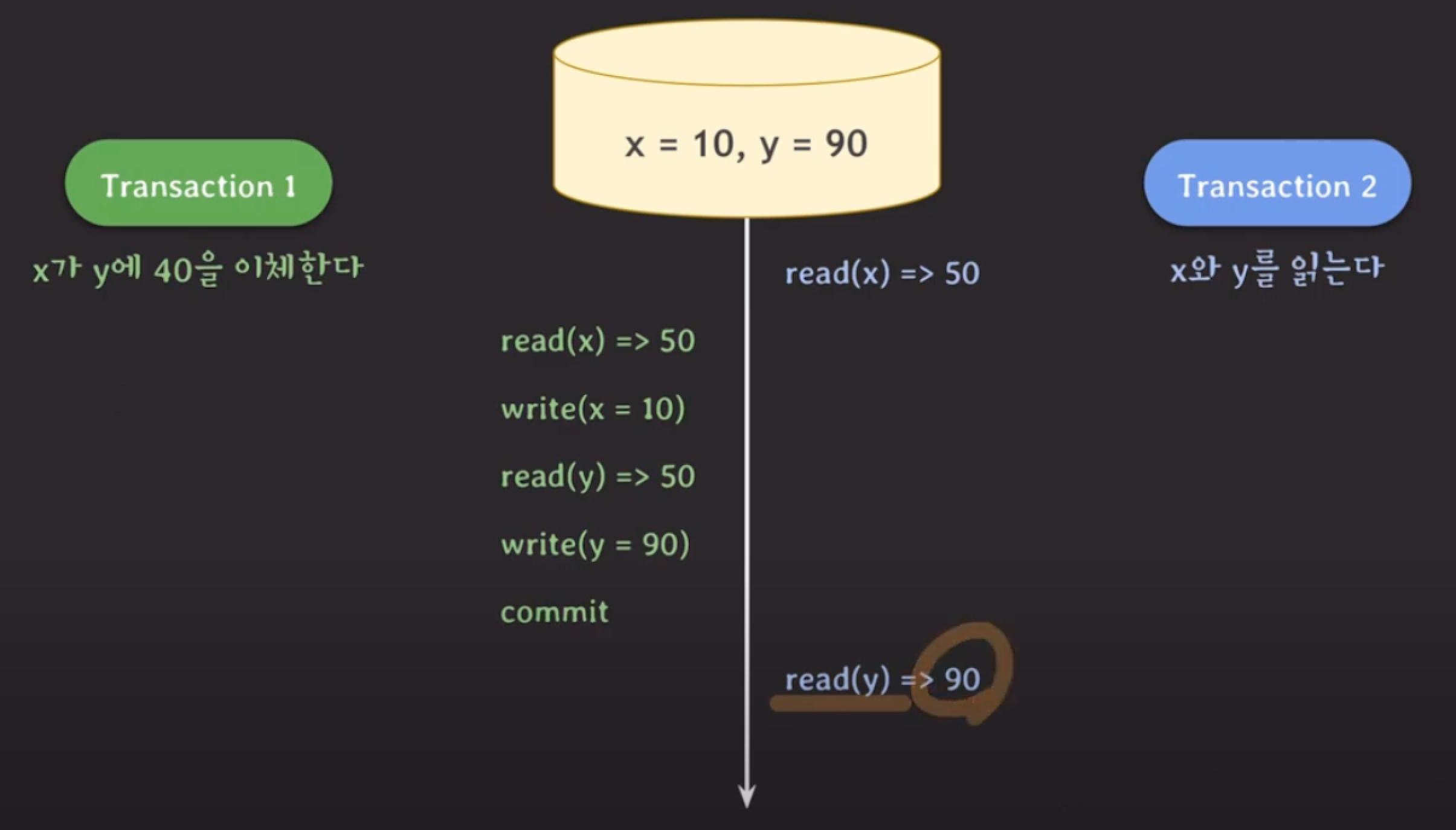
Isolation이 되지 않을 때 발생할 수 있는 문제
- dirty read
- 커밋되지 않은 변화를 읽었을 때
- y는 20으로 롤백되었으므로 x의 값이 롤백전 값, 10이 되어야 하나 80이 유지되고 있다.
- non-repeatable read (Fuzzy Read)
- 같은 데이터의 값을 두 번 읽었을 때, 값이 다르게 나오는 경우
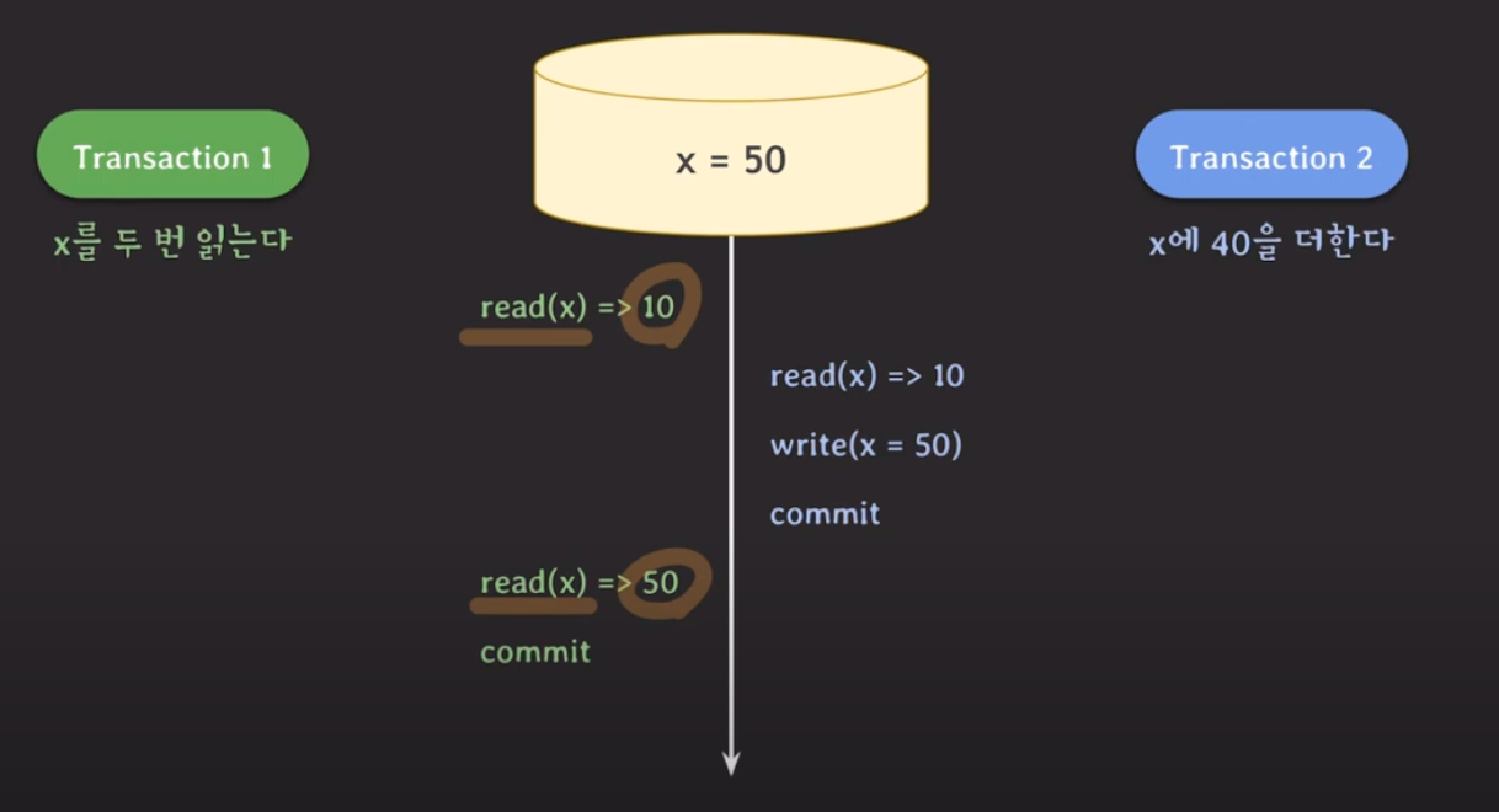
- 같은 데이터의 값을 두 번 읽었을 때, 값이 다르게 나오는 경우
- phantom read
- 없던 데이터가 생김.
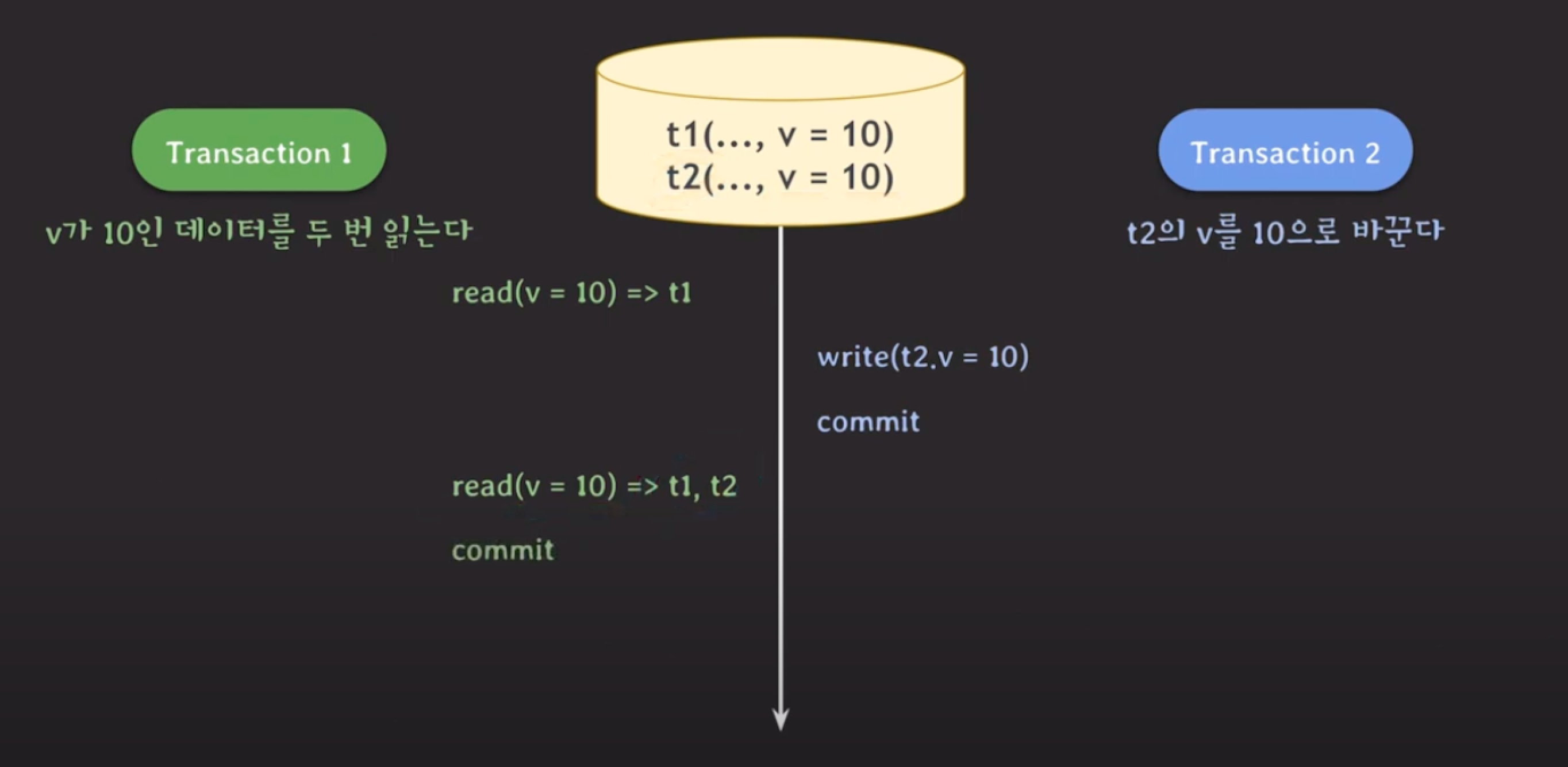
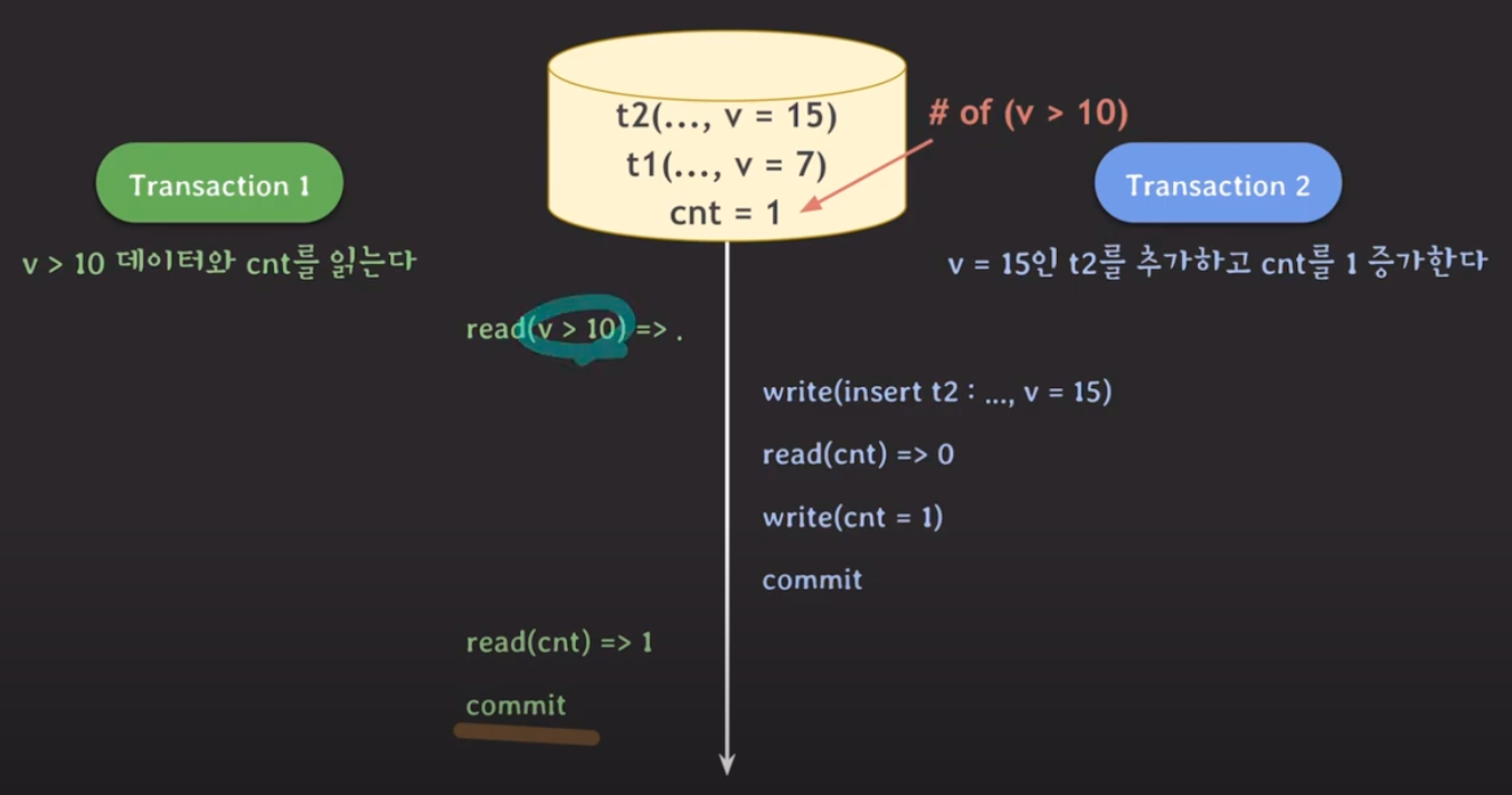
- 없던 데이터가 생김.
이런 이상한 현상들이 모두 발생하지 않게 만들 수 있지만, 그러면 제약 사항이 많아져서 동시 처리 가능한 트랜잭션의 수가 줄어들어 결국 DB의 전체 처리량(throughput)이 떨어진다.
- 일부 이상한 현상은 허용하는 몇 가지 level을 만들어서 사용자가 필요에 따라서 적절하게 선택할 수 있도록 하자.
Isolation Level
애플리케이션 설계자는 isolation level을 통해 전체 처리량 (throughput)과 데이터 일관성 사이의 어느정도 거래(trade)를 할 수 있다.
- Read Uncommitted (커밋되지 않은 데이터도 읽음)
- Dirty Read (O)
- Non-Repeatable Read (O)
- Phantom Read (O)
- Read Committed (커밋된 데이터만 읽음)
- Dirty Read (X)
- Non-Repeatable Read (O)
- Phantom Read (O)
- Repeatable Read (반복 읽기)
- Dirty Read (X)
- Non-Repeatable Read (X)
- Phantom Read (O)
- Serializable (직렬화)
- 아예 이상한 현상 자체가 발생하지 않는 level을 의미함!
- Dirty Read (X)
- Non-Repeatable Read (X)
- Phantom Read (X)
그 외에도 여러 이상한 현상들이 있음.
- dirty write
- commit이 되지 않은 데이터를 write할 때 발생할 수 있음.
- Rollback 할 때 문제 발생
- Rollback 시 정상적인 recovery는 매우 중요하기 때문에, 모든 isolation level에서 dirty write를 허용하면 안 된다.
- commit이 되지 않은 데이터를 write할 때 발생할 수 있음.
- lost update
- 업데이트를 덮어 쓸 때 발생할 수 있음.
- 두 개의 transaction이 같은 데이터를 동시에 수정하는 경우, 한 개의 transaction 변화가 소실되는 경우
- dirty read 확장판
- commit 되지 않은 변화를 읽음!
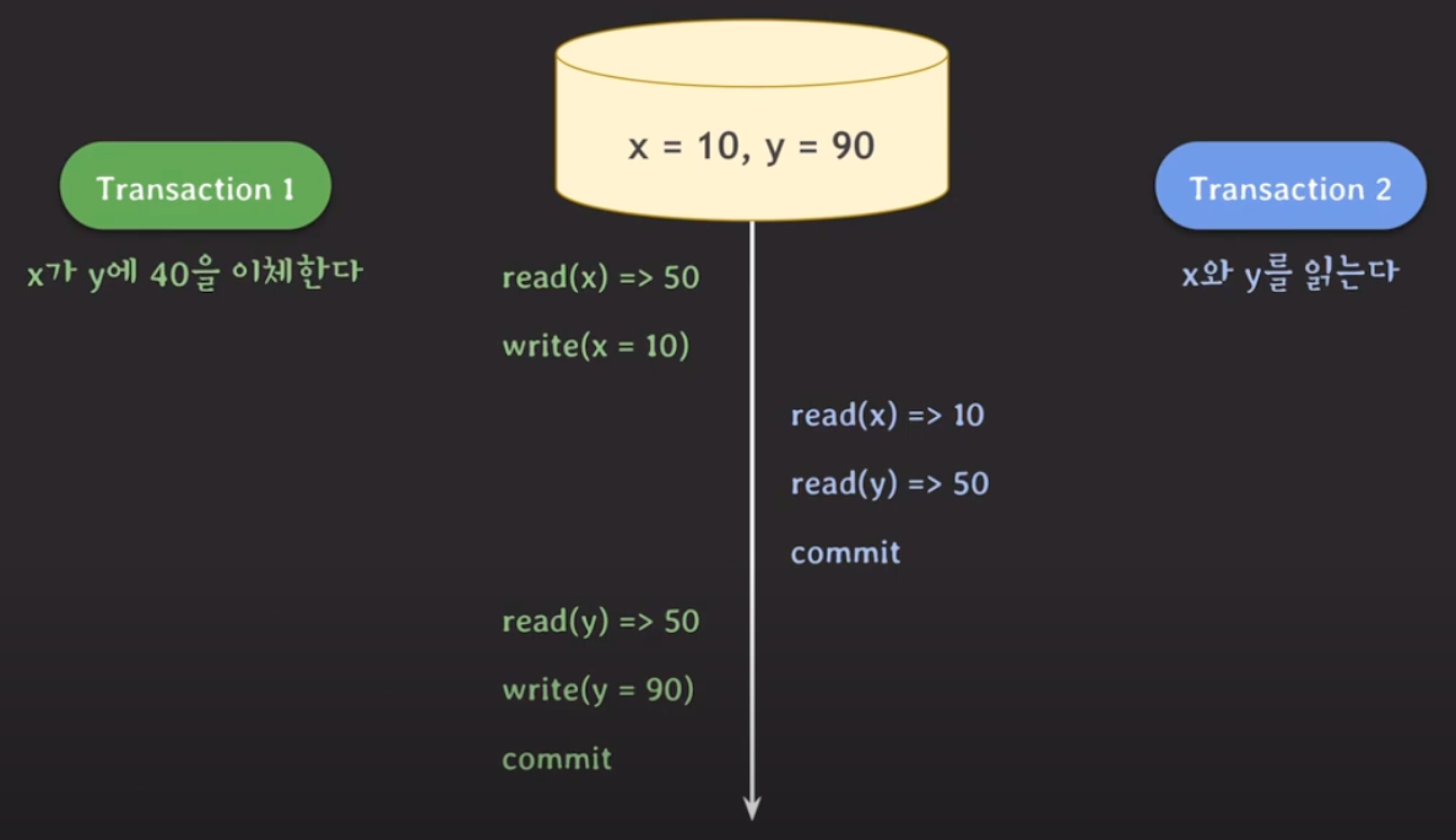
- commit 되지 않은 변화를 읽음!
- read skew
- inconsistent한 데이터 읽기!
- non-repeatable read 와 비슷함
- y가 x였다면 non-repeatable read 였을 것이다.
- write skew
- inconsistent 한 데이터 쓰기!

- inconsistent 한 데이터 쓰기!
SNAPSHOT ISOLATION
- concurrency control 을 어떻게 진행할 것인지에 따라 레벨을 결정함.
write lock (exclusive lock)
- read / write (insert, modify, delete) 할 때 사용한다.
- 다른 tx가 같은 데이터를 read / write 하는 것을 허용하지 않는다.
read lock (shared lock)
- read 할 때 사용한다.
- 다른 tx가 같은 데이터를 read 하는 것을 허용한다.
2PL (Two-Phase Locking)
- tx에서 모든 locking operation이 최초의 unlock operation 보다 먼저 수행되도록 하는 것
RDBMS(Relation DataBase Management System) vs NoSQL (mongodb, redis)
- RDBMS의 단점
- 데이터 타입 변경에 따른 칼럼 추가/삭제 등 빠른 대응이 어렵다.
- 이미 데이터가 많이 있는 상황에서 스키마 변경 또는 칼럼을 추가/삭제는 부담이 된다.
- 유연한 확장성 부족
- 중복 제거를 위해 정규화를 진행하면, JOIN 쿼리가 많이 발생할 수 있다.
- 복잡한 JOIN 쿼리는 성능 저하를 일으킬 수 있다.
- RDBMS는 일반적으로 scale-out에 유연한 DB는 아니다.
- ACID를 보장하려다보니 DB 서버의 performance에 어느 정도 영향을 미침
- 데이터 타입 변경에 따른 칼럼 추가/삭제 등 빠른 대응이 어렵다.
- high throughput과 low-latency를 요구함.
- 비정형 데이터의 증가
Not Only Structured Query Language (NoSQL)
특징
- Flexible schema (유연한 스키마)
- MongoDB는 json 형태로 정보를 넣어준다.
- 스키마를 사전에 정의하지 않아도 된다.
- MongoDB는 row, tuple이 아닌, document 라고 부른다.
- MongoDB는 각 document에 대한 _id 를 자동으로 생성해준다.
- 중복을 허용한다. (join 회피)
- application 레벨에서 중복된 데이터들이 모두 최신 데이터를 유지할 수 있도록 관리해야 한다.
- scale-out에 최적화되어 있다.
- 서버 여러 대로 하나의 클러스터를 구성하여 사용함.
- 각각의 서버가 데이터를 나누어서 저장함.
- ACID이 일부를 포기하고 high throughput과 low-latency를 추구
- 금융 시스템처럼 consistency가 중요한 환경에서는 사용하기가 조심스러움.
- REDIS
- in-memory key-value database, cache or …
- data type: string, lists, sets, hashes, sorted sets, …
- hash-based sharded cluster
- High Availability (replication, automatic failover)
데이터 백업
jpa n + 1 문제
jpa n + 1 문제 n+1 관계 설정 및 관계가 설정된 데이터를 조회하려 할 때, 조회 쿼리가 n번 발생하는 문제이다.
동기와 비동기, Blocking과 Non-Blocking 의 차이점
Blocking은 함수의 제어권을 담당하는 여부
- Blocking IO
- 제어권은 호출한 함수에 넘겨줌
- Non-Blocking IO
- 제어권은 호출한 함수에 넘겨주지 않음
sync는 호출되는 함수의 작업 완료를 기다리는 여부
- sync
- 호출되는 함수의 리턴값을 확인(기다림)
- async
- 호출되는 함수의 리턴값을 기다리지 않음. (대신 콜백 함수를 함께 전달해 함수 B의 작업이 끝나면 콜백 함수를 실행함)
- Blocking / Synchronous
- 일반적인 함수의 동작 과정
-
Synchronous / Non-Blocking
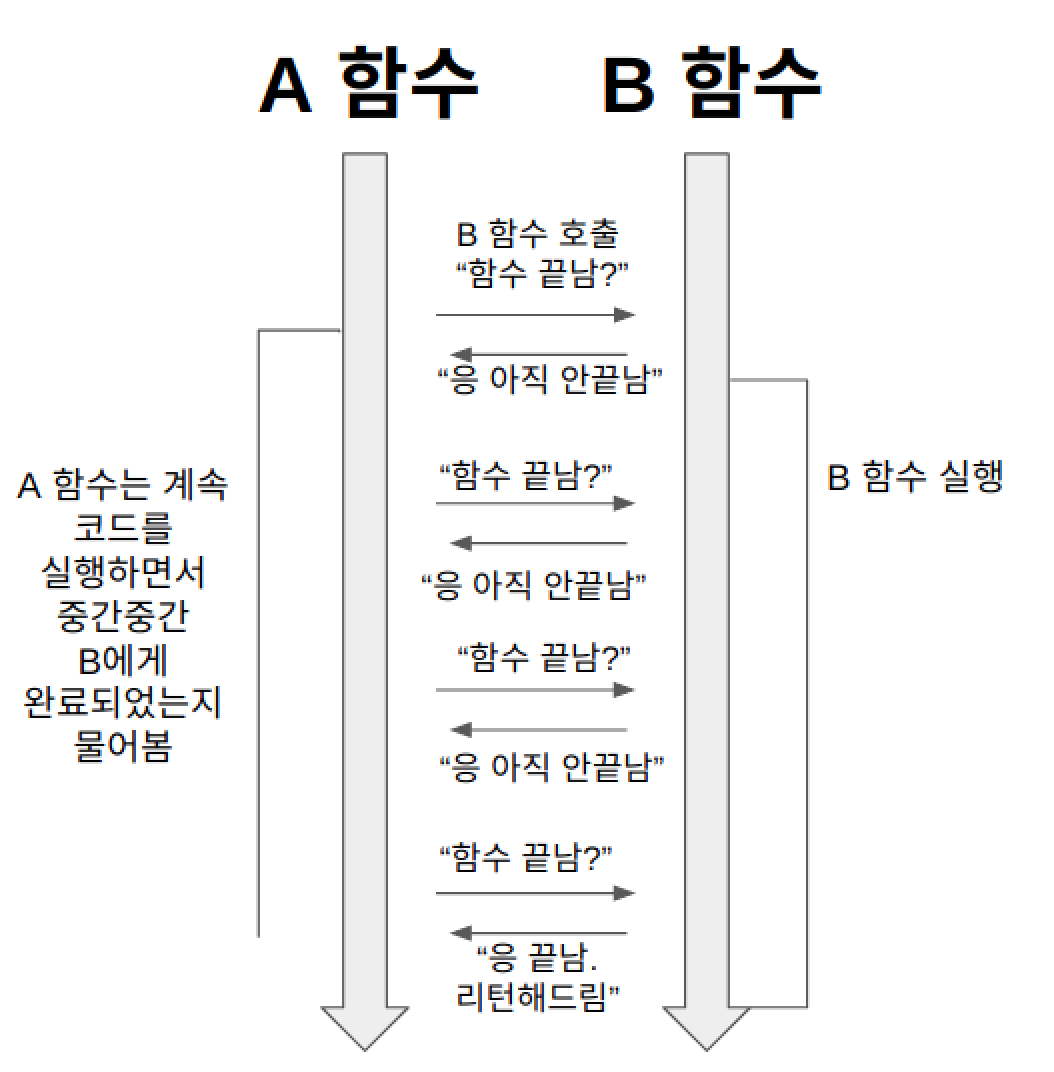
- A 함수는 B 함수를 호출한다. 이 때 A 함수는 B 함수에게 제어권을 주지 않고, 자신의 코드를 계속 실행한다(논블로킹).
- 그런데 A 함수는 B 함수의 리턴값이 필요하기 때문에, 중간중간 B 함수에게 함수 실행을 완료했는지 물어본다(동기).
- B 함수는 자신의 작업이 끝나면 A 함수가 준 콜백 함수를 실행한다(비동기).
- Asynchronous / Non-Blocking 비동기 논블로킹은 이해하기 쉽다. 자바 스크립트의 비동기 함수 동작 방식 A 함수는 B 함수를 호출한다. 이 때 제어권을 B 함수에 주지 않고, 자신이 계속 가지고 있는다(논블로킹). 따라서 B 함수를 호출한 이후에도 멈추지 않고 자신의 코드를 계속 실행한다. 그리고 B 함수를 호출할 때 콜백함수를 함께 준다. B 함수는 자신의 작업이 끝나면 A 함수가 준 콜백 함수를 실행한다(비동기).
Async-blocking의 경우 sync-blocking과 성능의 차이가 또이또이하기 때문에 사용하는 경우는 거의 없다.
- Blocking / NonBlocking - 제어권 : socket통신으로 설명
- Synchronous / Asynchronous : 리턴값에 대한 차이 (js의 콜백함수 등, 함수의 리턴값을 기다리지 않음)
- JS는 single-thread + non-blocking + async 방식
- Blocking Socket
-
accept,read에서 멈춤1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
#include <sys/socket.h> #include <netinet/in.h> #include <unistd.h> #include <string.h> int main() { int server_fd = socket(AF_INET, SOCK_STREAM, 0); struct sockaddr_in address; address.sin_family = AF_INET; address.sin_addr.s_addr = INADDR_ANY; address.sin_port = htons(8080); bind(server_fd, (struct sockaddr*)&address, sizeof(address)); listen(server_fd, 3); while(1) { int client_fd = accept(server_fd, NULL, NULL); // ←← 블로킹! char buffer[1024]; read(client_fd, buffer, 1024); // ←← 블로킹! write(client_fd, "HTTP/1.1 200 OK\r\n\r\nHello", 26); close(client_fd); } return 0; }
-
- NonBlocking Socket
-
fcntl(fd, F_SETFL, O_NONBLOCK)설정 후 즉시 리턴 -
select여러 소켓을 동시에 모니터링 가능 ```c // 이외에도 select, epoll 등을 호출해 사용할 수 있다. #include <sys/socket.h> #include <netinet/in.h> #include#include #include int main() { int server_fd = socket(AF_INET, SOCK_STREAM, 0); fcntl(server_fd, F_SETFL, O_NONBLOCK); // ←← 논블로킹 설정!
struct sockaddr_in address; address.sin_family = AF_INET; address.sin_addr.s_addr = INADDR_ANY; address.sin_port = htons(8080);
bind(server_fd, (struct sockaddr*)&address, sizeof(address)); listen(server_fd, 3);
while(1) { int client_fd = accept(server_fd, NULL, NULL); // 즉시 리턴
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
if(client_fd < 0) { if(errno == EAGAIN || errno == EWOULDBLOCK) { // 연결 없음, 다른 작업 가능 printf("다른 작업 중...\n"); usleep(100000); // 0.1초 대기 continue; } } else { char buffer[1024]; fcntl(client_fd, F_SETFL, O_NONBLOCK); if(read(client_fd, buffer, 1024) > 0) { write(client_fd, "HTTP/1.1 200 OK\r\n\r\nHello", 26); } close(client_fd); } } return 0; } ``` -
운영체제의 paging 과 page fault
페이징은 프로세스가 차지하는 물리적 메모리 공간이 비연속적이 되도록 허용하는 메모리 관리 기법을 말한다. 페이징은 외부 단편화가 발생하지 않으며, 따라서 별도의 Compaction 과정이 필요하지 않다.
- 다양한 크기의 메모리 덩어리(Chunk)들을 Backing store에 맞춰야 하는 문제를 해결해줌.
- 이 문제는 메인 메모리를 차지한 코드나 데이터가 swap out될 때, 그만한 공간을 Backing store에서 찾아야 하기 때문에 발생.
- Backing store에서도 동일하게 단편화 문제가 발생하지만, 메인 메모리에서보다 접근 속도가 훨씬 느리기 때문에 Compaction을 적용할 수 없다.
이러한 장점들 때문에 현재 대부분의 운영체제에서 다양한 형태로 사용되는 방법이다.
페이징을 구현하는 기본적인 방법은 물리적 메모리를 고정된 크기의 프레임(Frame)으로 나누고, 논리적 메모리를 동일한 크기의 페이지(Page)로 나누는 것 프로세스가 실행되면 프로세스의 페이지들은 메모리의 사용가능한 프레임으로 적재된다. Backing store 역시 고정된 크기의 block들로 나누어진다. CPU에 의해 생성된 모든 주소들은 페이지 번호(Page Number, p)와 페이지 간격(Page Offset, d)로 나뉜다. 페이지 번호는 페이지 테이블의 인덱스로써 사용된다.
페이징 기법을 사용할 때, 외부 단편화는 발생하지 않는다. 모든 사용 가능한 프레임은 그것을 필요로 하는 프로세스에게 할당될 수 있기 때문이다. 하지만 내부 단편화는 발생할 수 있다. 프레임은 일정한 크기로 할당되기 때문이다.
- 페이지의 크기는 왜 4KB인가?
- 내부 단편화와 외부 단편화의 균형
- 페이지가 너무 크면: 내부 단편화 증가 (메모리 낭비)
- 페이지가 너무 작으면: 페이지 테이블이 커져서 오버헤드 증가
- 4KB는 이 둘 사이의 적절한 균형
- TLB (Translation Lookaside Buffer) 효율성
- TLB는 가상-물리 주소 변환 정보를 캐시하는 하드웨어
- TLB 엔트리 개수가 제한적이라 페이지가 너무 작으면 TLB 미스가 자주 발생
- 4KB면 적당한 TLB 효율성 확보
- 역사적 배경
- 1980년대 ~ 1990년대 하드웨어 환경에서 최적화된 크기
- 당시 메모리 크기 (MB 단위)와 프로그램 크기를 고려한 설계
- x86 아키텍쳐에서 표준으로 채택되면서 널리 퍼짐
- 페이지 테이블 관리 오버헤드
- 32비트 시스템에서 4GB 주소 공간을 4KB로 나누면 1M개 페이지
- 페이지 엔트리당 4바이트면 페이지 테이블이 4MB (관리 가능한 크기)
- 더 작은 페이지면 테이블이 너무 커짐
- 디스크 I/O 효율성
- 대부분의 파일 시스템 블록 크기가 4KB 근처
- 페이지와 블록 크기가 비슷하면 스왑 효율성 증대
- 캐시 라인과의 호환성
- CPU 캐시 라인 크기와 어느 정도 맞아떨어짐
- 메모리 접근 패턴 최적화에 유리
- 현재는?
- 메모리가 많아지면서 큰 페이지(2MB, 1GB)도 지원
- Huge Pages, Large Pages 등으로 불림
- 데이터베이스나 대용량 애플리케이션에서 성능 향상 목적으로 사용
- 결국 4KB는 과거 하드웨어 환경에서 여러 요소들을 종합적으로 고려해서 나온 “최적해”였는데, 지금도 대부분의 일반적인 용도에서는 여전히 적절한 크기라고 볼 수 있음.
- 내부 단편화와 외부 단편화의 균형
- 스왑 (Swap)
- 메모리가 부족할 때 사용하는 “가상 메모리 확장” 기법
- 물리 메모리(RAM)이 가득 찰 때, 당장 안 쓰는 데이터를 디스크에 임시 저장
- 나중에 그 데이터가 필요하면 다시 메모리로 불러옴 (메모리 창고 같은 역할)
Internal Fragmentation(내부 단편화)
- Partitioning 상황에서 발생한다.
- Partition의 크기가 프로세스의 크기보다 커서 메모리가 남지만, 다른 프로세스가 사용할 수 없는 상태를 말한다.
100MB의 공간(Partition)에 Process C를 할당했다. 20MB의 여유 메모리가 존재하지만 Process C 에게 할당되어 사용할 수 없다. 이를 내부단편화라고 한다.
External Fragmentation(외부 단편화)
50MB의 두 여유 메모리가 존재하고 총 100MB의 여유 메모리가 존재한다. 그러나, 연속적이지 않은 공간에 존재하여 80MB인 Process C를 실행할 수 없다. 이를 외부단편화라고 한다. Compaction을 사용하여 외부단편화를 줄일 수 있다. Compaction : 흩어져 있던 공간을 하나의 연속적인 공간으로합치는 기법 구현이 복잡하다.
정수와 실수의 표현 방식
- 정수 자료형은 어떻게 표현하는가?
- 부호비트와 크기비트를 사용해 표현한다.
- 부호비트: 0은 양수, 1은 음수
- 크기비트: 비트의 크기
- 음수 표현 시 2의 보수를 사용함
-
-1표현- 1의 이진수 표현
- 1 =
00000001
- 1 =
- 1의 보수 표현 (모든 비트 뒤집기)
-
00000001->11111110
-
- 1을 더하기
-
11111110+00000001=11111111
-
- 1의 이진수 표현
-
-2표현- 2의 이진수 표현
- 2 =
00000010
- 2 =
- 2의 보수 표현 (모든 비트 뒤집기)
-
00000010->11111101
-
- 1을 더하기
-
11111101+00000001=11111110
-
- 2의 이진수 표현
-
- 2의 보수를 사용하기 때문에 맨 앞자리를 보면 바로 양수/음수 구분이 가능하다.
- 이렇게 부호 비트를 활용할 수 있는 것.
- 부호 비트를 사용하지 않을 경우
unsigned타입을 사용하면 된다.-
signed int: -2147483648 (2^31) ~ 2147483647 (2^31 - 1) -
unsigned int: 0 ~ 4294967295 (2^32 - 1)
-
- 예시
- 8비트 정수 표현
- 00000000: 0
- 00000001: 1
- 00000010: 2
- 00000011: 3
- 00000100: 4
- 00000101: 5
- 00000110: 6
- 00000111: 7
- 11111111: -1
- 11111110: -2
- 11111101: -3
- 11111100: -4
- 11111011: -5
- 11111010: -6
- 11111001: -7
- 8비트 정수 표현
- 부호비트와 크기비트를 사용해 표현한다.
- 실수자료형은 어떻게 표현하는가?
- 고정 소수점 방식과 부동 소수점 방식이 존재한다.
- 고정 소수점 방식은 소수점의 위치를 고정시키는 방식이다.
- 일상적으로 쓰는, 0 뒤에 소수점을 붙이는 방식을 기반으로 한다. 이를테면 8비트로 실수를 표현할 때 보통 ‘8비트의 앞 4비트는 정수부를, 뒤 4비트는 소수부를 나타낸다’라고 정해 놓는다. 그러면 1010.0111(2)을 ‘1010 0111’로, 11.011(2)은 ‘0011 0110’으로 나타낼 수 있다.
- 고정 소수점 방식은 빠르지만, 표현할 수 있는 수의 범위가 제한적이다.
- 그러나 데이터 특성이나 알고리즘에 따라 고정소수점 방식이 정확도도 좋고 빠른 경우가 존재할 수 있다.
- 소수부를 이진수로 표현하기 때문에 (표현하지 못하는 수도 있지만, 표현하는 수가 제한적이거나 하는 등)
- 고정 소수점 방식은 소수점의 위치를 고정시키는 방식이다.
- 부동소수점
- 일반적으로 범용적인 상황에서 대체로 고정 소수점 방식보다 더 높은 정확성을 보장한다.
- 그러나 고정 소수점 방식에 비해 실수 저장에 더 많은 연산이 필요하다는 단점이 존재한다. (지수부 계산 등)
- 이진수의 지수 표기법을 사용해 부동소수점을 표기한다.
- (+-)
x+y^n- (+-) : 부호
-
x: 가수 -
y: 기수 -
n: 지수
- 십진수 지수(exponent) 표기법
- 123.456 -> 123456e-3
- 123e2 -> 12300
- 123e-2 -> 1.23
- Float
- 32bit: 1bit(부호) + 8bit(지수) + 23bit(가수)
- Double
- 64bit: 1bit(부호) + 11bit(지수) + 52bit(가수)
- 118.625 를 float type (부동소수점) 방식으로 표현
- 118.625 = 1110110.101
- 정수 118 = 1110110
- 소수 0.625 = 101 = 0.625 * 2 = 1.250 = 0.250 * 2 = 0.500 = 0.500 * 2 = 1.000 -> 101
- 번외 ```
- 소수 표기법
- 0.1(2) - 0.5(10)
- 0.01(2) - 0.25(10)
- 0.001(2) - 0.125(10)
- 0.0001(2) - 0.0625(10) ```
- 소수점을 왼쪽으로 이동시켜 정수부가 한 자리가 되도록 한다.
- 1110110.101 -> 1.110110101 (6자리 이동)
- 이동시킨 자릿수(6) 만큼을 2의 지수를 사용해 곱해주고 , 이 수를 정규화된 부동 소수점이라고 함.
- 1.110110101 * 2^6
- 소수점 아래 부분 (110110101) 이 가수부(23bit)가 되도록 나머지 비트를 채움.
- 11011010100000000000000 * 2^6
- 부호 비트와 가수부를 설정함. (음수라서 부호 비트 1 설정, 8비트 (지수부) 띄우고 가수부(23bit) 설정)
1xxxxxxxx11011010100000000000000
- 지수부를 설정함.
- 32bit IEEE 754 형식에는 “Bias” 라는 고정된 값이 있음. 이는 127이며, bias를 2의 지수인 6에 더하고 2진수로 변환한다.
- 127 + 6 = 133
- 133(10) -> 10000101(2)
- Bias 값을더해주는 이유
- 음수 지수 표현의 단순화
- 음수 지수를 양수로 변환해 저장할 수 있음.
- 비교 연산의 효율성
- 숫자를 정규화시켜 수들의 비교가 더 쉬워짐.
- -2, -3을 Bias를 사용해 (125, 130) 으로 표현할 수 있음.
- 따라서 부호 있는 비교가 필요없기 때문에 비교 연산이 더 빠름.
- 숫자를 정규화시켜 수들의 비교가 더 쉬워짐.
- 특수값 처리의 용이성
- 지수부가 모두 0(언더플로우) 이나 1(오버플로우/무한대) 인 경우 쉽게 감지할 수 있음.
- 음수 지수 표현의 단순화
- 32bit IEEE 754 형식에는 “Bias” 라는 고정된 값이 있음. 이는 127이며, bias를 2의 지수인 6에 더하고 2진수로 변환한다.
- 최종 표현
11000010111011010100000000000000
- 고정 소수점 방식과 부동 소수점 방식이 존재한다.
BigO
- BigO 표기법의 O는 무엇이지? (Ordnung 오르드눙 notation)
- 그 외에 사용하고 있는 시간복잡도 표기법이 있는가?
- 특정한 자료구조를 Big O 표기법에 의해 설명해봐라.
- 리스트 설명함
- 오르드눙 (Ordnung)는 질서 , 규율, 규칙, 배열, 조직 또는 시스템을 의미하는 독일어
- 배열과 리스트의 차이점을 CS를 모르는 일반인 고등학생 정도의 사람들에게 설명한다고 가정하고 말해봐라.
- 트리를 컴퓨터 전공자에게 설명한다고 가정하고 말해봐라.
Thread (멀티 스레드 vs 멀티 프로세스)
- 스레드는 무엇이고 서로 다른 스택을 가지는가? / 만약 그렇다면, 왜 각각의 스택을 가지는가?
내가 멀티프로세스 환경에서 주로 개발함으로 인해 멀티스레드 기반 기술 스택을 가진 회사에서 이러한 스레드 관련 CS를 집중적으로 물어봄. 따라서 이는 무조건 공부해가야 한다.
- 스레드가 공유하는것들
- 코드 영역 (프로그램 코드)
- 데이터 영역 (전역 변수)
- 힙 영역 (동적 할당 메모리)
- 파일 디스크립터 (열린 파일들)
- 프로세스 ID (PID)
- 메모리 매핑 테이블
- 스레드가 가지는 것들 (독립적)
- CPU 레지스터들 (PC, SP, 범용레지스터)
- 스택 영역 (지역 변수, 함수 호출 정보)
- 스레드 ID
- 실행 상태 (Ready, Running, Blocked 등)
- 코드영역 (프로그램 코드), 데이터 영역 (전역 변수), 힙 영역 (동적 할당 메모리) 는 서로 공유한다.
- 하지만 스레드의 스택은 각 스레드마다 독립적으로 존재한다. 아래와 같은 이유로 독립적인 스택을 가짐.
- 독립적인 함수 호출 관리
- 지역변수의 독립성
- 재귀함수의 안전성
- 컨텍스트 스위칭
- 또한 스레드는 자신만의 레지스터 컨텍스트를 가진다.
- 스레드 컨텍스트 스위칭 (가벼움)
- 현재 스레드의 레지스터 저장
- 새 스레드의 레지스터 복원
- 스택 포인터만 변경
- 프로세스 컨텍스트 스위칭 (무거움) 1. 현재 프로세스의 모든 상태 저장 2. 메모리 매핑 테이블 전환 (MMU 설정 변경) 3. 캐시 무효화 4. 새 프로세스의 메모리 공간으로 전환 5. 새 프로세스의 상태 복원
- 레지스터: CPU의 물리적 저장 공간 (하드웨어)
레지스터 컨텍스트: 특정 순간의 모든 레지스터 값들 (소프트웨어적 개념)
- 뮤텍스 (Mutex) 와 세마포어 (Semaphore) 의 차이점에 대해 설명해라.
- 뮤텍스 Mutex = 락 Lock
- 공유 데이터를 보호할 때 (전역 변수, 파일 쓰기 등) (공유 자원에 대한 상호 배제)
- 소유권: O
- 용도: 상호 배제
- 동시 접근: 1개의 스레드만
- 값 범위: 0 또는 1
- 세마포어 Semaphore
- 리소스 풀 관리 (DB 커넥션 풀, 스레드 풀 등), Producer-Consumer 패턴, 스레드 간 신호 전달 목적
- 동기화 및 순서 제어
- 리소스 카운팅 (DB 커넥션이 5개 있고, 커넥션 하나 가져갔다가(sem_wait), 반납(sem_post))
- 제한된 동시 접근 허용 (프린터가 3대가 있어서 동시에 3명까지 사용 가능하지만, 스레드는 10개가 존재하여 제한된 동시 접근을 체크해야 할 때)
- 소유권: 없음 (아무나 signal 가능)
- 용도: 리소스 카운팅 + 신호 전달
- 동시 접근: n개의 스레드 (카운터 값)
- 값 범위: 0 이상의 정수
- 리소스 풀 관리 (DB 커넥션 풀, 스레드 풀 등), Producer-Consumer 패턴, 스레드 간 신호 전달 목적
- 뮤텍스 Mutex = 락 Lock
- 낙관적 락 / 비관적 락
- 낙관적 락
- 충돌이 거의 발생하지 않을 것이라고 가정하고 충돌이 발생한 경우 조치를 취하는 방식이다.
- 일반적으로 version의 상태를 보고 충돌을 확인하며, 충돌이 확인된 경우 롤백을 진행한다. (hashcode, timestamp를 이용하여 충돌을 확인하는 경우도 존재.)
1 2 3 4 5 6 7
version = 1, id = 1, name = "hwang", nick = "qwer" 1 req : id 1 의 name을 "lee"로 바꿔. (version = 1) 2 req : id 1 의 nick을 "asdf" 로 바꿔. (version = 1) 동시성 문제 발생 (1 req와 2 req 가 동시에 발생) 1 req -> version = 2, id = 1, name = "lee", nick = "qwer" 2 req -> 이미 버전이 2로 바뀌어 처리 불가
- 충돌이 발생할 경우에 대한 책임을 Application 단에서 짐, 따라서 충돌 발생 시 Application 에서 수동 Rollback 해줘야 함.
- 장점
- 리소스 발생 적음
- 락으로 인한 성능저하가 적음.
- 단점
- 충돌 발생 시 처리해야 할 외부 요인 존재
- 비관적 락
- 충돌이 발생할 확률이 높다고 가정하여, 데이터 엑세스 전 락을 걸어 충돌을 예방하는 방식이다.
- 공유 락(shared lock) 과 배타락(exclusive lock)이 존재.
- 공유락 : 다른 트랜잭션에서 읽기만 가능, 배타락 적용 불가
- 배타락 : 다른 트랜잭션에서 읽기, 쓰기 모두 불가, 공유락, 배타락 모두 적용 불가
- 장점
- 충돌 발생을 미연에 방지
- 데이터의 일관성 유지
- 단점
- 과도한 리소스 비용 발생
- 비관적 락이 잘못 걸리거나 서로 자원이 필요한 경우 교착상태의 발생 가능성 존재
- 낙관적 락
- Producer-Consumer 패턴 (이거 ipc_agent잖아…)
- Producer(생산자)-Consumer(소비자) 패턴
- 기본 개념
- Producer (생산자): 데이터를 만들어서 버퍼에 넣는 놈
- Consumer (소비자): 버퍼에서 데이터를 가져와 처리하는 놈
- Buffer (버퍼): 둘 사이의 임시 저장소 (보통 큐 형태)
- 비유
- Producer: 제품을 만들어서 벨트에 올리는 작업자
- Consumer: 벨트에서 제품을 가져와 포장하는 작업자
- Buffer: 컨베이어 벨트(제한된 공간)
- 문제점
- 버퍼가 가득 찰 때: 생산자가 기다려야 함
- 버퍼가 비었을 때: 소비자가 기다려야 함
- 동시 접근: 둘이 동시에 버퍼를 건드리면 깨짐
- 사용 예시
- 메시지 큐(Kafka, RabbitMQ), 스트리밍, 로그 시스템, 웹서버 등
- 동기화 방법들
- 세마포어: 버퍼 공간 관리
- 뮤텍스: 동시 접근 방지
- 조건 변수: 대기/알림 매커니즘
- 이 패턴의 핵심은 생산 속도와 소비 속도가 다를 때 안정적으로 데이터를 주고받는 것
- 멀티 프로세스와 멀티 스레드의 차이점과 각각의 장단점에 대해 설명해라.
- 멀티 스레드
- 장점
- 메모리 공유: 같은 프로세스 내에서 스레드들이 메모리를 공유해서 데이터 교환이 빠르고 효율적이야
- 빠른 생성/전환: 스레드 생성과 컨텍스트 스위칭이 프로세스보다 훨씬 빨라
- 리소스 효율성: 메모리 사용량이 적고 시스템 리소스를 덜 소모해
- 응답성: GUI 애플리케이션에서 UI 스레드와 작업 스레드를 분리해서 사용자 경험이 좋아져
- 단점
- 동기화 문제: Race condition, 데드락 같은 동시성 문제가 발생할 수 있어
- 디버깅 어려움: 버그 재현이 어렵고 디버깅이 복잡해
- 안정성: 한 스레드가 크래시하면 전체 프로세스가 영향받을 수 있어
- 복잡성: 공유 자원 관리를 위한 락, 세마포어 등의 동기화 메커니즘이 필요해
- 장점
- 멀티 프로세스
- 장점
- 안정성: 프로세스 간 격리되어 있어서 한 프로세스가 죽어도 다른 프로세스에 영향 없어
- 확장성: 여러 CPU 코어를 완전히 활용할 수 있어 (진정한 병렬 처리)
- 보안: 프로세스 간 메모리가 분리되어 있어서 보안이 더 좋아
- 단순함: 프로세스 간 간섭이 적어서 설계가 상대적으로 단순해
- 단점
- 무거움: 프로세스 생성과 컨텍스트 스위칭 비용이 커
- 메모리 오버헤드: 각 프로세스마다 독립적인 메모리 공간을 가져야 해서 메모리 사용량이 많아
- 통신 복잡성: IPC(Inter-Process Communication)를 통해 데이터를 주고받아야 해서 복잡하고 느려
- 리소스 소모: 시스템 리소스를 많이 사용해
- 장점
- 멀티 스레드
- 멀티프로세스와 멀티스레드의 장단점과 어떤 상황에서 사용해야 하는가?
- 멀티 프로세스는 CPU 집약적 작업에 효율적이다.
- 완전한 병렬 처리
- 독립적인 계산 및 동일 작업을 여러 데이터에 진행할 때 (수학 연산, 이미지 처리 등)
- 멀티 프로세스는 cpu의 각 코어마다 할당하여 연산작업을 수행할 수 있다.
- 멀티 스레드도 특정 코어에 고정할 수는 있지만 메모리 공유와 언어별 제약으로 인해 한계가 존재한다.
- 캐시 일관성 문제 (스레드의 경우 메모리를 공유하기 때문에 여러 코어가 메모리를 수정할 경우 캐시 일관성 문제가 발생할 수 있음.)
- False Sharing 또는 캐시미스 발생
- False Sharing: 서로 다른 스레드가 독립적인 데이터를 사용하는데도, 같은 캐시 라인에 위치해서 불필요한 캐시 무효화가 발생하는 현상
- 메모리 대역폭 경합 (각 스레드가 동일한 메모리 영역을 접근하려고 하기 때문, 멀티 프로세스는 각 프로세스가 독립적인 메모리 영역을 접근하기 때문에 캐시 히트율이 높음.)
- 멀티 스레드도 특정 코어에 고정할 수는 있지만 메모리 공유와 언어별 제약으로 인해 한계가 존재한다.
- 완전한 병렬 처리
- 멀티 스레드는 I/O Bound 작업이 많을 때 효율적이다.
- I/O 대기시간을 활용: 한 스레드가 대기중일 때 다른 스레드가 CPU 사용
- 빠른 컨텍스트 스위칭: I/O 완료 시 즉시 다른 스레드로 전환
- 메모리 효율성: 프로세스보다 훨씬 적은 메모리 사용
- 간단한 데이터 공유: 캐시, 연결 풀 등을 쉽게 공유
- 멀티 프로세스는 CPU 집약적 작업에 효율적이다.
- IO Bound
- I/O Bound는 프로세스가 진행될 때, I/O Wating 시간이 많은 경우다. 파일 쓰기, 디스크 작업, 네트워크 통신을 할 때 주로 나타나며 작업에 의한 병목(다른 시스템과 통신할 때 나타남)에 의해 작업 속도가 결정된다.
I/O Bound의 경우에는 CPU 성능보다 타 시스템과의 병목 부분(I/O Wating)에 큰 영향을 받기 때문에 스레드 개수를 늘리거나 동시성을 활용한다. 따라서 성능 향상을 위해 scale-out을 주로 사용한다.
- IO의 종류
- Storage IO (저장장치의 입출력)
- 특성: 지속성, 용량 큼, 속도 상대적으로 느림
- Disk IO: HDD, SSD 읽기/쓰기
- File IO: 파일 시스템 작업
- Database IO: DB 쿼리, 트랜잭션
- Cache IO: 디스크 캐시 접근
- 특성: 지속성, 용량 큼, 속도 상대적으로 느림
- Network IO (네트워크 입출력)
- 특성: 원격 통신, 지연시간 큼, 대역폭 제한
- Socket IO: TCP/UDP 통신
- HTTP IO: 웹 요청/응답
- API IO: REST, GraphQL 호출
- RPC IO: 원격 프로시저 호출
- 특성: 원격 통신, 지연시간 큼, 대역폭 제한
- Memory IO (메모리 입출력)
- 특성: 매우 빠름, 휘발성
- RAM Access: 메모리 읽기/쓰기
- Cache IO: L1/L2/L3 캐시 접근
- Virtual Memory: 페이징, 스왑
- Memory Mapping: mmap() 연산
- 특성: 매우 빠름, 휘발성
- Device IO (장치 입출력)
- 특성: 하드웨어 종속적, 드라이버 필요
- 입력 장치
- Keyboard IO: 키보드 입력
- Mouse IO: 마우스 이벤트
- Touch IO: 터치스크린
- Sensor IO: 온도, 압력 센서
- 출력 장치
- Display IO: 모니터 출력
- Printer IO: 프린터 출력
- Speaker IO: 오디오 출력
- Inter-Process IO (프로세스간 통신)
- 특성: 프로세스간 데이터 교환
- Pipe IO: 파이프 통신
- Message Queue: 메시지 큐
- Shared Memory: 공유 메모리
- Signal IO: 시그널 처리
- 특성: 프로세스간 데이터 교환
- Graphics IO (그래픽 입출력)
- 특성: GPU 사용, 대용량 데이터
- GPU IO: 그래픽 카드 통신
- Video IO: 비디오 스트림
- Texture IO: 텍스처 로딩
- Frame Buffer: 화면 버퍼 작업
- Audio IO (오디오 입출력)
- 특성: 실시간 처리, 지연 민감
- Microphone IO: 마이크 입력
- Speaker IO: 스피커 출력
- Audio File IO: 오디오 파일 처리
- Streaming IO: 실시간 오디오 스트림
- 특성: 실시간 처리, 지연 민감
- Serial IO (직렬 통신)
- 특성: 순차적 데이터 전송
- UART IO: 시리얼 포트
- USB IO: USB 장치 통신
- Bluetooth IO: 블루투스 통신
- I2C/SPI: 하드웨어 버스
- 특성: 순차적 데이터 전송
- Storage IO (저장장치의 입출력)
- 성능 비교 (대략적 속도)
IO 종류 지연시간 대역폭 CPU Cache 1ns 100GB/s RAM 100ns 50GB/s SSD 0.1ms 3GB/s HDD 10ms 200MB/s Network (LAN) 0.5ms 1GB/s Network (Internet) 50ms 100MB/s - CPU Bound
- CPU Bound는 프로세스가 진행될 때, CPU 사용 기간이 I/O Wating 보다 많은 경우다. 주로 행렬 곱이나 고속 연산을 할 때 나타나며 CPU 성능에 의해 작업 속도가 결정된다.
- CPU의 성능이 향상되거나 개수가 추가되면 CPU Bound의 작업 처리 성능이 향상된다. 따라서 성능 향상을 위해 scale-up이 주로 사용된다.
IPC (Inter Process Communication)
- IPC (Inter Process Communication)
- 메시지 큐
- 최대 메시지 크기: 보통 8KB
- 큐딩 최대 메시지 수: 보통 10개
- 시스템 전체 최대 큐 수: 보통 16개
- 공유 메모리 (Shared Memory)
- 최대 세그먼트 크기: 보통 32MB
- 시스템 전체 최대 세그먼트 수 : 보통 4096개
- 세마포어
- 세마포어 집합 당 최대 세마포어 수 : 보통 250개
- 시스템 전체 최대 세마포어 집합 수 : 보통 128개
- 파이프
- 파이프 버퍼 크기 : 보통 64KB
- Linux에서 이 정보들을 확인하려면 /proc/sys/kernel/ 의 정보들을 살펴보면 된다.
- 소켓 (Unix Domain Socket)
- 같은 시스템 내에서 통신하는 소켓
- 네트워크를 거치지 않고 커널 내부에서 동작함.
- SOCK_STREAM (TCP처럼 연결지향, 순서 보장)
- SOCK_DGRAM (UDP처럼 데이터그램 방식)
- UDS (Unix Domain Socket) 이 네트워크 통신보다 빠른 이유
- 네트워크 스택 우회
- TCP: 애플리케이션 → 소켓 계층 → TCP 계층 → IP 계층 → 네트워크 드라이버 → 루프백 → 다시 역순
- UDS: 애플리케이션 → 소켓 계층 → 커널 내부 버퍼 → 바로 상대방
- 패킷 처리과정 생략
- TCP: 헤더 추가/제거, 체크섬 계산, 시퀀스 번호 관리
- UDS: 단순한 메모리 복사만
- 체크섬: 메모리 ECC + 커널 보장
- 순서보장: 커널 FIFO 버퍼
- 재전송 불필요
- 흐름제어: 커널 버퍼 크기
- 네트워크 오버헤드 없음
- IP/TCP 헤더 없음 (보통 40 + bytes)
- 네트워크 대역폭 제한 없음
- 패킷 손실/재전송 걱정 없음
- 컨텍스트 스위칭 최소화
- 같은 커널공간에서 처리
- 커널이 네트워크 프로토콜 스택을 우회함.
- 인터럽트 처리 불필요
- 같은 커널공간에서 처리
- 네트워크 스택 우회
- 커널이 직접 관리하는 IPC들
- System V IPC (MQ, Shared Memory, Semaphore)
- Pipe
- Socket
- Signal
- 사용자 공간에서 관리되는 IPC
- D-Bus
- 사용자 맵 파일 (mmap으로 만든 공유 영역)
- 사용자 레벨 메시지 패싱 라이브러리들
- IPC 방식에 따라 대역폭이 대략적으로 다르다.
- 공유메모리 (50~100GB/s) (1 micro second)
- User A → Shared Memory ← User B (직접 접근)
- 복사 횟수 0
- 장점
- 엄청난 성능
- 단점
- 복잡한 동기화
- 에러 처리 지옥
- 개발/유지보수 비용 증대
- 디버깅 어려움
- 메모리 매핑 (40~80GB/s) (5 micro second)
- UDS (15~25GB/s) (50 micro second)
- User A → Kernel → Socket Buffer → Kernel → User B
- 복사 횟수 2번 (User→Kernel→User)
- TCP 루프백 (10~15GB/s) (100 micro second)
- User A → Kernel → Network Stack → TCP → IP → Loopback → IP → TCP → Kernel → User B
- 복사 횟수 4번 (User→Kernel→Network→Kernel→User)
- POSIX MQ (1~5GB/s) (200 micro second)
- 메시지 크기제한 8KB 기본
- 우선순위 큐를 사용함.
- 일반 큐가 아니라 우선순위 큐를 사용하는 이유
- 실시간 시스템의 필수 요소 (긴급 상황, 데이터에 대한 우선순위 처리 가능)
1 2 3 4 5 6
enum message_priority { PRIORITY_EMERGENCY = 31, // 심장 정지 알람 PRIORITY_CRITICAL = 20, // 혈압 위험 PRIORITY_WARNING = 10, // 일반 경고 PRIORITY_INFO = 0 // 상태 정보 };
- 시스템 제어 vs 데이터 분리
- QoS (Quality of Service) 구현
- QoS: 네트워크에서 트래픽을 우선순위를 정해서 중요한 데이터를 먼저 보내거나 더 죻은 품질로 전송하는 기술
- 시스템 제한 늘려서 대역폭 개선 가능
1 2 3 4
# /etc/sysctl.conf 또는 런타임 설정 echo 1000 > /proc/sys/fs/mqueue/msg_max # 메시지 개수 echo 65536 > /proc/sys/fs/mqueue/msgsize_max # 64KB로 증가 echo 1024 > /proc/sys/fs/mqueue/queues_max # 큐 개수
- System V MQ (0.5~3GB/s) (300 micro second)
- 메시지 크기제한 4KB 기본
- 메시지 구조가 POSIX MQ보다 더 무거움
- 장점
- 레거시 시스템과의 호환성
- 메시지 타입 필터링의 강력함
- 더 세밀한 권한 제어
- 시스템 전역 가시성
- 특수한 고급 기능들
- 공유메모리 (50~100GB/s) (1 micro second)
- 메시지 큐
- POSIX MQ가 UDS, SharedMemory보다도 성능이 느린데.. 왜 그렇지?
- ex) 8kb 데이터를 1억개 전송한다고 가정해봅시다.
- 메모리 할당/해제 오버헤드
- UDS: 미리 할당된 sk_buff 재사용해서 추가 할당하지 않음.
- (하지만 shared memory에 비해서 데이터 복사는 일어날 수 있다. 이것으로 인해 shared memory보다 대역폭이 떨어짐.)
- POSIX MQ: 1억번의 kmalloc/kfree
- UDS: 미리 할당된 sk_buff 재사용해서 추가 할당하지 않음.
- 메타데이터 처리 오버헤드
- UDS: 거의 순수 데이터
- POSIX MQ: list_head 포인터, m_type, proiroty 등, 52byte 정도의 플래그가 존재해 오버헤드
- 메시지 당 52byte * 1억개 : 약 5GB의 추가 메타데이터
- 우선순위 처리 오버헤드 (1억번)
- 1억번의 우선순위 정렬 발생
- 메모리 압박 문제
- 1억 개의 메시지가 동시에 존재할 경우
- UDS: 1000 * (sizeof(struct sk_buff) + 8192) // 1000개 정도만 유지
- POSIX MQ: 100000000 * (sizeof(struct msg_msg) + 8192) // 800GB
Memory Allocation
- malloc / free
- malloc과 free는 생각보다 무거운 연산임
- 일반적으로는 free가 더 무겁다. (대부분의 경우)
- 하지만 malloc도 상당한 오버헤드가 존재한다.
- 상황에 따라 차이가 크다.
- malloc이 하는 일 (50~100ns)
- 적절한 크기의 청크 찾기
- 필요 시 청크 분할
- 메타데이터 설정
- free가 하는 일 (80~300ns)
- 포인터 유효성 검사
- 시스템 안정성 보호
- 잘못된 포이터 해제 시, 자유 리스트 조작 및 리스트 구조 파괴하여 전체 힙 구조가 붕괴되고 시스템이 크래시됨.
- 따라서 최소한의 일관성을 체크
- 포인터 정렬 검사
- 청크 크기 일관성 검사
- 사용중인 청크인지 확인
- 포인터 유효성 검사를 한다면 왜 해제된 포인터 또는 잘못된 포인터를 free 할 때 죽는가?
- 제한적인 검사만 하기 떄문이다.
- 완전한 검사를 하지 않는다.
- 성능상의 문제
- 완전한 유효성 검사를 하려면 모든 할당된 청크들을 순회해야 한다.
- 메모리 레이아웃의 한계
- 메모리 할당자는 힌트만 가지고 있다.
- 이전 청크 크기, 현재 청크 크기 + 플래그들 (이것만으로는 완전한 검증을 할 수가 없다.)
- 성능상의 문제
- 시스템 안정성 보호
- 인접 청크들과 병합 <- 가장 무거움
- 메모리 단편화 방지가 핵심
- 병합하지 않으면
- 100바이트씩 5개 할당
- 2번째 4번째 해제 (병합 없이)
- 200바이트 자유공간이 있지만, 100바이트로 나누어져 있어 차웋 200byte 할당 필요 시 할당 불가.
- 연속된 200byte가 없고 100byte 두개로 나뉘어져 있기 때문임
- 적절한 자유 리스트에 삽입 <- 정렬 필요
- 빠른 재할당을 위한 자료구조
- 자유 리스트가 없다면 매번 malloc 시 전체 힙을 스캔해야 함.
- 크기별 분류로 최적화
- Fast bins (16-80 bytes) - LIFO 스택
- Small bins (< 1024 bytes) - 크기별 더블 링크드 리스트
- Large bins (>= 1024 bytes) - 크기+주소 정렬 트리
- 메모리 지역성 최적화
- 빠른 재할당을 위한 자료구조
- 큰 메모리는 시스템이 반환
- 큰 메모리의 기준
- glibc의 기본 임계값 128kb
- 128kb 이상은 즉시 반환해서 시스템 압박 완화
- 128KB 이상 = mmap 시스템 콜 사용 (이 mmap은 파일 매핑 mmap이 아니라 익명 mmap이다.)
- 왜 128KB가 기본 크기일까?
- 페이지 크기 고려
- 일반적인 페이지 크기: 4KB
- 128KB = 32 페이지 = 합리적인 단위
- 시스템 콜 오버헤드
- mmap/munmap: ~1000 cycle
- 작은 메모리에는 비용 대비 효과 부족
- 메모리 단편화 밸런스
- 너무 작으면: 힙 단편화 심각
- 너무 크면: 메모리 낭비 심각
1 2 3 4
// glibc malloc의 기본 설정 #define DEFAULT_MMAP_THRESHOLD (128 * 1024) // 128KB #define MAX_MMAP_THRESHOLD (512 * 1024) // 512KB #define MIN_MMAP_THRESHOLD (0)
- 페이지 크기 고려
- 메모리 압박 상황 대응
- 큰 메모리를 계속 보유한다면?
- 1GB 메모리 할당 후 잠깐 사용한 뒤 해제
- 할당자가 1GB를 계속 보유한다면?
- 다른 프로세스가 메모리 부족으로 고생
- 시스템 전체 성능 저하
- OOM Killer (Out Of Memory Killer)가 이 프로세스를 죽일수도..
- 하지만 시스템에 반환하면?
- 다른 프로세스가 사용 가능
- 시스템 메모리 압박 완화
- 큰 메모리를 계속 보유한다면?
- 가상 메모리 시스템과의 협력
- 큰 메모리의 기준
- 포인터 유효성 검사
- free가 더 무거운 이유
- 메모리 병합 (인접 청크 합치기)
- 자유 리스트 관리 (크기별 정렬 삽입)
- 포인터 유효성 검사
- 시스템 메모리 반환 (큰 블록)
- 최적화 방법
- 메모리 풀 사용 (커넥션 풀 처럼 메모리를 미리 할당해두고 필요할 때마다 사용)
- 배치 할당/해제
- 고성능 할당자 (jemalloc)
- 객체 재사용
Valgrind 원리
- Valgrind가 메모리를 검사하는 방법
- 바이너리를 가상머신에서 실행함.
- 모든 메모리 접근을 인터셉트
- Shadow memory 를 사용해서 각 바이트의 상태를 추적
- 실제 메모리와 1:1 대응되는 그림자 메모리를 유지
- 실제 메모리 1바이트당 그림자 메모리 1비트 사용
- 모든 malloc / free를 추적해서 테이블에 기록
- 10~100배 느려짐
- Address Sanitizer
- 컴파일 타임에 코드를 변경
- Shadow memory 사용
- Red zones 삽입
- malloc 시 앞뒤로 레드존 추가
- 버퍼 오버플로우 시 레드존 접근으로 즉시 감지
- 2~3배 느려짐
- 런타임에 체크
mmap
- mmap
- 파일 매핑 mmap
- 첫 접근 (Cold)
- 🐌 디스크 속도 (HDD: ~100MB/s, SSD: ~500MB/s)
- ⏱️ 레이턴시: HDD 10ms, SSD 0.1ms
- 재접근 (Warm)
- 🚀 RAM 속도 (~50GB/s)
- ⏱️ 레이턴시: ~100ns
- 핵심 포인트
- 🔄 지연 로딩: mmap 호출은 즉시, 실제 읽기는 접근 시
- 💾 페이지 캐시: 한번 읽은 데이터는 RAM에 캐시
- 📈 접근 패턴: 순차 > 랜덤 (프리페칭 효과)
- 🎯 madvise: 힌트로 성능 최적화 가능
- 요약
- 처음엔 디스크 속도만큼 느림
- 이후엔 RAM 속도만큼 빠름
- 전체적으로는 read()보다 효율적 파일 매핑 mmap은 “스마트한 캐싱 시스템”이라고 보면 돼! 😄
- 디스크와 메모리를 1대1 매핑하는 함수
- 파일매핑 mmap의 메모리는 R/W 등이 디스크에 접근하고 쓰는 속도와 비슷한가?
- 처음에는 느리지만, 이후엔 빨라짐
- mmap의 지연 로딩, 페이지 캐시 때문에 생각보다 복잡함.
- 파일매핑 mmap의 메모리는 R/W 등이 디스크에 접근하고 쓰는 속도와 비슷한가?
- 접근 패턴에 따른 성능 차이도 존재함.
- 순차 접근이 랜덤 접근보다 빠름. (랜덤 접근은 캐시 미스 많음)
- 메모리 조언 (madvise) 활용
- lazy loading
- 즉시 접근하지 않음.
- 따라서 실제 접근할 때 페이지 폴트가 발생함.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
#include <sys/mman.h> #include <sys/stat.h> #include <fcntl.h> void mmap_lazy_loading_demo() { // 1GB 파일 생성 int fd = open("huge_file.dat", O_RDWR | O_CREAT, 0644); ftruncate(fd, 1024 * 1024 * 1024); // 1GB printf("1GB 파일 생성 완료\n"); // 파일 매핑 - 즉시 실행됨! struct timespec start, end; clock_gettime(CLOCK_MONOTONIC, &start); char *mapped = mmap(NULL, 1024 * 1024 * 1024, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0); clock_gettime(CLOCK_MONOTONIC, &end); double mmap_time = (end.tv_sec - start.tv_sec) + (end.tv_nsec - start.tv_nsec) / 1e9; printf("1GB mmap 호출 시간: %.6f초 (매우 빠름!)\n", mmap_time); printf("왜? 아직 실제로는 디스크에서 아무것도 안 읽었거든!\n"); close(fd); }
- page cache
- 커널의 페이지 캐시 시스템
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
// 커널 관점에서 mmap 페이지 폴트 처리 (의사코드) void handle_mmap_page_fault(void *virtual_addr, struct vm_area_struct *vma) { // 1. 가상 주소를 파일 오프셋으로 변환 off_t file_offset = vma->vm_pgoff + ((virtual_addr - vma->vm_start) >> PAGE_SHIFT); // 2. 페이지 캐시에서 확인 struct page *page = find_page_in_cache(vma->vm_file, file_offset); if (page) { printf("캐시 히트! RAM에서 즉시 반환\n"); // 페이지 테이블에 매핑만 추가 map_page_to_process(page, virtual_addr); } else { printf("캐시 미스! 디스크에서 읽어야 함\n"); // 디스크에서 읽기 page = read_page_from_disk(vma->vm_file, file_offset); // 페이지 캐시에 저장 add_page_to_cache(page); // 프로세스에 매핑 map_page_to_process(page, virtual_addr); } }
- 커널의 페이지 캐시 시스템
- virtual memory
- 첫 접근 (Cold)
- 익명 mmap (malloc 으로 큰 메모리 할당할 때에도 이 익명 mmap을 사용함)
- 가상 메모리 영역 할당
- 물리 페이지와의 연결
- 페이지 테이블 설정
1 2 3 4 5 6 7 8 9 10 11 12 13
void lazy_allocation_demo() { // 1GB mmap 요청 char *huge = mmap(NULL, 1024*1024*1024, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0); printf("1GB mmap 성공! 하지만 실제 메모리는 아직 안 씀\n"); // 실제 접근할 때 페이지 할당됨 (page fault) huge[0] = 'A'; // 첫 페이지만 실제 할당됨 huge[1024*1024*1024-1] = 'Z'; // 마지막 페이지 할당됨 printf("실제로는 2개 페이지(8KB)만 물리 메모리 사용!\n"); }
- 이런 코드로 인해 아래와 같은 상황에서는 실제로 1기가 메모리 사용함.
1 2 3 4 5 6
const int gib_1_size = 1024 * 1024 * 1024; char *ptr1 = (char *)malloc(gib_1_size); memset(ptr1, 0, gib_1_size); // 이런 경우에는 calloc이 효율적 char *ptr2 = calloc(1, gib_1_size);
- 왜 malloc/memset 보다 calloc이 더 빠른가?
malloc/memset은 memset으로 인해 1GiB 메모리를 모두 사용함.
- calloc은 MAP_ANONYMOUS 플래그로 인해 mmap된 메모리는 커널에서 자동으로 0으로 초기화해주기 때문
- mmap()으로 할당된 메모리는 이미 0으로 초기화되어 있음.
calloc은 이걸 알고 있어서 memset을 건너뜀.
- 하지만 작은 메모리 할당 해제에는 똑같다. (익명 mmap을 사용하지 않는 경우)
- calloc은 항상 0으로 초기화된 메모리르 반환함
- 사용자는 절대 추가 memset 필요 없음
- 내부적으로 구현 방식이 다름
- 작은 메모리: calloc이 내부에서 memset
- 큰 메모리: calloc이 memset 건너뜀
- 파일 매핑 mmap
- malloc : memory allocation
- calloc : contiguous allocation
realloc : resize allocation
- malloc vs calloc
-
malloc(400)- 400byte 줘 -
calloc(100, sizeof(int)),int (4byte)100개 할당해 줘 (배열 선언 등) - malloc: 메모리만 달라
- calloc: 0으로 초기화된 메모리 또는 배열을 달라
calloc은 큰 메모리에서 매우 효율적
- malloc은 성능 최적화 (불필요한 초기화 방지), 작은 할당 등에서 calloc보다 빠름.
- malloc: 구조체, 즉시 덮어쓸 데이터
calloc: 배열, 큰 메모리, 0 초기화 필요
- 둘 다 같은 가상 멤뢰 주소 공간을 사용하고, CPU 캐시 동작도 동일하기 때문에 접근성능 등에서의 차이는 없음.
-
파일 매핑 mmap vs read/write 함수
-
파일 매핑 mmap vs read/write 함수
- mmap의 함정들
- 작은 파일에서는 오히려 느림
- ex) 12byte 파일 읽기 (12byte를 위해 mmap에서는 4096 bytes 페이지를 할당해야 하기 떔누에 오버킬)
- 메모리 압박 문제
- 1기가 파일을 읽는다고 가정할 때
- read() 방식: 필요한 만큼만 읽기
- 메모리 사용: 64KB (버퍼 크기만큼)
- mmap() 방식: 전체 파일 매핑
- mmap 방식을 사용하면 가상메모리 1GB 사용
- 실제 물리 메모리: 접근한 페이지만
- 가상공간을 1GB씩이나 소모
- read() 방식: 필요한 만큼만 읽기
- 1기가 파일을 읽는다고 가정할 때
순차 읽기에서는 read가 더 효율적
- read가 더 좋은 상황
- 작은 파일 (< 4KB)
- 스트리밍 처리
- 네트워크나 파이프 입력
- 에러 처리의 명확성 (에러 처리가 중요한 경우)
- 포터빌리티와 호환성 -포터빌리티 문제?
- 파일 크기를 모르는 경우
- 메모리가 부족한 환경
- mmap 사용이 좋은 경우
- 큰 파일
- 랜덤 접근이 많은 경우
- 파일의 일부만 자주 접근
- 여러 프로세스가 공유
- 메모리 매핑된 자료구조
- 지연 로딩이 유리한 경우
- 파일과 메모리 동기화가 필요한 상황
- ex) 대용량 데이터페이스
- 작은 파일에서는 오히려 느림
- mmap의 함정들
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
높은 주소
┌─────────────────┐
│ 스택 │ ← 지역변수, 함수 호출
├─────────────────┤
│ ↕ │ ← 스택/힙 사이 빈 공간
├─────────────────┤
│ mmap 영역 │ ← mmap(), 공유 라이브러리
│ (Memory Mapping)│ 큰 malloc 할당
├─────────────────┤
│ ↕ │
├─────────────────┤
│ 힙 영역 │ ← 작은 malloc 할당
│ (heap) │ sbrk/brk로 확장
├─────────────────┤
│ 데이터 영역 │ ← 전역변수, 정적변수
├─────────────────┤
│ 텍스트 영역 │ ← 프로그램 코드
└─────────────────┘
낮은 주소
sbrk/brk
- sbrk/brk?
- 힙 영역의 크기를 조절하는 시스템 콜
program break: 힙 영역의 끝 지점을 가리키는 포인터
- 핵심: sbrk/brk는 연속된 힙 메모리 공간을 만들어주는 도구. mmap처럼 여기저기 흩어진 게 아니라 한 덩어리로 쭉 이어진 메모리를 관리 이로 인해 작은 malloc들이 메모리 단편화 없이 효율적으로 관리될 수 있음.
- brk vs sbrk
- brk (void addr)
- sbrk (intptr_t increment)
- brk
1 2 3
#include <unistd.h> // 힙의 끝을 특정 주소로 설정 brk(new_end_address); // 절대 위치 설정
- sbrk
1 2 3 4 5
#include <unistd.h> // 현재 위치에서 상대적으로 증가/감소 void *old_brk = sbrk(1024); // 1024바이트 증가 void *current = sbrk(0); // 현재 위치만 확인 sbrk(-512); // 512바이트 감소
- malloc과의 관계
1 2 3 4 5 6 7 8 9 10 11
// malloc 내부에서 이런 식으로 동작 void* my_malloc(size_t size) { void *current_brk = sbrk(0); // 힙 공간이 부족하면 if (need_more_space) { sbrk(size); // 힙 확장 } return allocated_pointer; }
익명 mmap
- 익명 mmap (큰 메모리)
- mmap, munmap 시스템 콜 등이 추가로 필요해 malloc에 비해 상대적으로 느림.
- 시스템 콜 오버헤드 (매번 커널모드 전환 필요 -> 느림)
- 외부 단편화 발생 가능성 (가상 주소 공간 파편화)
- munmap() 으로 free 시 즉시 OS에 반납
- mmap, munmap 시스템 콜 등이 추가로 필요해 malloc에 비해 상대적으로 느림.
- malloc (작은 메모리)
- 할당 해제 성능이 빠름
- 사용자 공간에서 처리되어 할당/해제 처리가 빠름.
- malloc: 빠름, 기존 heap 영역에서 블록을 찾기 때문
- free: heap 내부 관리로 인해 빠름.
- 내부 단편화 가능, 하지만 관리됨.
- free 해도 즉시 OS에 반납 안함. (재사용을 위해 보관됨.)
- 이로 인해 시스템 콜 호출이 절약됨.
- 처음 malloc 호출
- heap이 비어 있으면 brk() 또는 sbrk() 시스템 콜로 heap 확장
- 보통 128KB 정도 미리 확보
- 처음 malloc 호출
- 이후 malloc 호출들
- 기존 heap 영역 내에서 블록 찾기/분할
- 시스템 콜 없음.
- 이후 malloc 호출들
- heap 공간 부족 시
- 다시 brk() 시스템 콜로 heap 확장
- heap 공간 부족 시
- free() 동작 시
- 내부 자료구조만 업데이트
- 메모리를 heap 풀에 반환 (OS에는 반환 안함.)
- free() 동작 시
- 큰 영역 정리 시
- 많은 free 이후 heap이 상당히 비워지면
- malloc_trim () 등으로 OS에 일부 반환 -> 시스템 콜
- M_TRIM_THRESHOLD 기본값 128KB
- heap의 최상단 (top-most)에 있는 해제 가능한 청크가 128KB 이상이면
- 시스템 콜 (brk(), sbrk() 등을 호출해서 메모리를 OS에 반환)
- 주요 특징
- top-most 청크만 해당
- heap 중간의 빈 공간은 상관없음
- heap 끝부분의 연속된 빈 공간만 계산
- 이 값은 프로그램 패턴에 따라 동적으로 조절되며, 수동으로 설정하면 동적 조절 비활성화
- 프로그램에서 큰 메모리를 해제할 때
- 해제된 chunk 크기가 현재 mmap_threshold 보다 크면
- mmap_threshold를 그 크기로 증가시킴
- 동시에 trim_threshold는 mmap_threshold의 2배로 설정
- 왜 이렇게 설계?
- 큰 메모리를 자주 사용하는 프로그램이라면
- mmap_threshold를 높여서 heap 에서 할당하게 하고
- trim_threshold도 높여서 heap을 자주 축소하지 않게 함.
- 이렇게 성능 최적화 - 환경 변수로도 설정할 수 있다
- 큰 영역 정리 시
- 이로 인해 시스템 콜 호출이 절약됨.
- 할당 해제 성능이 빠름
32bit 운영체제의 메모리 제한
- 32Bit 운영체제의 메모리는 4GiB까지밖에 사용할 수 없다. 그 이유는?
- 포인터가 32Bit (4Byte) 까지밖에 표현할 수 없어 그 이상의 메모리를 사용할 수 없다.
- 말했던 4byte 포인터가 애플리케이션 레벨에서 말한 포인터인가? (물리주소가 정답)
- 애플리케이션 레벨 (가상주소) 에서 4Byte 까지밖에 표현할 수 없다. 라고 말하면, 각 어플리케이션마다 4GiB를 표현할 수 있다 라는 것이기 때문에 이는 오류임. (가상주소를 통해 실제 RAM 공간보다 더 많은 메모리 적재가 가능하기 때문)
- 가상주소: 프로그램에서 사용하는 주소 (메모리 보호와 프로세스간 독립성 제공) (이런 가상 주소 (가상메모리)가 있기 때문에 실제 RAM 공간보다 더 많은 메모리 적재가 가능하다.)
- 물리주소: 실제 RAM에 있는 메모리 주소, 가상 주소는 물리 주소로 변환됨.
- 주소변환: 가상주소를 물리주소로 변환하는 과정, CPU의 메모리 관리 유닛에 의해 변환됨.
- 페이지 테이블: 가상주소와 물리주소 간의 매핑 정보를 저장하는 데이터 구조. 페이지 테이블을 사용해 가상 주소를 물리 주소로 변환함.
numpy
- numpy 벡터 연산, 이것이 C/Rust보다 빠른 이유는 무엇인가?
- 일단 numpy 자체가 C로 구현됨. (C/C++/Fortran 으로 작성됨.)
- 벡터화의 위력
- SIMB 최적화 (CPU의 SIMB 명령어를 통해 한 번에 여러 데이터를 처리. ex: 4개의 float 를 동시 곱셈)
- 메모리 접근 최적화 (연속된 메모리 블록에서 효율적인 데이터 R/W, 캐시 미스를 최소화하는 메모리 레이아웃)
- 고도로 최적화된 라이브러리
- BLAS 같은 검증된 수학 라이브러리
- Intel MKL, OpenBLAS 같은 최적화 백엔드 사용
✅ numpy가 유리한 경우
- 대용량 배열 연산
- 수학적 연산 (행렬 곱셈, 통계 함수 등)
- 전체 배열에 대한 연산 ❌ 직접 C/Rust가 더 좋은 경우
- 복잡한 조건문이 많은 로직
- 메모리 사용량이 중요한 경우
- 매우 특화된 알고리즘
- 작은 데이터셋
Sort (정렬 알고리즘)
- 버블/삽입 정렬과 같은 O(n^2) 정렬 알고리즘보다 효율적인 알고리즘을 말해보아라.
- 퀵소트와 머지소트
- 퀵소트의 시간복잡도
- 퀵소트의 평균/ 최악 시간복잡도는 몇인가?
- 평균: O(n log n)
- 최악: O(n^2)
- 또한 퀵소트는 메모리의 지역성을 잘 활용하는 알고리즘이라 타 알고리즘 대비 훨씬 빠르다.
- 퀵소트는 다른 소트 알고리즘과 다르게 메모리를 적게 사용한다고 했다. 그 이유는?
- in-place 정렬 알고리즘이기 때문
- 두 원소의 위치만 바꾸는 swap 연산만 사용함.
- 공간복잡도 평균 O(log n), 최악 O(n)
- in-place 정렬 알고리즘이기 때문
- Pivot이 3개가 있으면 더 느려질까/빨라질까/똑같을까?
- 최악 시나리오를 개선, 캐시 지역성 향상, 중복 값에 대한 스킵으로 인해 처리능력 증가 등으로 인해 더 안정성있는 동작을 보장할 수 있다.
- -> 일반적으로 비슷하거나, 더 빨라짐! 번외
- 배열
- 퀵소트
- 힙소트 (퀵소트의 최악 케이스보다 안정적)
- 리스트
- 머지소트 (순차 접근만 가능한 리스트에 최적화)
- 삽입정렬 (작은 리스트) 분할 방식
- 머지소트: 배열을 반으로 균등 분할 → 정렬 후 합병
- 퀵소트: 피벗 기준으로 크기별 분할 → 분할 자체가 정렬 시간복잡도
- 머지소트: 항상 O(n log n) - 안정적!
- 퀵소트: 평균 O(n log n), 최악 O(n²) 공간복잡도
- 머지소트: O(n) - 합병용 임시 배열 필요
- 퀵소트: 평균 O(log n) - in-place 정렬 머지소트 장단점 장점: ✅ 시간복잡도가 항상 O(n log n)으로 안정적 ✅ 안정 정렬 (같은 값의 상대적 순서 보존) ✅ 외부 정렬에 적합 (큰 데이터셋) ✅ 성능 예측 가능 단점: ❌ O(n) 추가 메모리 필요 ❌ 작은 배열에서는 오버헤드 ❌ 캐시 효율성 낮음 퀵소트 장단점 장점: ✅ 평균적으로 가장 빠름 ✅ in-place 정렬로 메모리 효율적 ✅ 캐시 친화적 ✅ 실제 성능이 뛰어남 단점: ❌ 최악의 경우 O(n²) ❌ 불안정 정렬 ❌ 피벗 선택에 따라 성능 차이 큼 ❌ 재귀 깊이가 깊어질 수 있음 언제 뭘 써야 할까? 머지소트 추천: 안정 정렬이 필요할 때 최악의 경우에도 성능 보장이 필요할 때 외부 정렬이나 링크드 리스트 정렬 퀵소트 추천: 일반적인 배열 정렬 (평균 성능 최고) 메모리가 제한적일 때 캐시 효율성이 중요할 때
- 퀵소트와 머지소트
- CORS 가 무엇인가?
- XSS와 CSRF 등의 공격을 방지 (위변조된 페이지 접근을 막아 보안을 향상)
- CORS 상황을 겪어보았나?
- Access-Control-Allow-Origin 헤더 세팅, 쿠키를 사용할 경우
Access-Control-Allow-Credentials: true필수
CSRF (Cross-Site Request Forgery)
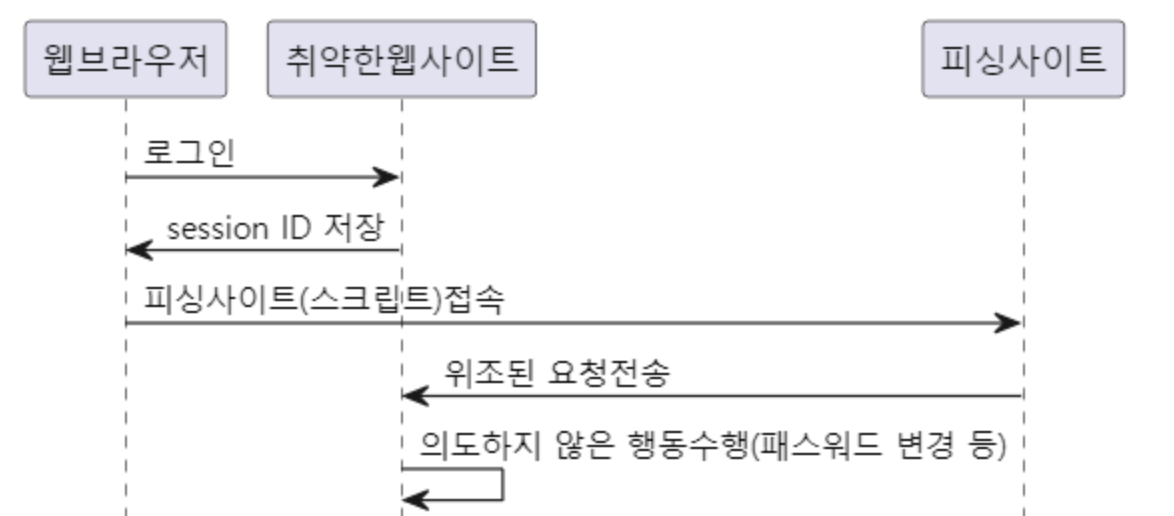
- CSRF Cross-Site Request Forgery
- 사이트 간 요청 위조의 줄임말.
아래 공격 방식이 CSRF 공격
인코딩
- 바이너리 데이터라는 것은 정확히 어떤 의미인가?
- 바이너리 데이터는 문자 데이터가 아닌 데이터를 의미한다.
- 문자도 크게 보면 바이너리의 일종이다.
-
A문자 -> 65 (Ascii)-> 01000001,A라는 문자를 입력하면, 실제로는01000001이라는 바이너리 데이터를 전달하는 것이다.
-
- 키보드로 입력할 수 있는 것들을 문자 데이터 (abcdefg…ABCD… 12345… !@#$% …) 라고 암묵적인 약속을 하고 있다.
- 바이너리 데이터는 문자 데이터가 아닌 데이터를 의미한다. 단순히 말하면 키보드로 입력하지 못하는 문자(제어 문자
\0- 널 문자 등)를 의미한다.
- 한글은 2바이트인가?
- 정답: 그럴수도 있고, 아닐수도 있다. -> 모범 정답: 인코딩의 방식에 따라 다르기 때문에, 알 수 없다.
- EUC-KR 인코딩을 사용한다면, 한글은 2바이트가 맞다.
- 그러나 UTF-8 인코딩을 사용한다면, 한글은 3바이트이다.
- 유니코드 체계에서는 완성형이라 할 수 있는 현대 한글 11,172자와 (공식적인 명칭은 한글 음절, Hangul Syllables) 조합형처럼 쓸 수 있는 한글 초중종성이 (공식 명칭은 한글 자모, Hangul Jamos) 옛한글까지 모두 포함되어 있어서 두 방식 모두 사용이 가능하다.
- Base64 인코딩이란?
- 유니코드 인코딩이란?
- 유니코드는 전 세계의 모든 문자를 다루도록 설계된 문자 인코딩 표준이다.
- UTF-8, UCS 등 다양한 인코딩 방식이 있다.
- 즉 UTF-8도 유니코드 인코딩의 일종이다.
- 유니코드 인코딩이란?
- UTF-8 인코딩이란?
- UTF-8이 가변 데이터인 것을 어떻게 알지?
- 아래와 같이 첫 번째 헤더의 1내용을 가지고 가변길이 체크 가능
- 두 번째 헤더부터는
10으로 시작하여 가변길이인 것을 확인- (000000-00007F)
0xxxxxxx - (000080-0007FF)
110xxxxx, 10xxxxxx - (000800-00FFFF)
1110xxxx, 10xxxxxx, 10xxxxxx - (010000-10FFFF)
11110xxx, 10xxxxxx, 10xxxxxx, 10xxxxxx
- (000000-00007F)
- 헤더의
110은,11-> 즉 2바이트 인코딩을 의미함. - 헤더의
1110은,111-> 즉 3바이트 인코딩을 의미함. - 헤더의
11110은,1111-> 즉 4바이트 인코딩을 의미함.
- UTF-8이 가변 데이터인 것을 어떻게 알지?
- 유니코드는 무엇이고 UTF-8은 무엇인가? (유니코드가 UTF-8을 의미하는 것인가? -> 아니다.)
- 유래
- 옛날옛적, 컴퓨터가 처음 세상에 나왔을 때, 영어와 몇가지 특수문자만 활용이 되었고, 이런 적은 문자를 컴퓨터에 저장하기 위해서 1byte(8bit)면 충분했다.(0~255) - ASCII 문자 시간이 흘러, 다른 국가의 언어들이 활용되었고, 해당 국가의 사람은 자신의 언어를 표시하고 싶어졌다. 그래서 1byte안에 임의대로 영어 대신에 자신의 나라 문자를 할당하여 사용하게 되었다. - 문자열셋의 춘추전국시대… 그러다, 인터넷이 발전되며 다른 나라 사람의 홈페이지를 들어갔더니 글자가 와장창 깨지는 상황이 발생한다. 호환이 되지 않는 것이다. 그리하여, 국제적으로 전세계 모든 언어를 표시할 수 있는 표준코드를 만들기로 하였다. 이것이 바로 유니코드(unicode)이다.
참고로, 한글
가는 유니코드로U+AC00이다. 왜냐고? 약속이라서.- UTF-8의 탄생
- 유니코드를 통해서 문자를 나타내는 코드는 정의되었다. 즉, 각 문자마다 인덱스가 정해졌다. 그럼 이 코드를 컴퓨터에 어떤 방식으로 저장할 것인가? 똑똑한 사람들이 인코딩하는 규칙을 정했는데, 그 중 한가지 방법이 UTF-8 방식이다. (UCS-2,UCS-4,UTF-32,UTF-16,UTF-8 등이 있음)
- 문자마다 적절한 바이트 수를 차지하도록 해서 다른 방식들보다 일반적으로 적은 용량을 쓰면서도 호환문제가 적은 UTF-8이 전세계적으로 가장 널리 사용된다.
- UTF-8은 어떻게 적은 메모리로 다양한 문자를 표현하는가?
- 유니코드는 거의 세계 모든 언어를 포함하지만, 대부분의 글자는 2Byte(U+0000~U+FFFF)를 사용해야해서, 알파벳 (기존 1byte만을 활용할 수 있었음)을 사용하는 문서에서는 데이터 양이 2배, 많게는 3배가 된다.
- 따라서 UTF-8에서는 2byte 혹은 3byte였던 유니코드에서 어떤 문자는 1byte로, 어떤 문자는 4byte로… 가변적인 길이로 문자를 인코딩한다.
-
가(U+AC00) 를 UTF-8로 인코딩해 보자.- 이것을 이진수로 변환하면
1010110000000000이다. -
AC00은 2바이트 최대 표현 문자 7FF 를 넘기므로, 3바이트 인코딩을 진행한다. (800 ~ FFFF 범위에 있음) - 위에서 나오는 인코딩 표를 참고해 3바이트 인코딩을 진행한다.
- 1110
1010, 10110000, 10000000이 된다. - 따라서
가는 UTF-8로 3바이트이다.
- 이것을 이진수로 변환하면
- 출처: https://velog.io/@goggling/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C%EC%99%80-UTF-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0
- 추상화란 무엇인가?
- 추상클래스는 어떤 상황에서 사용하는가?
- 공통 기능을 가지면서 구체적인 구현이 달라야 할 때
- 템플릿 메서드 패턴을 구현할 때
- 여러 클래스가 비슷한 구조를 가지지만 세부 구현이 다를 때
- 공통 메서드와 추상 메서드를 함께 제공하고 싶을 때
- 상속 관계에서 일정한 구조를 강제하고 싶을 때
- 의존성이란 무엇인가?
- 의존성 역전이란 무엇인가?
- 고수준 모듈이 저수준 모듈에 의존하면 안 되고, 둘 다 추상화에 의존해야 한다.
- 의존성 역전 사용 예시
- 코드의 유연성을 높이고 싶을 때
- 테스트하기 쉬운 코드를 만들고 싶을 때
- 외부 라이브러리나 프레임워크 변경에 대비하고 싶을 때
- 다양한 구현체를 갈아끼우고 싶을 때
- 의존성 역전이란 무엇인가?
- 추상클래스는 어떤 상황에서 사용하는가?
의존성 역전
- 의존성 역전 미사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 저수준 모듈
class MySQLDatabase:
def save(self, data):
print(f"MySQL에 저장: {data}")
# 고수준 모듈이 구체적인 클래스에 의존
class UserService:
def __init__(self):
self.db = MySQLDatabase() # 구체 클래스에 직접 의존
def create_user(self, user_data):
# 비즈니스 로직
processed_data = f"처리된 {user_data}"
self.db.save(processed_data)
- 의존성 역전 사용
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 추상화 (인터페이스)
class DatabaseInterface(ABC):
@abstractmethod
def save(self, data):
pass
# 저수준 모듈들이 추상화를 구현
class MySQLDatabase(DatabaseInterface):
def save(self, data):
print(f"MySQL에 저장: {data}")
class PostgreSQLDatabase(DatabaseInterface):
def save(self, data):
print(f"PostgreSQL에 저장: {data}")
# 고수준 모듈이 추상화에 의존
class UserService:
def __init__(self, database: DatabaseInterface):
self.db = database # 추상화에 의존
def create_user(self, user_data):
processed_data = f"처리된 {user_data}"
self.db.save(processed_data)
# 사용
mysql_db = MySQLDatabase()
user_service = UserService(mysql_db) # 의존성 주입
select / epoll (socket programming)
- select와 epoll의 차이점
- select
- POSIX 표준이라 크로스 플랫폼 지원 (Linux, macOS, Windows)
- fd_set 구조체를 사용해 파일 디스크립터 집합 관리
- 읽기/쓰기/예외 상황을 각각 다른 집합으로 관리
- 장점
- 호환성: 거의 모든 유닉스 계열 시스템에서 동작
- 단순함: 개념이 직관적이고 사용하기 쉬움
- 작은 규모: 소수의 연결을 다룰 때에는 충분히 효율적
- 단점
- 스케일링 한계: FD_SETSIZE 제한 (보통 1024개)
- 성능 문제: O(n) 복잡도로 모든 fd를 순회해야 함
- 메모리 복사: 매번 커널에 fd_set을 전달해야 함.
- 사용
- 크로스 플랫폼 코드가 필요할 때
- 동시 연결 수가 적을 때 (< 1000)
- 간단한 프로토타입이나 교육 목적
- 임베디드 시스템처럼 리소스가 제한적인 환경
- select로도 1024개가 넘는 연결을 관리할 수 있지만 권장하지 않음.
- 성능 저하: fd가 늘어날수록 선형적으로 느려짐
- 메모리 낭비: fd_set 크기가 커져서 매번 큰 데이터를 복사
- 시스템 한계: 일부 시스템에서는 FD_SETSIZE 변경이 제대로 동작하지 않을 수 있음
- 버그 위험: 라이브러리들이 기본 FD_SETSIZE를 가정하고 만들어져 있어 충돌 가능
1 2 3 4 5 6 7 8 9 10 11
// select가 O(n) 인 이유 // 전체 중에서 활성인 것 찾기 (탐색 필요) // [fd1][fd2][fd3]...[fd1000] -> 전체 스캔해서 체크 // select는 매번 이런 일을 해야 함 for(int fd = 0; fd <= max_fd; fd++) { if(FD_ISSET(fd, &readfds)) { // 활성 fd 찾으려면 모든 fd를 다 확인해야 함 handle_event(fd); } } // -> fd 개수에 비례해서 시간 걸림 (O(n))
- epoll
- Linux 전용 (커널 2.6부터)
- 이벤트 기반 I/O 알림
- Edge-triggered와 Level-triggered 모드 지원
- Edge-triggered
- “변화”를 알려줌.
- 새로운 데이터가 도착했을 때만 알림
- 한 번 알림 받으면 모든 데이터를 다 읽어야 함.
- 성능이 좋지만, 구현이 까다로움. 모든 데이터를 다 처리해야 함.
- Level-triggered
- “상태”를 알려줌.
- 데이터가 있는 동안 계속 알림
- 일부만 읽어도 다음 epoll_wait에서 또 알림 받음
- 구현이 쉽고 안전함. 실수해도 데이터를 안 잃어버림.
- Edge-triggered
- 장점
- 확장성: 수만 개의 연결도 효율적으로 처리
- 성능: O(1) 복잡도로 활성 이벤트만 반환
- 메모리 효율: 커널이 이벤트 테이블을 관리해서 중복 복사 없음
- 유연성: ET/LT 모드 선택 가능
- 단점
- 플랫폼 종속: Linux에서만 동작
- 복잡성: 개념이 좀 더 복잡하고 실수하기 쉬움
- 사용 사례
- 고성능이 필요한 서버 (nginx, Redis 등)
- 동시 연결 수가 많을 때 (> 1000)
- Linux 환경에서만 동작해도 될 때
- C10K 문제를 해결해야 할 때
- C10K = “10,000개 동시 연결”을 뜻함
- 1990년대 말 ~ 2000년대 초의 문제
- 웹 서버가 동시에 10,000명의 클라이언트를 처리하지 못함.
- 하드웨어는 충분했는데 소프트웨어 아키텍쳐가 문제
- 해결책: epoll, kqueue, IOCP, 비동기 I/O
1 2 3 4 5 6 7 8 9 10 11 12
// epoll이 O(1) 인 이유 // 활성인 것만 알려주기 (커널이 미리 준비) // 커널 이벤트 테이블 -> [활성_fd만] -> 유저에게 전달 // epoll은 커널이 미리 준비해둠 struct epoll_event events[MAX_EVENTS]; int ready = epoll_wait(epfd, events, MAX_EVENTS, -1); // 활성 이벤트만 바로 받아서 처리 for(int i = 0; i < ready; i++) { handle_event(&events[i]); // 이미 활성화된 것만 받음 } // -> 활성 이벤트 개수에만 비례 (보통 O(1)에 가까움)
- Apache 웹서버와 Nginx 웹서버
- Apache (아파치) 웹서버
- prefork MPM 또는 worker MPM 사용
- (MPM = Multi-Processing Module)
- 아파치 웹서버에서 여러 요청을 어떻게 처리할 것인가를 결정하는 모듈
- (MPM = Multi-Processing Module)
- prefork MPM
- 각 요청마다 별도의 프로세스
- 안정적이지만 메모리 많이 먹음
- select/poll 안 써도 됨. (각 프로세스가 하나씩만 처리)
- 2000~4000 동시 연결
- worker MPM
- 스레드 풀 사용
- prefork보다 메모리 효율적
- event MPM
- 이벤트 기반
- Apache 2.4 부터 기본
- epoll/kqueue 사용
- Keep-Alive 연결을 효율적으로 관리
- ~10000+ 동시 연결 (nginx와 비슷한 성능)
- prefork MPM 또는 worker MPM 사용
- Apache (아파치) 웹서버
- Nginx 웹서버
- 처음부터 이벤트 기반 아키텍쳐로 설계됨.
- ~ 50000+ 동시 연결
- 메모리 효율적
- 현재는 Apache도 event MPM으로 epoll을 사용할 수 있어 성능 차이가 예전만큼 크지 않음.
- 그러나 nginx가 처음부터 이벤트 기반으로 설계되어 있어 좀 더 최적화되어 있긴 하다.
cloud
- object storage
- 객체(object) 단위로 저장하는 스토리지 방식
- 기존의 파일 시스템이나 블록 스토리지와는 다른 접근법
- 핵심 개념
- 객체 구조
- 데이터: 실제 파일 내용(이미지, 동영상, 문서 등)
- 메타데이터: 파일 정보(생성일, 크기, 타입 등)
- 고유 ID: 각 객체를 식별하는 Unique key
- 플랫 구조
- 전통적인 폴더/디렉토리 계층 구조 없음
- 모든 객체가 “버킷(Bucket)” 안에 플랫하게 저장됨.
- 버킷: Object Storage에서 가장 상위 단위의 컨테이너 (큰 상자같은 개념)
- 전통적인 방식:
/home/user/documents/photos/2024/cat.jpg - 버킷 방식:
my-bucket/cat.jpg,my-bucket/my-company-backup-2024…
- 전통적인 방식:
- 버킷: Object Storage에서 가장 상위 단위의 컨테이너 (큰 상자같은 개념)
- URL같은 고유 주소로 접근함.
- 객체 구조
- 장점
- 확장성
- 사실상 무제한 용량
- 필요한 만큼 자동으로 확장
- 내구성
- 여러 데이터센터에 복제해서 저장
- 99.99.999999999% (11.9’s) 내구성 보장
- 다중 복제 (기본 3-way 복제)
- 단일 디스크 고장률: 1% (연간)
- 3개 복제본이 모두 동시에 망가질 확률: 0.01**3 = 0.000001 (0.0001%)
- 지리적 분산
- 서로 다른 데이터센터에 복제본 저장
- 자연재해, 정전 등 지역적 장애 대응
- AWS는 최소 3개의 가용영역(AZ)에 분산
- 에러 감지 및 자동 복구
- 체크섬 검증
- 데이터 읽을 때마다 무결성 검사
- 손상 감지 시 다른 복제본에서 자동 복구
- 백그라운드에서 지속적인 데이터 스크리밍
- 체크섬 검증
- 하드웨어 중복성
- RAID 구성으로 디스크 레벨 보호
- 이중화된 전원, 네트워크
- 서버 레벨 중복성
- 다중 복제 (기본 3-way 복제)
- 접근성
- HTTP REST API로 어디서든 접근 가능
- 웹에서 직접 파일 서빙 가능
- 확장성
- 주요 클라우드 서비스들
- AWS S3 (Simple Storage Service)
- Google Cloud Storage
- Azure Blob Storage
- 네이버 클라우드 Object Storage
- 언제 쓰면 좋을까?
- 정적 웹사이트 호스팅
- 백업 및 아카이빙
- 빅데이터 저장
- CDN 원본 스토리지
- 이미지/동영상 같은 미디어 파일 저장
- 배경
- 전통적인 스토리지의 한계
- 파일 시스템 (NFS, CIFS)의 문제점
- 계층적 폴더 구조로 인한 복잡성
- 단일 서버 의존성 -> 확장이 어려움
- 네트워크 지연에 민감
- 블록 스토리지(SAN)의 문제점
- 설정과 관리가 너무 복잡
- 하드웨어 비용이 엄청남
- 확장할 때마다 큰 투자 필요
- 웹의 폭발적 성장
- 새로운 요구사항들
- 전 세계 어디서든 빠른 접근 필요
- 이미지, 동영상 같은 멀티미디어 급증
- 사용자 생성 콘텐츠 폭증(Youtube, Flickr 등)
- 아마존의 현실적 문제
- 전 세계 이커머스 운영
- 수백만 개의 상품 이미지 저장/서빙 필요
- 피크 시즌 (블랙프라이데이) 트래픽 급증
- 새로운 요구사항들
- 클라우드 컴퓨팅의 필요성
- 아마존이 S3를 만든 이유(2006년)
- 자체 인프라 문제 해결이 목적
- “무제한 확장 가능 스토리지” 필요
- API를 통한 프로그래밍 방식 접근
- 아마존이 S3를 만든 이유(2006년)
- 빅데이터 시대의 도래
- 데이터 폭증
- 로그 파일, 센서 데이터 급증
- 비정형 데이터(이미지, 동영상, 문서) 증가
- 정형 데이터
- 미리 정의된 스키마(구조)가 있음.
- 행과 열로 깔끔하게 정리됨.
- 데이터 타입이 명확함
- SQL로 쉽게 검색/분석 가능
- 비정형 데이터
- 미리 정의된 구조가 없음
- 각 파일마다 형태가 다름
- 내용을 이해하려면 특별한 처리 필요
- 크기가 매우 다양함
- 정형 데이터
- 기존 DB로는 비용/성능 한계
- 데이터 폭증
- REST API와 HTTP의 성숙
- 웹 표준 활용
- HTTP/REST API를 통한 단순한 접근
- 기존 웹 기술과 자연스러운 통합
- 개발자들이 쉽게 사용 가능
- 웹 표준 활용
- 전통적인 스토리지의 한계
- 파일시스템과 네트워크 파일 시스템
- SAN?
- 분산 파일 시스템(HDFS, Ceph)
- 실시간 공동 편집 기술
- 파일 블록이란?
- 파일을 어떻게 디스크에 저장하는가? 어떤 블록 단위로 쪼개져 저장하는가?
- IaaS (Infrastructure as a Service)
- 가상의 컴퓨터를 빌려주는 서비스
- 제공하는 것
- 가상 서버(CPU, Memory, Storage)
- 네트워크 설정
- 기본 하드웨어 인프라
- 해야할 일
- 운영체제 설치/관리
- 미들웨어 설치(DB, 웹서버 등)
- 애플리케이션 개발/배포
- 보안 패치, 백업 등
- Example
- AWS EC, Google Computer Engine, Azure VM
- 빈 컴퓨터 한대 줌. 나머진 니가 다 해
- PaaS (Platform as a Service)
- 개발 플랫폼을 통째로 제공하는 서비스
- 제공하는 것
- IaaS + 운영체제 + 런타임 환경
- 데이터베이스, 웹서버 등 미들웨어
- 개발/배포 도구
- 해야할 일
- 애플리케이션 코드만 작성
- 배포 (보통 git push 수준)
- Example
- Heroku, Google App Engine, Azure App Service
- 코드만 올려, 나머진 우리가 다 해줌.
- SaaS (Software as a Service)
- Software as a Service
- 제공하는 것
- 완전히 동작하는 애플리케이션
- 모든 인프라 + 플랫폼 + 소프트웨어
- 해야할 일
- 그냥 사용하기만 하면 됨
- 설정 정도만 변경
- Example
- Gmail, Notion, Slack, Salesforce
- 이미 다 만들어진 서비스임. 그냥 써라.
- 그럼 Object Storage는 IaaS인가 SaaS인가?
- 인프라스트럭쳐 레벨의 기본 구성 요소(Storage 대여)
- 다른 서비스들이 위에 올라가는 기반
- 개발자가 직접 통합해서 사용해야 함.
- 그러나 완전 관리형이라는 특성 때문에 전통적인 IaaS(서버 관리)와는 조금 다른 느낌.
- 그래서 요즘에는 Storage as a Service 라고 따로 부르는 추세임.
- StaaS: Storage as a Service
- 저장소만 딱 떼어서 서비스로 제공
- 전통적인 서버: CPU + Memory + 스토리지 + 네트워크 (묶음 패키지)
StaaS: 스토리지만 독립적으로 제공
- Object Storage
- AWS S3
- Google Cloud Storage
- Azure Blob Storage
- 네이버 클라우드 Object Storage
- HTTP API로 파일 저장/조회
- Block Storage
- AWS EBS (Elastic Block Store) (볼륨)
- Google Persistent Disk
- Azure Managed Disks
- 가상 하드디스크처럼 동작
- File Storage
- AWS EFS (Elastic File System)
Google Filestore
- 네트워크 파일 시스템(NFS/SMB)
- Block Storage
- 전통적인 파일 시스템처럼 (디스크에 파일을 저장하는것처럼) 동작
- 고정 크기 블록으로 나눠서 저장
- 특징
- 블록 단위
- 작은 조각들로 나눠서 저장
- 파일 시스템 필요
- NTFS, ext4 등이 블록을 파일로 변환
- 서버 종속적
- 특정 서버에 연결해서 사용
- 블록 단위
- 확장성 낮음
- 수동 용량 증설
- 연결된 서버에서만 접근
- 장점
- 낮은 지연시간
- 높은 IOPS
- 파일 시스템 가능 (권한, 링크 등)
- 실시간 편집 가능
- 단점
- 용량 제한 (확장성 낮음)
- 수동 용량 증설
- 단일 서버 종속
- 연결된 서버에서만 접근
- 수동 백업 필요
- 글로벌 접근 어려움
- 용량 제한 (확장성 낮음)
- 전통적인 파일 시스템처럼 (디스크에 파일을 저장하는것처럼) 동작
- 각 Storage 성능 비교
- Object Storage (ex: 온라인 사진 서비스)
- 처리량(Throughput) 최적화
- 동시 접근에 강함 (WORM - Write Once, Read Many 패턴에 최적화)
- 여기서 말하는 동시접근이란
- 전 세계 어디서든 접근
- 무제한 동시 연결
- 자동 스케일링
- 글로벌 캐시 활용
- 읽기 작업에 특화됨
- 캐시와 CDN으로 읽기 성능 극대화
- 쓰기 작업은 복잡하고 제한적
- 따라서 Object Storage로 Google Docs와 같은 공유 문서 편집 서비스 등은 구현 불가능하다. ``` 파일 업데이트 후 전파 과정: ├── 0초: 서울 서버에 업로드 완료 ├── 1초: 부산 서버에 복제 중… ├── 2초: 도쿄 서버에 복제 중… ├── 3초: 싱가포르 서버에 복제 완료 └── 5초: 전 세계 모든 서버에 전파 완료
이 사이에 파일 읽으면? ├── 서울 사용자: 새 버전 ✅ ├── 도쿄 사용자: 구 버전 ❌ (아직 전파 안됨) └── 몇 초 후 모두 일치 ```
- 여기서 말하는 동시접근이란
- 지연 시간은 상대적으로 높음
- Block Storage (ex: 외장 하드디스크)
- 지연시간(Latency) 최적화
- 직접 메모리 접근 (DMA)
- DMA: Direct Memory Access
- CPU 개입없이 메모리 접근하는 기법. CPU를 대신하여 I/O장치와 Memory사이의 데이터전송을 담당하는 장치를 지칭
- 애플리케이션 → 커널 → 디스크 드라이버 → 물리 디스크
- 중간 변환 과정 없음
- DMA: Direct Memory Access
- 블록 레벨 최적화
- 직접 메모리 접근 (DMA)
- 순차/랜덤 읽기 빠름
- IOPS (초당 입출력) 높음
- 지연시간(Latency) 최적화
- Object Storage (ex: 온라인 사진 서비스)
- 디스크의 기본 구조
- 하드디스크
- 섹터
- 512바이트 (가장 작은 단위)
- 하드웨어 최소 단위
- 클러스터
- 여러 섹터 묶음(4KB, 8KB 등)
- Windows에서 관리하는 단위 (블록과 동일 개념)
- 블록
- 파일 시스템이 사용하는 단위
- 파일
- 여러 블록의 조합
- 섹터
- HDD (하드디스크):
- 물리적 회전 디스크
- 섹터 단위로 읽기/쓰기
- 순차 접근이 빠름
- 기계적 지연시간 존재
- SSD (솔리드 드라이브):
- 플래시 메모리
- 페이지/블록 단위 (4KB-16KB)
- 랜덤 접근 빠름
- 기계적 부품 없음
1 2 3 4 5 6 7 8 9 10
# 10KB 파일을 저장한다면 file_size = 10240 # 10KB block_size = 4096 # 4KB (일반적인 블록 크기) required_blocks = math.ceil(file_size / block_size) # 10240 ÷ 4096 = 2.5 → 3개 블록 필요 블록 할당: ├── 블록 1: 4096 바이트 (꽉 참) ├── 블록 2: 4096 바이트 (꽉 참) └── 블록 3: 2048 바이트 (절반만 사용, 나머지는 빈 공간)
-
블록 할당 방식
블록 100 | 블록 101 | 블록 102-
[파일A-1] [파일A-2] [파일A-3]→ 순차적으로 읽기 빠름 - 분산 할당 (현실적)
블록 100 블록 205 블록 67 - [파일A-1] [파일A-2] [파일A-3] → 디스크 헤드가 이리저리 움직임 (느림)
FAT32 방식 ``` 파일 할당 테이블 (FAT): 블록 번호 | 다음 블록 | 상태 100 | 205 | 사용중 (파일A) 205 | 67 | 사용중 (파일A)
101 | 102 | 사용중 (파일B) 102 | EOF | 사용중 (파일B 끝)
1
- NTFS/ext4 같은 현대 파일시스템
inode (파일 메타데이터): ├── 파일 크기: 10240 바이트 ├── 생성 시간: 2024-01-15 10:30:00 ├── 권한: rwxr–r– ├── 블록 포인터들: │ ├── 직접 포인터: [100, 205, 67] │ ├── 간접 포인터: [큰 파일용] │ └── 이중 간접 포인터: [아주 큰 파일용]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
- 실제 저장 과정 시뮬레이션 ```py file_content = "Hello World!\n" # 13 바이트 block_size = 4096 # 4KB # 1. 빈 블록 찾기 free_block = find_free_block() # 예: 블록 456 # 2. 데이터 쓰기 disk_blocks[456] = [ 'H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd', '!', '\n', 0, 0, 0, 0, 0, 0, 0, 0, ... # 나머지 4083바이트는 0으로 패딩 ] filesystem_table["hello.txt"] = { "size": 13, "blocks": [456], "created": "2024-01-15 10:30:00" }- 큰 파일 예시 ```py file_size = 100 * 1024 * 1024 # 100MB block_size = 4096 # 4KB
blocks_needed = 100MB ÷ 4KB = 25,600개 블록
allocated_blocks = [ 1000, 1001, 1002, 1003, # 연속된 4개 5678, 5679, # 점프해서 2개 12345, # 또 점프해서 1개 8901, 8902, 8903, # 또 다른 위치에 3개 … # 25,600개까지 ]
파일 시스템이 이 정보를 관리
filesystem_table[“video.mp4”] = { “size”: 104857600, “blocks”: allocated_blocks, “fragmented”: True # 조각화됨 }
- 조각모음의 필요성
- 조각화된 파일을 읽을 때 ``` 디스크 레이아웃 (블록 번호): [100][101][102][103][104][105][106][107][108][109] [A-1][B-1][A-2][B-2][A-3][B-3][C-1][A-4][C-2][B-4]
파일 A 읽기: 블록 100 → 블록 102 → 블록 104 → 블록 107 (디스크 헤드가 4번 점프)
1
- 조각모음 후
[100][101][102][103][104][105][106][107][108][109] [A-1][A-2][A-3][A-4][B-1][B-2][B-3][B-4][C-1][C-2]
파일 A 읽기: 블록 100 → 블록 101 → 블록 102 → 블록 103 (순차적 읽기, 빠름!) ```
- 블록 크기의 중요성
- 작은 블록 크기 (1KB)
- 장점
- 작은 파일에 공간 낭비 적음
- 메모리 효율적
정밀한 할당
- 큰 파일 → 블록 개수 많음 → 관리 복잡
- 메타데이터 오버헤드 증가
- 성능 저하
- 장점
- 큰 블록 크기 (64KB)
- 장점
- 큰 파일 처리 효율적
- 순차 읽기 성능 좋음
- 메타데이터 적음
- 단점
- 작은 파일도 64KB 차지 (공간 낭비)
- 내부 단편화 심함
- 메모리 사용량 증가
- 장점
- 작은 블록 크기 (1KB)
- 리눅스에서 확인 방법
- 리눅스 블록정보 확인 명령어
sudo fileflag -v <filepath>
- 리눅스 블록정보 확인 명령어
- 최신기술 Copy-on-Write
- 전통적 방식
- 파일 수정 시
- 기존 블록 읽기
- 메모리에서 수정
- 같은 블록에 덮어쓰기 → 수정 중 전원 꺼지면 데이터 손상 위험
- 파일 수정 시
- CoW (Copy-on-Write) 방식 (Btrfs, ZFS)
- 파일 수정 시
- 새로운 빈 블록에 수정된 내용 쓰기
- 메타데이터 포인터 변경 (원자적 연산)
- 기존 블록은 나중에 정리 → 항상 일관된 상태 유지
- 파일 수정 시
- 전통적 방식
- 파일 → 블록 변환 과정:
- 파일 크기 계산 → 필요한 블록 수 결정
- 빈 블록 찾기 → 디스크에서 사용가능한 영역 탐색
- 데이터 분할 → 파일을 블록 크기로 잘라서 저장
- 메타데이터 기록 → 어떤 블록들이 어떤 파일인지 기록
- 링크 관리 → 블록들을 순서대로 연결하는 정보 저장
- 하드디스크
C언어의 const 키워드
-
const char *ptr;- 포인터가 가리키는 내용을 수정할 수 없음.
- 포인터 자체는 다른 곳을 가리킬 수 있음.
1 2 3
const char *ptr = "hello"; ptr = "world"; // O 가능 - 포인터 재할당 OK ptr[0] = 'H'; // X 불가능 - 가리키는 내용 수정 불가
-
char * const ptr;- 포인터 자체를 다른 곳으로 변경할 수 없음
- 포인터가 기리키는 내용은 수정 가능
1 2 3 4
char str[] = "hello"; char * const ptr = str; ptr = "world"; // ❌ 불가능 - 포인터 재할당 불가 ptr[0] = 'H'; // ✅ 가능 - 가리키는 내용 수정 OK
-
const char * const ptr = "Hello";- 둘 다 수정 불가
Interrupt와 Polling
- Interrupt
- 하드웨어 신호 기반
- 제어주체: 인터럽트
1 2
하드웨어: 님, 중요한 일 있음!! CPU: 뭐임?
- 타이밍: 이벤트 기반 (인터럽트의 이벤트가 발생했을 때)
- 복잡도 및 예측성: 복잡하고(컨텍스트 스위칭 등), 예측 불가 (이벤트 기반)
- 장점
- CPU 효율성 극대화
- 즉각적인 응답
- 전력 절약
- 확장성이 좋음
- 단점
- 인터럽트 오버헤드
1 2 3 4 5 6
# 인터럽트 발생 시 과정 1. 현재 작업 중단 2. 컨텍스트 저장 (레지스터 스택 등) 3. 인터럽트 핸들러 실행 4. 컨텍스트 복원 5. 원래 작업 재개
- 하드웨어 복잡성
- 인터럽트 컨트롤러 필요
- 신호선, 우선순위 회로 등 추가 하드웨어
- 동기화 문제
- 인터럽트 스톰
- 너무 많은 인터럽트 -> CPU 마비
- 네트워크 카드에서 패킷이 쏟아질 때 자주 발생함.
- 인터럽트 오버헤드
- 사용 사례
- 마우스/키보드
1 2
사용자: 클릭 시스템: 바로 처리
- 네트워크 카드
1
패킷 도착 -> 인터럽트 -> 즉시 처리
- 타이머
- 마우스/키보드
- Polling
- 계속 물어보기 방식
- CPU가 주기적으로 하드웨어의 상태 레지스터를 확인
1 2
CPU: 뭐 있음? 하드웨어: ㅇㅇ/ㄴㄴ
- Polling: 주기적 확인
- 복잡도 및 예측성: 단순(순차 실행) 하고 예측 가능 (주기적)
- 장점
- 구현의 단순
- 예측 가능한 동작
- 언제 체크할지 정확히 알 수 있음
- 실시간 시스템에서 jitter 적음
- jitter: 예상한 시간에서 벗어나는 정도
- 인터럽트 지터, 네트워크 지터 등이 존재
- 인터럽트 지터 ``` // 예상: 1ms마다 타이머 인터럽트 void timer_interrupt() { current_time = get_time(); printf(“인터럽트 발생: %d ms\n”, current_time); }
// 실제 출력: 인터럽트 발생: 1000 ms (예상: 1ms, 실제: 0ms 지터) 인터럽트 발생: 2001 ms (예상: 2ms, 실제: 1ms 지터) 인터럽트 발생: 2998 ms (예상: 3ms, 실제: -2ms 지터) 인터럽트 발생: 4003 ms (예상: 4ms, 실제: 3ms 지터)
1
- 네트워크 지터
ping 테스트 결과
PING google.com (8.8.8.8) 64 bytes from 8.8.8.8: time=20.1ms ← 평균 20ms 64 bytes from 8.8.8.8: time=19.8ms ← -0.3ms 지터 64 bytes from 8.8.8.8: time=22.5ms ← +2.4ms 지터 64 bytes from 8.8.8.8: time=18.9ms ← -1.2ms 지터
지터 = 각 측정값 - 평균값의 변동
```
- jitter: 예상한 시간에서 벗어나는 정도
- 하드웨어 요구사항 적음
- 인터럽트 지원 불필요
- 저가 마이크로컨트롤러에 적합
- 동기화 문제 적음
- 메인 루프에서 순차적으로 처리함.
- race condition 위험 감소
- 단점
- CPU 낭비 심각
- 응답 지연
- 배터리 드레인
- 모바일 기기에서 치명적
- 계속 CPU가 돌아감 -> 전력 소모 증가
- 다른 작업 방해
- 폴링은 작업을 모니터링하기 때문에 CPU 지속 사용
- 폴링에 CPU를 지속 사용함으로 인해 CPU 독점 현상 발생
- 사용 사례
- 게임 컨트롤러
1
게임 루프에서 매 프레임마다 체크
- 센서 모니터링
- 온도는 급격하게 변하지 않으므로 n분마다 체크해도 충분함.
- 게임 컨트롤러
- 하이브리드 접근법
- 실제로는 두 방식을 조합해서 사용함.
- Interrupt Coalescing
1 2 3
# 네트워크 카드에서 패킷_1개_도착 → 잠깐_대기 패킷_10개_모임 → 인터럽트_발생 # 오버헤드 감소
- Polling with Sleep
- Adaptive Polling
- Interrupt Coalescing
- 실제로는 두 방식을 조합해서 사용함.
- kipmi0 프로세스?
- 주요 특징
- IPMI (Intelligent Platform Management Interface) 커널 헬퍼 스레드
- IPMI 인터페이스 처리
- 시스템의 IPMI 컨트롤러와 통신하는 커널 스레드
- BMC (Baseboard Management Controller) 와의 상호작용 담당
- 폴링 매커니즘
- KCS (Keyboard Control Style) 나 SMIC (System Management Interface Chip) 같은 인터페이스는 IRQ를 사용하지 않음.
- 대신 폴링 방식으로 명령 결과를 확인해야 함.
- kipmi 가 이 폴링 작업을 수행
- CPU 사용량 문제
- IPMI 작업이 진행중일 때 상당한 CPU 시간을 소모할 수 있음
- 하드웨어/펌웨어와 드라이버 간 상호작용 문제로 높은 CPU 로드가 지속될 수 있음.
- 해결 방법
- 파라메터 튜닝
ipmi_si.kipmid_max_busy_us=500
- 프로세스 확인
ps -l ax | grep ipmi
- 모듈 비활성화 (필요 시)
rmmod ipmi_si
- 파라메터 튜닝
- 정상적인 동작
- 낮은 우선순위로 실행되어 시스템에 큰 영향은 주지 않음
- 시스템 모니터링, 센서 데이터 수집, 전원 관리 등에 필요
- 서버 환경에서는 하드웨어 관리를 위해 중요한 역할
- 주요 특징
- IPMI (Intelligent Platform Management Interface)
- 서버 관리용 표준 인터페이스
- 주요 기능
- 서버가 꺼져 있어도 팬 속도 등 하드웨어 센서 모니터링
- 온도, 전압, 팬 속도 등 하드웨어 센서 모니터링
- 원격 전원 켜기/끄기
- 시스템 로그 확인
- 원격 콘솔 접속 (KVM over IP 같은)
- 실제 사용 예시
1 2 3 4 5
# IPMI 명령어 예시 ipmitool power status # 전원 상태 확인 ipmitool power on # 원격 전원 켜기 ipmitool sensor list # 센서 정보 확인 ipmitool chassis status # 시스템 상태 확인
- BMC (Baseboard Management Controller)
- 서버 메인보드에 있는 작은 컴퓨터
- 특징
- 메인 CPU와 별개로 동작하는 독립적인 마이크로 컨트롤러
- 메인 시스템이 꺼져도 계속 동작 (별도 전원 공급)
- 자체 CPU, 메모리, 네트워크 인터페이스 보유
- 리눅스나 임베디드 OS 실행
- 비유
- 메인 시스템: 아파트
- BMC: 아파트 관리사무소
- 아파트 전체가 정전되어도 관리사무소는 별도의 전원으로 계속 운영
IRQ (Interrupt ReQuest)
- Interrupt Request
- 하드웨어가 CPU에게 보내는 신호
- CPU에게 나좀 봐달라고 하드웨어가 보내는 신호
1 2 3
하드웨어 장치 → IRQ 신호 → CPU ↓ ↓ ↓ "키 눌렸어!" "인터럽트!" "알겠어!"
- IRQ 번호 시스템
- 리눅스에서 각 하드웨어마다 고유 번호 존재
1 2 3 4 5 6 7 8 9
# /proc/interrupts 파일로 확인 가능 cat /proc/interrupts CPU0 CPU1 CPU2 CPU3 0: 23 0 0 0 IO-APIC 2-edge timer 1: 9 0 0 0 IO-APIC 1-edge i8042 8: 1 0 0 0 IO-APIC 8-edge rtc0 9: 0 0 0 0 IO-APIC 9-fasteoi acpi 12: 156 0 0 0 IO-APIC 12-edge i8042 16: 1234 23 45 67 IO-APIC 16-fasteoi ehci_hcd
- 전통적인 IRQ 할당
- 사용 가능한 IRQ가 단 16개 뿐 (0~15)
- 또한 실제로 자유롭게 사용할 수 있는 IRQ는 9,10,11 뿐
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
IRQ 0: 시스템 타이머 IRQ 1: 키보드 IRQ 2: 캐스케이드 (다른 IRQ 컨트롤러 연결) IRQ 3: COM2 (시리얼 포트) IRQ 4: COM1 (시리얼 포트) IRQ 5: LPT2 (프린터 포트) IRQ 6: 플로피 디스크 IRQ 7: LPT1 (프린터 포트) IRQ 8: 실시간 시계 (RTC) IRQ 9: ACPI IRQ 10: 사용 가능 IRQ 11: 사용 가능 IRQ 12: PS/2 마우스 IRQ 13: 수학 보조프로세서 IRQ 14: 첫 번째 IDE 컨트롤러 IRQ 15: 두 번째 IDE 컨트롤러
- PCI 시대 (IRQ 공유 매커니즘)
- PCI는 IRQ 공유가 가능하도록 설계됨
1 2 3 4 5
# PCI 슬롯별 기본 IRQ 할당 (인텔 칩셋 기준) PCI 슬롯 1: IRQ 11 (INTA#) PCI 슬롯 2: IRQ 10 (INTB#) PCI 슬롯 3: IRQ 9 (INTC#) PCI 슬롯 4: IRQ 11 (INTD#) ← 슬롯1과 동일!
- 확인 방법
1 2 3 4 5 6 7 8 9
# 마더보드에 온보드 사운드 (IRQ 11 사용) # PCI 슬롯 1에 네트워크 카드 설치 → 또 IRQ 11! lspci -v 00:1f.5 Multimedia audio controller: Intel Corporation Interrupt: pin A routed to IRQ 11 02:01.0 Ethernet controller: Realtek Semiconductor Interrupt: pin A routed to IRQ 11 ← 충돌!
- PCI는 IRQ 공유가 가능하도록 설계됨
- 네트워크 카드 IRQ 번호
- 전통적인 할당
- 9, 10, 11
- 일반적으로는 11이 가장 평균
- 현대적인 할당 (MSI/MSI-X 시대)
1 2 3 4 5 6 7 8
# 현재 시스템에서 확인 cat /proc/interrupts | grep -i eth # 예시 출력: 16: 12345678 PCI-MSI-edge eth0 ← IRQ 16 17: 87654321 PCI-MSI-edge eth0-TxRx-0 ← IRQ 17 18: 11111111 PCI-MSI-edge eth0-TxRx-1 ← IRQ 18 19: 22222222 PCI-MSI-edge eth0-TxRx-2 ← IRQ 19
- 실제 네트워크 카드별 IRQ 확인
1 2 3 4 5 6 7 8 9 10 11 12 13 14
# 방법 1: lspci로 확인 lspci -vv | grep -A 20 "Ethernet" 02:00.0 Ethernet controller: Intel Corporation I350 Gigabit Interrupt: pin A routed to IRQ 24 ← 실제 IRQ 번호 # 방법 2: /proc/interrupts로 확인 cat /proc/interrupts | grep -E "(eth|enp)" 24: 123456789 PCI-MSI-edge enp2s0f0 25: 987654321 PCI-MSI-edge enp2s0f1 # 방법 3: 네트워크 인터페이스별 확인 grep . /sys/class/net/*/device/irq 2>/dev/null /sys/class/net/eth0/device/irq:24 /sys/class/net/eth1/device/irq:25
- 전통적인 할당
- IRQ 할당 메커니즘
- BIOS/UEFI 자동 할당
1 2 3 4 5 6 7
# 부팅 시 BIOS가 자동으로 IRQ 할당 # PCI 장치 검색 → 사용 가능한 IRQ 찾기 → 할당 # dmesg로 할당 과정 확인 dmesg | grep -i "irq.*assign" [ 0.234567] pci 0000:02:00.0: PCI INT A -> IRQ 24 [ 0.345678] pci 0000:02:00.1: PCI INT B -> IRQ 25
- 리눅스 커널의 IRQ 관리
1 2 3 4 5 6 7
# 커널이 IRQ 할당 조정 # ACPI 정보 참조 → 최적 IRQ 선택 → 장치에 할당 # ACPI IRQ 라우팅 테이블 확인 cat /proc/acpi/interrupts GEN0: 0 EN acpi-event GEN1: 0 EN acpi-event
- BIOS/UEFI 자동 할당
-
실제 동작 과정
1 2 3 4 5 6 7
# 사용자가 'A' 키를 누름 1. 키보드 하드웨어: "A키 눌림 감지" 2. 키보드 컨트롤러: "IRQ 1 신호 발생" 3. CPU: "IRQ 1 받음, 현재 작업 중단" 4. CPU: "키보드 인터럽트 핸들러 실행" 5. 핸들러: "A 문자 처리 완료" 6. CPU: "원래 작업으로 복귀"
- 하드웨어 레벨에서
1 2 3
키보드 ----IRQ 1----> 인터럽트 컨트롤러 -----> CPU 마우스 ----IRQ 12---> 인터럽트 컨트롤러 -----> CPU 타이머 ----IRQ 0----> 인터럽트 컨트롤러 -----> CPU
- 리눅스에서 각 하드웨어마다 고유 번호 존재
- IRQ 확인 및 관리 방법
- 현재 IRQ 상태 확인
1 2 3 4 5 6 7
# IRQ 사용 현황 보기 cat /proc/interrupts # 특정 IRQ 정보 확인 grep "keyboard\|i8042" /proc/interrupts 1: 1823 0 0 0 IO-APIC 1-edge i8042 12: 156 0 0 0 IO-APIC 12-edge i8042
- IRQ 충돌 확인
1 2
# 같은 IRQ를 여러 장치가 사용하는지 확인 cat /proc/interrupts | awk '{print $1}' | sort | uniq -d
- IRQ 밸런싱
1 2 3 4 5
# CPU별 IRQ 분산 상태 확인 cat /proc/irq/*/smp_affinity # 특정 IRQ를 특정 CPU에 할당 echo 2 > /proc/irq/16/smp_affinity # IRQ 16을 CPU 1에 할당
- IRQ 문제 및 해결 방법
- IRQ 충돌 (IRQ Conflict)
- 증상: 장치가 제대로 동작하지 않음
- 원인: 두 장치가 같은 IRQ 사용
- 해결책
- BIOS에서 IRQ 재할당
- 장치 드라이버 재구성
- 하드웨어 슬롯 변경
- 예시
1 2 3 4 5 6 7
# 동시에 두 장치에서 이벤트 발생 네트워크 카드: "패킷 왔어!" → IRQ 11 발생 사운드 카드: "오디오 버퍼 비었어!" → IRQ 11 발생 (동시에!) CPU: "어? IRQ 11인데 누가 보낸 거지?" "네트워크 핸들러 실행" → 사운드 이벤트 놓침 "사운드 핸들러 실행" → 네트워크 패킷 놓침
- IRQ 충돌 (IRQ Conflict)
- IRQ 스톰 (IRQ Storm)
- 증상: CPU 사용률 급증, 시스템 느려짐
- 원인: 특정 IRQ가 너무 자주 발생
- 확인 방법
1
watch -n 1 'cat /proc/interrupts | head -20'
- 해결 방법
1
echo 0 > /proc/irq/16/smp_affinity # 문제되는 IRQ 비활성화
- 높은 인터럽트 부하
- top에서 확인
- %hi (hardware interrupt) 수치가 높으면 문제
- 해결책
- 인터럽트 코일레싱 활성화
- NAPI 사용 (네트워크)
- MSI-X 인터럽트 사용
- IRQ 디버깅
- 인터럽트 통계 모니터링
1 2
# 1초마다 인터럽트 발생 횟수 확인 watch -n 1 'cat /proc/interrupts | grep -E "(CPU|eth0|timer)"'
- 특정 장치 IRQ 찾기
1 2 3 4 5 6 7
# 네트워크 카드 IRQ 확인 cat /proc/interrupts | grep eth0 16: 12345678 0 0 0 PCI-MSI-edge eth0 # USB 장치 IRQ 확인 cat /proc/interrupts | grep usb 23: 45678 0 0 0 PCI-MSI-edge xhci_hcd
- 실시간 IRQ 활동 모니터링
1 2
# sar 명령으로 인터럽트 통계 sar -I ALL 1 10 # 1초마다 10번 측정
- 인터럽트 통계 모니터링
- 최신 시스템의 IRQ
- MSI (Message Signable Interrupt)
1 2 3 4 5 6
# 전통적인 IRQ 핀 대신 메시지 방식 사용 # PCI Express에서 주로 사용 # 더 많은 인터럽트 지원 (2048개까지) # MSI 지원 확인 lspci -v | grep -i msi
- MSI-X
- MSI의 확장 버전
- 각 인터럽트마다 다른 메시지와 주소 사용
- 네트워크 카드, 스토리지에 주로 사용
- MSI (Message Signable Interrupt)
- IRQ 성능 최적화
- IRQ 어피니티 설정
1 2 3
# 네트워크 IRQ를 특정 CPU에 고정 echo 2 > /proc/irq/24/smp_affinity # CPU 1에 고정 echo 4 > /proc/irq/25/smp_affinity # CPU 2에 고정
- 인터럽트 쓰레딩
1 2
# 인터럽트 핸들러를 커널 스레드로 실행 echo 1 > /proc/irq/16/threaded
- IRQ 어피니티 설정
- 현재 IRQ 상태 확인
- IRQ vs 기타 인터럽트
- IRQ
- Hardware Interrupt
1 2
// 하드웨어가 발생시킴 키보드_누름 → IRQ 1 → keyboard_interrupt_handler()
- Hardware Interrupt
- Software Interrupt
1 2 3
// 소프트웨어가 발생시킴 int 0x80 // 시스템 콜 인터럽트 divide_by_zero // 예외 인터럽트
- NMI (Non-Maskable Interrupt)
1 2
// 차단할 수 없는 긴급 인터럽트 하드웨어_오류 → NMI → 즉시_처리 (무시 불가)
- IRQ
- IRQ 처리 과정
-
- 하드웨어 신호 발생
1 2 3 4 5
키보드 'A' 키룰 누르는 순간 키보드 하드웨어 -> 전기 신호 발생 -> IRQ 1 라인에 전압 변화 키보드 컨트롤러: "키 스캔 코드 0x1E 감지!" "IRQ 1 라인을 HIGH로 설정" "데이터를 0x60 포트에 저장" -
- 인터럽트 컨트롤러 처리
1 2 3 4 5
# PIC (Programmable Interrupt Controller) 또는 APIC 인터럽트 컨트롤러: "IRQ 1 신호 감지" "현재 CPU 상태 확인" "우선순위 검사" "CPU의 INTR 핀으로 신호 전송" -
- CPU 인터럽트 감지 ```
CPU가 현재 실행 중인 명령어
CPU: “mov eax, [ebx+4]” ← 현재 실행 중 “add eax, 10” ← 다음에 실행할 명령어
갑자기 INTR 핀에 신호!
CPU: “어? 인터럽트 신호네!” “현재 명령어 완료 후 인터럽트 처리하자” ```
- CPU 인터럽트 감지 ```
-
- 컨텍스트 저장 (Context Saving) ```
CPU가 현재 상태를 모두 저장
CPU: “현재 하던 일을 나중에 이어하려면…” “모든 레지스터 값을 스택에 저장해야 해”
; 하드웨어가 자동으로 수행 push eflags ; 플래그 레지스터 저장 push cs ; 코드 세그먼트 저장 push eip ; 명령어 포인터 저장
; 소프트웨어 인터럽트 핸들러가 수행 pushad ; 모든 범용 레지스터 저장 (eax,ebx,ecx,edx,esi,edi,esp,ebp) push ds ; 데이터 세그먼트 저장 push es ; 기타 세그먼트 저장 push fs push gs ```
- 컨텍스트 저장 (Context Saving) ```
- 인터럽트 벡터 테이블 참조
1 2 3
# CPU가 어떤 함수를 호출해야 하는지 찾기 CPU: "IRQ 1이니까... 인터럽트 벡터 테이블의 1번 확인" "아! 0x12345678 주소로 가야 하는구나"
- 인터럽트 벡터 테이블 참조
- 인터럽트 핸들러 실행
1 2 3
# 드디어 키보드 처리 함수 실행! CPU: "0x12345678 주소로 점프!" "이제 키보드 인터럽트 핸들러 실행"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
// 리눅스 커널의 키보드 인터럽트 핸들러 irqreturn_t keyboard_interrupt_handler(int irq, void *dev_id) { unsigned char scancode; // 1. 하드웨어에서 데이터 읽기 scancode = inb(0x60); // 포트 0x60에서 스캔코드 읽기 // 2. 스캔코드를 ASCII로 변환 char ascii = scancode_to_ascii(scancode); // 3. 키보드 버퍼에 저장 if (ascii) { keyboard_buffer[buffer_head++] = ascii; buffer_head %= BUFFER_SIZE; } // 4. 대기 중인 프로세스 깨우기 wake_up_interruptible(&keyboard_wait_queue); // 5. 인터럽트 처리 완료 신호 return IRQ_HANDLED; }
- 인터럽트 핸들러 실행
- 인터럽트 완료 신호
1 2 3
# 인터럽트 컨트롤러에게 처리 완료 알림 CPU: "키보드 처리 끝났어!" "인터럽트 컨트롤러야, End of Interrupt(EOI) 신호 보낼게"
- 인터럽트 완료 신호
- 컨텍스트 복원
1 2 3
# 저장했던 상태를 모두 복원 CPU: "이제 원래 하던 일로 돌아가자" "스택에서 레지스터 값들을 복원"
- 컨텍스트 복원
- 원래 실행으로 복귀
1 2 3
# 인터럽트 발생 전 상태로 완전 복귀 CPU: "아, 맞다! add eax, 10 명령어 실행하려던 중이었지" "계속 실행하자"
- 원래 실행으로 복귀
- 전과정 요약 (총 처리시간 약 2.9 마이크로초)
1 2 3 4 5 6 7 8 9 10 11 12 13
시간(ns) 단계 CPU 상태 0 키 입력 [사용자 프로그램 실행 중] 100 IRQ 신호 발생 [mov eax, [ebx+4] 실행] 200 CPU 감지 [명령어 완료 대기] 300 컨텍스트 저장 시작 [레지스터들을 스택에 저장] 800 컨텍스트 저장 완료 [저장 완료] 900 핸들러 함수 호출 [keyboard_interrupt_handler 시작] 1500 하드웨어 데이터 읽기 [inb(0x60) 실행] 2000 데이터 처리 [스캔코드 변환, 버퍼 저장] 2200 EOI 신호 전송 [인터럽트 컨트롤러에 완료 신호] 2300 컨텍스트 복원 시작 [스택에서 레지스터 복원] 2800 컨텍스트 복원 완료 [복원 완료] 2900 원래 프로그램 복귀 [add eax, 10 실행]
- 여러 IRQ 동시 발생 시
- 우선 순위 처리
1 2 3 4 5 6 7 8 9 10 11
// 동시에 여러 인터럽트 발생 IRQ 0 (타이머): 우선순위 0 (가장 높음) IRQ 1 (키보드): 우선순위 1 IRQ 3 (시리얼): 우선순위 3 IRQ 11 (네트워크): 우선순위 11 (가장 낮음) // 처리 순서 1. IRQ 0 (타이머) 먼저 처리 2. IRQ 1 (키보드) 처리 3. IRQ 3 (시리얼) 처리 4. IRQ 11 (네트워크) 마지막 처리
- 중첩 인터럽트
1 2 3 4 5 6 7 8 9 10
void timer_handler() { // 타이머 인터럽트 처리 중... // 더 높은 우선순위 인터럽트 발생 시 // 현재 핸들러도 중단되고 새로운 핸들러 실행 sti(); // 인터럽트 재활성화 (중첩 허용) // 타이머 처리 계속... }
- 우선 순위 처리
- 최적화 기법
- Bottom Half 기법
- 긴급한 작업만 빠르게 처리하고 나머지는 나중에 처리
- 인터럽트 코얼레싱
- 여러 인터럽트를 묶어서 처리
- Bottom Half 기법
-
- IRQ가 여러개 사용하는 이유
- 1개만 사용한다고 가정할 때
- 끔찍한 단일 IRQ 핸들러
1 2 3 4 5 6 7 8
if (check_timer_interrupt()) { ... } if (check_keyboard_interrupt()) { ... } if (check_mouse_interrupt()) { ... } if (check_hdd_interrupt()) { ... } if (check_network_interrupt()) { ... } if (check_sound_interrupt()) { ... } if (check_usb_interrupt()) { ... } ...
- 성능 재앙
- 매번 모든 장치를 확인해야 함.
1 2 3 4 5 6 7 8 9 10 11
# 키보드 하나 누를 때마다 시간: 0μs - 인터럽트 발생 "키보드에서 온 거야!" 시간: 1μs - 타이머 확인 "너야?" → "아니야" 시간: 2μs - 하드디스크 확인 "너야?" → "아니야" 시간: 3μs - 네트워크 확인 "너야?" → "아니야" 시간: 4μs - 사운드 확인 "너야?" → "아니야" 시간: 5μs - USB 확인 "너야?" → "아니야" 시간: 6μs - 키보드 확인 "너야?" → "응!" 시간: 7μs - 드디어 키보드 처리 시작... # 원래는 1μs면 끝날 일이 7μs나 걸림!
- 우선 순위 지옥
- 모든 인터럽트가 동일한 우선순위를 가짐 ```
끔찍한 시나리오
상황: 시스템 타이머(중요) + 키보드 입력 동시 발생
현재 방식 (IRQ 별도)
IRQ 0 (타이머): 최고 우선순위 → 즉시 처리 IRQ 1 (키보드): 낮은 우선순위 → 나중에 처리
단일 IRQ 방식
“타이머야 키보드야 둘 다 IRQ 0으로 와!” → 어떤 게 더 중요한지 구분 불가 → 타이머 처리 지연 → 시스템 시간 오차 발생
- 모든 인터럽트가 동일한 우선순위를 가짐 ```
- 동시 인터럽트 처리 불가
- 여러 장치에서 동시에 신호 발생
1 2 3 4 5 6 7 8 9 10 11
# 동시 상황: 네트워크 패킷 + 키보드 입력 + 마우스 클릭 # 현재 방식 (각각 다른 IRQ) IRQ 11 (네트워크): CPU 0에서 처리 IRQ 1 (키보드): CPU 1에서 처리 IRQ 12 (마우스): CPU 2에서 처리 → 병렬 처리 가능! # 단일 IRQ 방식 모든 장치 → IRQ 0 → 한 번에 하나씩만 처리 → 순차 처리만 가능, 성능 저하
- 여러 장치에서 동시에 신호 발생
- 매번 모든 장치를 확인해야 함.
- 끔찍한 단일 IRQ 핸들러
- 1개만 사용한다고 가정할 때
- 이벤트 루프?
- libuv?
비디오 코덱
- H.264, H.265, H.266
- H.264
- H.263의 두 배의 압축률을 가지는 것을 목표로 개발함.
- 실제로 두 배에 가까운 효율을 구현함.
- H.262와 H.263 모두를 대체할 만한 코덱으로, 압축률도 좋을뿐더러 비교적 낮은 비트레이트에서도 좋은 화질을 가빛짐
- 비디오 코덱임
- RTP (Real-Time Transport Protocol): 실시간 스트리밍에서 H.264 NAL 단위를 전송
- MPEG-TS (MPEG Transport Stream): 방송 및 스트리밍에서 사용
- MP4, MKV 등의 컨테이너 포맷: 파일 기반 저장 및 전송에 사용
- H.263의 두 배의 압축률을 가지는 것을 목표로 개발함.
- H.264
- 원본 비디오는 H.264 코덱으로 압축되어 NAL 유닛이라는 패킷으로 나뉨.
- NAL 유닛에는 I-프레임 (키프레임), P-프레임(예측프레임), B-프레임(양방향 예측 프레임) 등이 포함됨.
- I-프레임 (Intra-coded Picture)
- 완전히 독립적인 이미지로, 다른 프레임 없이도 디코딩 가능
- 참조 프레임으로 사용되며, 특히 IDR 프레임은 새로운 시퀀스의 시작점이 됨
- 압축률이 낮아 파일 크기가 크지만, 화질이 좋고 랜덤 액세스 포인트 역할을 함
- 주로 장면 전환이나 스트림 시작점에 사용됨
- P-프레임 (Predicted Picture)
- 이전 I-프레임이나 P-프레임을 참조해서 차이값만 인코딩함
- 움직임 벡터를 사용해서 이전 프레임과의 차이를 표현
- I-프레임보다 크기가 작아서(약 50% 수준) 효율적이지만, 독립적 디코딩 불가
- 단방향 예측만 사용해, 이전 프레임만 참조하는 특징이 있음
- B-프레임 (Bi-directional Predicted Picture)
- 이전 프레임과 이후 프레임 모두를 참조해 인코딩하는 양방향 예측 방식
- 가장 높은 압축률을 제공
- 복잡한 연산이 필요하고, 지연시간이 증가할 가능성
- 화질 대비 용량 효율이 가장 좋음
- I-프레임 (Intra-coded Picture)
- NAL 유닛에는 I-프레임 (키프레임), P-프레임(예측프레임), B-프레임(양방향 예측 프레임) 등이 포함됨.
I-B-B-P-B-B-P-B-B-I
- I프레임 먼저 디코딩
- P프레임 이후 디코딩
- 이후 참조 프레임 사이의 B프레임 디코딩
- 이후 다음 참조 프레임 디코딩 (연산)
실제 디코딩 순서 I(1) - P(4) - B(2) - B(3) - P(7) - B(5) - B(6) - I(10) - B(8) - B(9)
- RTP 패킷화
- H.264로 인코딩된 NAL 유닛들은 RTP 패킷으로 캡슐화됨.
- 각 RTP 패킷은 타임스탬프, 시퀀스번호, 페이로드 타입 등의 헤더 정보를 포함해 수신측에서 올바른 순서로 재생할 수 있게 해줌.
- 전송방식
- 단일 NAL 유닛 모드: 하나의 NAL 유닛이 하나의 RTP 패킷에 담김
- 집합 패킷(STAP): 여러 개의 작은 NAL 유닛들이 하나의 RTP 패킷에 담김
- 단편화 유닛(FU): 큰 NAL 유닛이 여러 RTP 패킷으로 나뉨
- 수신 및 디코딩
- 수신측에서 RTP 패킷을 받아 헤더 정보를 분석하고 패킷 손실이나 순서 문제를 처리함.
- RTP 패킷에서 H.264 NAL 유닛을 추출한 후 H.264 디코더로 원본 비디오를 복원함.
이 과정에서 RTCP(RTP Control Protocol)도 함께 사용되어 전송 품질 모니터링, 참가자 식별 등의 기능을 제공함. 네트워크 상황에 따라 비트레이트를 조절하는 적응형 스트리밍 기술도 많이 사용됨. 이는 RTP와 H.264의 조합에 추가적인 레이어를 더해서 구현하는 경우가 많음.
RTP (Real Time Transparent Protocol)
- 실시간 데이터 전송을 위한 프로토콜
- 주로 UDP 위에서 동작, 신속한 전송을 우선시
- 패킷에 타임스탬프, 시퀀스 번호를 포함해 패킷 손실, 지연, 지터 관리
- VoIP, 화상 회의, IPTV, 스트리밍 서비스 등에 널리 사용됨
- RTCP(RTP Control Protocol)과 함께 작동하여 QoS 모니터링 세션 관리를 제공 실시간성이 중요한 상황에서, 약간의 데이터 손실은 허용되지만, 지연이 적어야 하는 애플리케이션에 적합함. TCP의 재전송과 같은 신뢰성 기능보다, 시간적 특성이 더 중요한 경우에 사용됨.
I-프레임 유실 시:
- 가장 심각한 영향 발생
- 이 I-프레임을 참조하는 모든 P와 B 프레임들도 제대로 디코딩 불가능
- 다음 I-프레임이 도착할 때까지 화면이 깨지거나 멈춤 현상 발생
- 최대 수 초간 영상 품질 저하 지속 가능
- GOP(Group of Pictures) 전체에 영향을 미침
P-프레임 유실 시:
- 해당 P-프레임 이후의 모든 P와 B 프레임에 오류가 전파됨
- 다음 I-프레임까지 영상 왜곡 발생
- I-프레임보다는 영향이 적지만 여전히 눈에 띄는 화질 저하 발생
B-프레임 유실 시:
- 가장 영향이 적음
- B-프레임은 다른 프레임의 참조로 사용되지 않기 때문에 해당 프레임만 영향 받음
- 일시적인 화면 떨림이나 짧은 프레임 누락만 발생
- 다음 프레임부터 정상 재생 가능
대응 메커니즘:
- 오류 은닉(Error Concealment): 디코더가 이전 프레임으로 대체하거나 움직임 추정
- FEC(Forward Error Correction): 복구 데이터 추가 전송
- 중요한 프레임(특히 I-프레임)은 더 작은 패킷으로 분할해 손실 확률 감소
- 적응형 비트레이트: 네트워크 상태에 따라 화질 조정
이런 이유로 실시간 스트리밍에서는 I-프레임을 자주 삽입하거나 패킷 손실률이 높은 환경에서는 더 단순한 코딩 구조를 사용하기도 함.
화면이 매우 자주 바뀌는 영상에서는 B-프레임의 크기가 상당히 커질 수 있다.
이유:
- B-프레임은 이전과 이후 프레임 간의 유사성을 활용해 압축하는데, 장면 변화가 심하면 이 유사성이 크게 떨어짐
- 참조 프레임들과 현재 프레임 사이의 차이가 클수록 더 많은 데이터를 저장해야 함
- 극단적인 장면 전환에서는 B-프레임 내 많은 매크로블록이 “인트라” 방식으로 인코딩됨 (I-프레임처럼)
- 움직임 벡터도 더 복잡해져서 압축 효율이 떨어짐
실제 상황:
- 액션 영화나 스포츠 중계 같은 빠른 장면 전환이 많은 콘텐츠에서 B-프레임 크기가 커짐
- 때로는 B-프레임 사용이 오히려 비효율적이어서 인코더가 자동으로 I-프레임을 더 자주 사용하기도 함
- 일부 인코딩 설정에서는 급격한 장면 변화를 감지해 B-프레임 대신 I-프레임을 강제로 삽입하기도 해
이런 경우에는 인코더가 적응적으로 GOP 구조를 조정해서 빠르게 변화하는 영상을 효율적으로 처리하는 게 중요해!
인트라 방식(Intra coding)은 비디오 압축에서 현재 프레임 내의 정보만을 사용해서 인코딩하는 방법
인트라 코딩의 특징:
- 다른 프레임을 참조하지 않고 오직 현재 프레임 내부의 데이터만 사용함
- I-프레임 전체가 이 방식으로 인코딩됨
- 프레임 내 공간적 중복성(spatial redundancy)만 활용해 압축
- 같은 프레임 내에서 이미 인코딩된 주변 픽셀들을 기반으로 예측
인트라 예측 기법:
- H.264에서는 매크로블록 내 이미 처리된 이웃 픽셀들의 패턴을 분석
- 다양한 방향성(수직, 수평, 대각선 등)을 고려한 예측 모드 사용
- 실제 값과 예측값의 차이(잔차)만 저장해 효율성 높임
인트라 방식은 독립적으로 디코딩이 가능하기 때문에 랜덤 액세스 포인트로 사용되거나 에러 복구에 유리하지만, 인터 코딩(다른 프레임 참조)보다는 압축 효율이 낮은 편임
적응형 GOP 구조 조정
- 비디오 인코더가 영상 콘텐츠의 특성에 맞춰 GOP 패턴을 실시간으로 변경하는 기술.
주요 특징:
- 장면 변화 감지: 급격한 장면 전환이 감지되면 자동으로 I-프레임을 삽입
- 움직임 분석: 움직임이 많은 구간에서는 GOP 길이를 짧게, 정적인 장면에서는 길게 조정
- 콘텐츠 적응: 텍스트 위주 화면, 액션 장면, 풍경 등 다양한 콘텐츠 유형에 최적화
- 대역폭 조절: 네트워크 상황에 따라 I-프레임 빈도를 조절해 전송 효율성 개선
실제 적용 예:
- 스포츠 중계: 빠른 움직임 구간에서는 P-프레임 간격을 줄임
- 뉴스 방송: 앵커 샷에서는 긴 GOP, 현장 영상 전환 시 I-프레임 삽입
- 게임 스트리밍: 폭발이나 화면 전환 시 새 I-프레임으로 시작하는 새 GOP 생성
이런 적응형 접근은 고정 패턴보다 같은 비트레이트에서 더 좋은 화질을 제공하고, 버퍼링이나 화질 저하를 최소화할 수 있음.
장면 변화 감지와 움직임 분석은 다양한 알고리즘으로 이루어짐.
장면 변화 감지 방법:
-
프레임 차이 분석:
- 연속된 프레임 간 픽셀 차이의 합(SAD, Sum of Absolute Differences)이 특정 임계값 초과 시 장면 전환으로 판단
- 연속 프레임의 히스토그램 비교로 색상 분포 변화 감지
-
인코딩 통계 활용:
- P-프레임에서 인트라 매크로블록 비율이 급증하면 장면 변화 징후로 판단
- 움직임 예측 시 잔차(residual) 값이 크게 증가할 때 새 장면으로 인식
-
머신러닝 기반:
- 최신 인코더는 CNN 등을 활용해 장면 전환을 더 정확하게 감지
- 시간적 특성을 학습해 점진적 장면 전환도 인식
움직임 분석 방법:
-
블록 매칭 알고리즘:
- 프레임을 작은 블록으로 나누고 이전/다음 프레임에서 가장 유사한 블록을 찾음
- 각 블록마다 움직임 벡터(motion vector)를 계산해 움직임 정도와 방향 파악
-
다중 참조 프레임 분석:
- 여러 참조 프레임을 비교해 최적의 예측 소스 선택
- 시간적 거리와 예측 정확도 간의 균형을 고려
-
가변 블록 크기:
- 움직임이 복잡한 영역은 작은 블록으로, 단순한 영역은 큰 블록으로 분할
- 16x16에서 4x4까지 다양한 크기로 세분화해 분석
-
서브픽셀 정밀도:
- 1/4 또는 1/8 픽셀 단위로 움직임을 분석해 더 정확한 예측
- 보간법을 통해 픽셀 사이 값을 계산
이런 분석 결과를 바탕으로 인코더는 GOP 구조, 프레임 타입, 양자화 파라미터 등을 실시간으로 조절해서 최적의 압축 효율을 얻음.
- 비트레이트
- 디지털 오디오, 비디오 파일에서 초당 처리되는 비트 수를 나타냄.
- 당연히 비트레이트가 높아질수록
- 파일 품질이 좋아짐
- 파일 크기가 커짐
- 더 많은 대역폭이나 저장 공간이 필요
- 128kbps는 1초당 128,000 비트를 의미한다.
- kbps는 kilobit per second를 나타낸다.
- kbps - kilobit per second: 초당 1000비트
- KB/s - KiloByte per second: 초당 1,000바이트 (8000비트)
- 네트워크 속도나 오디오 비트레이트 같은 분야에서 중요하게 사용됨
- 인터넷 속도고 보통 Mbps (초당 메가비트)로 표현되는 경우가 많다.
그러면 이렇게 H.264 및 RTP로 통신하려면 C++에서는 어떤 방식으로 코딩해야 하는가? 지원하는 라이브러리가 있는가?
H.264와 RTP로 C++에서 통신하기 위한 라이브러리와 구현 방법을 설명해 줄게!
주요 지원 라이브러리:
-
FFmpeg
- 가장 널리 사용되는 오픈소스 멀티미디어 프레임워크
- H.264 인코딩/디코딩과 RTP 패킷화 모두 지원
- libavcodec, libavformat 등의 하위 라이브러리 제공
-
Live555
- 스트리밍 미디어에 특화된 라이브러리
- RTP/RTCP/RTSP 프로토콜 완벽 지원
- 실시간 미디어 전송에 최적화
-
GStreamer
- 파이프라인 기반 멀티미디어 프레임워크
- 플러그인 시스템으로 쉽게 확장 가능
- H.264와 RTP 모두 내장 요소로 지원
-
x264 + jrtplib 조합
- x264: 고성능 H.264 인코더 라이브러리
- jrtplib: 순수 RTP 구현을 위한 라이브러리
간단한 구현 흐름:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
// FFmpeg 사용 예시 (의사 코드)
// 1. 초기화
avcodec_register_all();
av_register_all();
avformat_network_init();
// 2. 인코더 설정
AVCodec *codec = avcodec_find_encoder(AV_CODEC_ID_H264);
AVCodecContext *c = avcodec_alloc_context3(codec);
// H.264 파라미터 설정
c->bit_rate = 400000;
c->width = 1280;
c->height = 720;
c->time_base = (AVRational){1, 25};
c->gop_size = 10;
c->max_b_frames = 1;
c->pix_fmt = AV_PIX_FMT_YUV420P;
// 인코더 열기
avcodec_open2(c, codec, NULL);
// 3. RTP 출력 포맷 설정
AVFormatContext *ofmt_ctx = NULL;
avformat_alloc_output_context2(&ofmt_ctx, NULL, "rtp", "rtp://192.168.1.100:5004");
// 4. 스트림 추가 및 헤더 쓰기
AVStream *out_stream = avformat_new_stream(ofmt_ctx, NULL);
avcodec_parameters_from_context(out_stream->codecpar, c);
avformat_write_header(ofmt_ctx, NULL);
// 5. 프레임 인코딩 및 전송 루프
while (더 보낼 프레임이 있음) {
// 프레임 준비
av_frame_make_writable(frame);
// 프레임에 영상 데이터 채우기
// 인코딩
avcodec_send_frame(c, frame);
while (avcodec_receive_packet(c, &pkt) == 0) {
// RTP로 패킷 전송
av_interleaved_write_frame(ofmt_ctx, &pkt);
av_packet_unref(&pkt);
}
}
// 6. 정리
avformat_close_input(&ofmt_ctx);
avcodec_free_context(&c);
고려사항:
- 네트워크 지연과 패킷 손실 대응 로직 구현 필요
- 비디오 소스(카메라, 파일 등)에 따른 입력 처리
- 에러 핸들링과 버퍼 관리가 중요
- GOP 구조와 QoS 파라미터 최적화
대규모 프로젝트라면 FFmpeg이나 GStreamer가 가장 널리 사용되고, 더 가벼운 구현이 필요하면 Live555가 좋은 선택임.
C++
스마트 포인터 (C++)
- Shared 포인터 (shared pointer) 와 Unique 포인터 (unique pointer) 의 차이점
- 하나의 동적 할당된 객체를 관리하는 스마트 포인터로, 해당 객체의 유일한 소유권을 가진다. 객체의 소유권을 가진 std::unique_ptr 변수가 소멸되면 해당 객체는 해제된다.
- 하나의 동적 할당된 객체를 관리하는 스마트 포인터로, 해당 객체는 여러 std::shared_ptr에 의해서 소유권이 공유된다. 객체의 소유권을 가진 모든 std::shared_ptr 변수들이 소멸되면 해당 객체는 해제된다.
아래와 같은 weak pointer 도 존재한다. weak pointer는 참조 카운트에 영향을 미치지 않는다. 아래와 같은 순환 참조 (shared_ptr의 sp->ptr이 자기 자신을 가리키고 있음.) 문제를 해결할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
#include <memory>
int main() {
std::shared_ptr<int> sp = std::make_shared<int>(123);
std::weak_ptr<int> wp = sp;
if (std::shared_ptr<int> locked = wp.lock()) { // Use lock() to check whether the object still exists
std::cout << "*locked = " << *locked << '\n';
}
else {
std::cout << "wp is expired\n";
}
return 0;
}
shared_ptr (shared pointer)
- 장점:
- 참조 카운팅: 여러 개의 shared_ptr가 동일한 객체를 공유할 수 있으며, 마지막 shared_ptr가 소멸될 때 객체가 삭제됩니다.
- 편리한 공유: 여러 곳에서 동일한 객체를 참조해야 할 때 유용합니다.
- 단점:
- 성능: 참조 카운트를 관리하기 위한 추가 오버헤드가 발생합니다. 이는 멀티스레드 환경에서 락을 사용해야 하므로 성능 저하를 초래할 수 있습니다.
- 순환 참조: 두 개 이상의 객체가 서로를 shared_ptr로 참조할 경우, 순환 참조가 발생하여 메모리 누수가 발생할 수 있습니다. 이를 방지하기 위해 weak_ptr을 사용해야 합니다.
unique_ptr (unique pointer)
- 장점:
- 소유권 명확성: unique_ptr는 객체에 대한 유일한 소유권을 가지므로, 메모리 관리가 간단하고 안전합니다. 복사할 수 없고, 이동만 가능합니다.
- 성능: 추가적인 참조 카운트가 없기 때문에 성능이 우수합니다.
- 단점:
- 공유 불가능: 객체를 여러 곳에서 참조할 수 없으므로, 공유가 필요한 경우에는 다른 방식을 사용해야 합니다.
- 소유권 이전: 객체의 소유권을 다른 unique_ptr로 이전해야 하므로, 코드 작성 시 주의가 필요합니다.
Go (GoLang)
고루틴 (Goroutine) (Go)
- Go에서 제공하는 경량 스레드.
- 일반적인 OS 스레드보다 훨씬 가볍고 효율적
- 특징
- 매우 가벼움 (2KB 정도의 스택으로 시작)
- 수천, 수만 개를 동시에 실행 가능
- Go 런타임이 자동으로 관리
-
go키워드로 간단하게 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
package main
import (
"fmt"
"time"
)
func sayHello() {
fmt.Println("Hello from goroutine!")
}
func main() {
go sayHello() // 고루틴으로 실행
// 메인 함수가 끝나면 고루틴도 종료되므로 잠시 기다림
time.Sleep(1 * time.Second)
fmt.Println("Main function")
}
-
고루틴 vs OS 스레드
- OS 스레드의 문제점
- 무거운 스택
- 기본 1~8MB (고정 크기)
- 비싼 생성 비용
- 시스템 콜 필요
- 느린 컨텍스트 스위칭
- 커널 개입 필요
- 제한된 수량
- 보통 수천 개가 한계
- 무거운 스택
- 고루틴의 장점
- 작은 스택
- 2KB로 시작 (동적 확장)
- 저렴한 생성
- 단순 함수 호출 수준
- 빠른 스위칭
- 유저 모드에서 처리
- 대량 생성 가능
- 수십만 개도 OK
- 작은 스택
- Go의 M:N 스케쥴링 모델 (GMP)
- Go는 M:N 스케쥴링 모델을 사용
1 2
G (Goroutine) : M (Machine/OS Thread) : P (Processor) N개 : M개 : GOMAXPROCS개
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
// 개념적 구조 type G struct { stack stack // 고루틴 스택 (2KB~1GB) stackguard0 uintptr // 스택 오버플로우 검사 sched gobuf // 스케줄링 컨텍스트 goid int64 // 고루틴 ID // ... 기타 필드들 } type M struct { g0 *g // 스케줄링용 고루틴 curg *g // 현재 실행 중인 고루틴 p *p // 연결된 P spinning bool // 작업을 찾고 있는지 // ... 기타 필드들 } type P struct { runq [256]*g // 로컬 실행 큐 runqhead uint32 // 큐 헤드 runqtail uint32 // 큐 테일 // ... 기타 필드들 }
- Go는 M:N 스케쥴링 모델을 사용
- 스택 관리 (세그먼트 스택)
-
동적 스택 확장 ```go func recursiveFunction(n int) int { if n <= 0 { return 1 }
// 스택이 부족하면 자동으로 확장! // OS 스레드라면 스택 오버플로우 위험 return n * recursiveFunction(n-1) }
func main() { go func() { // 2KB로 시작해서 필요에 따라 확장 result := recursiveFunction(10000) fmt.Println(result) }() }
1 2 3 4 5 6 7 8 9 10 11
- 스택 확장 매커니즘 ```go // 런타임이 하는 일 (의사코드) func stackCheck() { if stackPointer < stackGuard { // 스택 공간 부족! newStack := allocateNewStack(currentSize * 2) copyStack(oldStack, newStack) updatePointers(newStack) } } -
- 컨텍스트 스위칭 비교
- OS 컨텍스트 스위칭
- 모든 레지스터 저장
- 커널 모드 전환
- 타 스레드의 레지스터 복원
- 약 1~10μs (마이크로초) 소요
- 고루틴 컨텍스트 스위칭
1 2 3 4 5 6 7 8 9 10 11
// Go 런타임 (의사코드) func schedule() { // 단 3개 레지스터만 저장/복원 gp.sched.sp = sp // 스택 포인터 gp.sched.pc = pc // 프로그램 카운터 gp.sched.bp = bp // 베이스 포인터 // 다음 고루틴 선택 nextG := findRunnableGoroutine() gogo(nextG) // 어셈블리로 점프 }
- 약 200ns 소요 (50배 빠름!)
- OS 컨텍스트 스위칭
- 고루틴 스케줄링 세부 사항
- 협력적 스케줄링
1 2 3 4 5 6 7 8 9 10 11 12 13 14
func longRunningTask() { for i := 0; i < 1000000; i++ { // 함수 호출 시마다 스케줄링 포인트 체크 doSomething() // Go 1.14부터 비동기 선점형 스케줄링 // 신호 기반으로 강제 중단 가능 } } func doSomething() { // 함수 프롤로그에서 스케줄링 체크 runtime.Gosched() // 명시적 양보 가능 }
- 작업 훔치기
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
// P가 로컬 큐가 비었을 때 func findWork() *g { // 1. 로컬 실행 큐 확인 if gp := runqget(); gp != nil { return gp } // 2. 글로벌 큐 확인 if gp := globrunqget(); gp != nil { return gp } // 3. 다른 P에서 작업 훔치기 for i := 0; i < runtime.GOMAXPROCS(0); i++ { if gp := runqsteal(otherP); gp != nil { return gp } } // 4. 네트워크 폴러 확인 if gp := netpoll(); gp != nil { return gp } return nil }
- 메모리 효율성 비교
- 시스템 콜 처리
- 블로킹 시스템 콜 시
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
func fileOperation() { // 파일 읽기 = 블로킹 시스템 콜 file, err := os.Open("large_file.txt") if err != nil { return } defer file.Close() // 이 시점에서 Go 런타임이: // 1. 현재 M을 블록 상태로 변경 // 2. P를 다른 M에 할당 // 3. 다른 고루틴들은 계속 실행 data := make([]byte, 1024) file.Read(data) // 시스템 콜 완료 후: // 1. 고루틴이 다시 실행 가능 상태로 // 2. 스케줄러가 적절한 P에 배치 }
- 블로킹 시스템 콜 시
- 협력적 스케줄링
- 단점
- blocking system call 시 다른 고루틴이 멈춤
- 다른 실행 가능한 스레드 (runnable thread)가 존재할 경우 runtime은 현재 thread에 있는 다른 goroutine들을 다른 runnable thread로 옮겨 block 되지 않는다.
- 그래서 blocking이 되지 않고 다른 goroutine으로 실행을 이어가려면 runtime에서 최소 1개 이상의 thread가 만들어져야 한다.
- 디버깅의 복잡성 등
- 동시성 코드의 까다로운 디버깅
- 실행 순서의 예측 불가능으로 인한 순서 보장의 어려움 등
- 메모리 누수 위험 (Goroutine Leak)
- 고루틴 사용 후 해제 안하면 메모리 누수 발생
- blocking system call 시 다른 고루틴이 멈춤
- 요약
- 고루틴이 효율적인 이유:
- 메모리 효율성
- 2KB vs 1-8MB
- 빠른 생성
- 함수 호출 수준 vs 시스템 콜
- 저비용 스위칭
- 200ns vs 1-10μs
- 동적 스택
- 필요에 따라 확장 vs 고정 크기
- 유저 모드 스케줄링
- 커널 개입 없음
- 작업 훔치기
- 효율적인 로드 밸런싱
- 메모리 효율성
- 구현의 핵심
- M:N 모델
- N개 고루틴을 M개 OS 스레드에 매핑
- 세그먼트 스택
- 동적 확장/축소
- 협력적 + 선점형
- 함수 호출과 신호 기반
- 작업 분산
- 로컬 큐 + 글로벌 큐 + 작업 훔치기
- M:N 모델
- 고루틴이 효율적인 이유:
- OS 스레드의 문제점
채널 (Go)
- 고루틴들 간의 통신 수단
- 데이터를 안전하게 주고받을 수 있게 해줌
- 특징
- 타입 안전성 보장
- 동기화 기능 제공
- (CSP 모델) “Don’t communicate by sharing memory; share memory by communicating” 철학
- 메모리를 공유해 소통하지 말고, 소통을 통해 메모리를 공유하자
- 장점
- 간단한 동시성
- 복잡한 락 없이도 안전한 동시성 프로그래밍
- 확장성
- 수많은 고루틴을 효율적으로 관리
- 데드락 방지
- 채널을 통한 구조화된 통신
- 성능
- 컨텍스트 스위칭 비용이 낮음
- 간단한 동시성
- 단점
- 데드락 위험
- 채널을 잘못 사용하면 데드락이 쉽게 발생함.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
// 예제 1 func main() { ch := make(chan int) ch <- 42 // 데드락! 받는 고루틴이 없음 fmt.Println(<-ch) } // 예제 2 func main() { ch1 := make(chan int) ch2 := make(chan int) go func() { ch1 <- <-ch2 // ch2에서 받길 기다림 }() go func() { ch2 <- <-ch1 // ch1에서 받길 기다림 }() // 순환 대기로 데드락 발생 }
- 채널을 잘못 사용하면 데드락이 쉽게 발생함.
- 성능 오버헤드
- 채널은 편하지만 성능 비용이 존재함.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
// 채널 사용 (느림) func withChannel() { ch := make(chan int, 1000) go func() { for i := 0; i < 1000; i++ { ch <- i } close(ch) }() sum := 0 for v := range ch { sum += v } } // 뮤텍스 사용 (빠름) func withMutex() { var mu sync.Mutex var sum int go func() { for i := 0; i < 1000; i++ { mu.Lock() sum += i mu.Unlock() } }() }
- 채널은 편하지만 성능 비용이 존재함.
- 메모리 누수 위험
- 채널을 제대로 닫지 않으면 고루틴이 영원히 기다릴 수 있음.
1 2 3 4 5 6 7 8 9 10 11 12
func leakyFunction() { ch := make(chan int) go func() { // 이 고루틴은 영원히 기다림 - 메모리 누수! value := <-ch fmt.Println(value) }() // 채널에 아무것도 보내지 않고 함수 종료 // 고루틴은 계속 살아있음 }
- 채널을 제대로 닫지 않으면 고루틴이 영원히 기다릴 수 있음.
- 복잡한 에러 처리
- 채널에서는 에러를 직접 전달하기 어려움
1 2 3 4 5 6 7 8 9 10 11 12 13 14
type Result struct { Value int Error error } func workerWithError(jobs <-chan int, results chan<- Result) { for job := range jobs { if job < 0 { results <- Result{Error: fmt.Errorf("negative number: %d", job)} continue } results <- Result{Value: job * 2} } }
- 채널에서는 에러를 직접 전달하기 어려움
- 디버깅의 어려움
- 채널 기반 코드는 디버깅이 까다로움
1 2 3 4 5 6 7 8 9 10 11 12
func complexChannelFlow() { ch1 := make(chan int) ch2 := make(chan int) ch3 := make(chan int) // 어디서 막혔는지 찾기 어려움 go func() { ch1 <- <-ch2 }() go func() { ch2 <- <-ch3 }() go func() { ch3 <- <-ch1 }() // 디버깅 시 어떤 채널이 문제인지 파악하기 힘듦 }
- 채널 기반 코드는 디버깅이 까다로움
- 타입 안전성 제한
- 채널은 단일 타입만 전송 가능
- 버퍼 크기 결정의 어려움
- 적절한 버퍼 크기를 정하기 어려움
1 2 3 4 5
// 너무 작으면 블로킹 ch := make(chan int, 1) // 너무 크면 메모리 낭비 ch := make(chan int, 1000000)
- 적절한 버퍼 크기를 정하기 어려움
- 채널 방향성 제약
- 방향성 채널은 유연성을 제한
- 컨텍스트 전파의 어려움
- 컨텍스트 취소나 타임아웃 처리가 복잡
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
func workWithTimeout(ctx context.Context) { ch := make(chan int) go func() { time.Sleep(5 * time.Second) ch <- 42 }() select { case result := <-ch: fmt.Println(result) case <-ctx.Done(): fmt.Println("Timeout!") // 하지만 고루틴은 계속 실행 중... } }
- 컨텍스트 취소나 타임아웃 처리가 복잡
- 대안과 해결책
- 뮤텍스 사용
- 단순한 공유 상태에는
sync.Mutex가 더 효율적
- 단순한 공유 상태에는
- 컨텍스트 활용
- 취소와 타임아웃 처리
- 워커 풀 패턴
- 고루틴 수 제한
- 버퍼 채널
- 적절한 버퍼링으로 블로킹 방지
- 뮤텍스 사용
- 데드락 위험
- 종류
- 버퍼 없는 채널 (Unbuffered)
ch := make(chan int) // 동기적으로 동작
- 버퍼 없는 채널 (Unbuffered)
- 버퍼 있는 채널 (Buffered)
ch := make(chan int, 3) // 3개까지 버퍼링 가능
- 버퍼 있는 채널 (Buffered)
-
- 방향성 채널 ```go // 송신 전용 func sender(ch chan<- int) { ch <- 10 }
// 수신 전용 func receiver(ch <-chan int) { value := <-ch fmt.Println(value) } ```
- 간단 예제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package main
import "fmt"
func main() {
// 정수형 채널 생성
ch := make(chan int)
// 고루틴에서 채널에 데이터 전송
go func() {
ch <- 42 // 채널에 42 전송
}()
// 메인에서 채널에서 데이터 수신
value := <-ch // 채널에서 값 받기
fmt.Println("Received:", value)
}
- 채널 닫기와 range
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
func main() {
ch := make(chan int, 3)
go func() {
for i := 0; i < 3; i++ {
ch <- i
}
close(ch) // 채널 닫기
}()
// 채널이 닫힐 때까지 모든 값 받기
for value := range ch {
fmt.Println(value)
}
}
- select 문
- 여러 채널 중 하나가 준비될 때까지 대기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
func main() {
ch1 := make(chan string)
ch2 := make(chan string)
go func() {
time.Sleep(1 * time.Second)
ch1 <- "from ch1"
}()
go func() {
time.Sleep(2 * time.Second)
ch2 <- "from ch2"
}()
for i := 0; i < 2; i++ {
select {
case msg1 := <-ch1:
fmt.Println("Received", msg1)
case msg2 := <-ch2:
fmt.Println("Received", msg2)
}
}
}
-
채널 vs 뮤텍스
- 채널
- 통신 중심
- 데이터를 주고받으며 동시성 처리
- CSP 모델 (“Don’t communicate by sharing memory; share memory by communicating” 철학)
- 고수준의 추상화
- 언제?
- 데이터 파이프라인
- 워커 풀 패턴
- 팬-아웃/팬-인 패턴
- 시그널링과 동기화
- 통신 중심
- 뮤텍스
- 공유 메모리 보호
- 임계 영역에 대한 독점적 접근
- 저수준 동기화
- 직접적인 메모리 접근 제어
- 전통적 방식
- 대부분의 언어에서 사용하는 패턴
- 언제?
- 공유 카운터/상태
- 캐시나 맵 보호
- 설정 값 보호
- 간단한 임계 영역
- 공유 메모리 보호
- 성능 최적화 팁
- 고빈도 작업은 뮤텍스
- 복잡한 로직은 채널
- 읽기 중심은 RWMutex
- 채널을 쓸 때
- 데이터 파이프라인 구축할 때
- 워커 풀 패턴 구현할 때
- 복잡한 동시성 로직이 필요할 때
- 컴포넌트 간 통신이 주요 목적일 때
- 뮤텍스를 쓸 때
- 공유 상태 보호가 목적일 때
- 성능이 중요한 고빈도 작업
- 간단한 임계 영역 보호
- 캐시나 설정 관리할 때
- 기본적으로는 단순하면 뮤텍스, 복잡하면 채널이라고 생각하자. 성능이 중요하다면 뮤텍스를 우선 고려하고, 코드의 명확성과 구조가 중요하다면 채널을 선택
- 채널
| 상황 | 추천 | 이유 |
|---|---|---|
| 데이터 전달이 주목적 | 채널 | 자연스러운 통신 모델 |
| 공유 상태 보호 | 뮤텍스 | 더 단순하고 빠름 |
| 복잡한 동시성 패턴 | 채널 | 구조화된 통신 |
| 단순한 카운터 | 뮤텍스 | 오버헤드 최소화 |
| 파이프라인 처리 | 채널 | 데이터 흐름이 명확 |
| 캐시/맵 보호 | 뮤텍스 | 읽기/쓰기 락 활용 |
| 작업자 풀 | 채널 | 작업 분배가 자연스러움 |
| 설정 값 관리 | 뮤텍스 | 간단한 접근 제어 |
GC
GC (Garbage Collection) (Java / Go / Python / Javascript(Node.js) ( JS - V8 ))
- STW (Stop The World)
- GC가 작업할 때 모든 애플리케이션 스레드를 일시정지시키는 것
- 문제점 (왜 멈춰야 하나? - 멈추지 않으면 발생하는 문제)
- 일관성 없는 상태
- 객체 참조가 계속 변함
- 경쟁 조건
- GC와 애플리케이션이 동시에 메모리 조작
- 안전성 문제
- 살아있는 객체를 실수로 해제할 위험
- 일관성 없는 상태
- 전형적인 STW 시퀀스
- 모든 스레드가 안전점에 도달할 때까지 대기
- 함수 호출 후
- 루프 백 엣지
- 예외 처리 지점 등
- 세계 정지 (STW - Stop The World)
- GC 작업 수행
- 세계 재시작
- 모든 스레드가 안전점에 도달할 때까지 대기
- 안전점 개념
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
// Java의 안전점 예시 public void demonstrateSafepoints() { for (int i = 0; i < 1000000; i++) { doWork(i); // ← 안전점: 함수 호출 후 if (i % 1000 == 0) { // ← 안전점: 루프 백 엣지 // GC가 여기서 스레드를 멈출 수 있음 } } // 안전하지 않은 구간의 예: // while (true) { // x = x + 1; // ← 안전점 없음, GC가 멈출 수 없음! // } }
- STW 문제점의 영향
- 웹 어플리케이션
- UI 응답 지연
- 애니메이션 끊김
- 사용자 입력 무시
- 스크롤 버벅임
- 게임
- 프레임 드랍
- 입력 지연
- 음성/영상 끊김
- 서버
- 요청/처리 지연
- 타임아웃 발생
- 처리량 감소
- 실시간 시스템
- 데드라인 위반
- 시스템 불안정
- 웹 어플리케이션
- 정리
- 필요악
- GC가 안전하게 작업하기 위해 필수
- 성능 병목
- 사용자 경험에 직접적 영향
- 최적화 대상
- 현대 GC의 주요 개선 포인트
- 측정 가능
- 모니터링으로 문제점 파악 가능
- 필요악
(꼬리질문)
- STW가 필요하다면, 증분형 마킹 등은 왜 하는거지?
- STW에서만 가능한 작업과 애플리케이션과 동시 실행 가능한 작업을 분리해 STW 시간을 최소화한다.
- STW에서만 가능한 작업
- 루트 스캔 (루트 객체 스캔 시작 -> 일관성을 위해 STW 필수)
- 루트는 GC가 “살아있는 객체” 를 찾기 위한 시작 지점
- 마치 나무의 뿌리처럼 모든 객체 탐색의 출발점
- 시작점 찾기: 살아있는 객체 탐색의 출발점을 식별
- 일관성 필요: 정확한 루트 정보를 위해 STW 사용
- 빠른 처리: 전체 GC 중 가장 빠르게 처리되는 부분
- 전역 영향: 모든 후속 GC 작업의 기준점
- 마킹 완료 및 정리 (Write Barrier 비활성화 등)
- 새로운 GC 사이클 준비 (메타데이터 업데이트)
- 루트 스캔 (루트 객체 스캔 시작 -> 일관성을 위해 STW 필수)
- 동시 실행 가능한 작업
- 객체 그래프 순회
- Write Barrier로 일관성 보장
- 마킹 작업 (대부분)
- 삼색 마킹 알고리즘 활용
- 메모리 해제 (스왑)
- 해제 대상은 이미 확정
- 메모리 압축 (일부)
- 백그라운드에서 점진적으로
- 객체 그래프 순회
- STW에서만 가능한 작업
- “STW가 무조건 필요한가?”
- 아니다. 대부분의 GC작업은 동시 실행 가능함.
- STW는 정말 필요한 순간 (루트 스캔, 마킹 완료 등) 에서만 사용됨.
- “증분형 마킹해도 STW가 존재하지 않나?”
- 맞다. 하지만 180ms 한 번 5ms씩 4번의 차이.
- 사용자는 5ms는 못 느끼지만, 180ms느 확실히 느낀다.
- “더 자주 호출되면 오버헤드 아닌가?”
- 부분적으로 맞음. 총 처리량은 약간 감소함. (Write Barrier 등 오버헤드)
- 하지만 반응성은 36배 향상 (180ms -> 5ms)
- 결론
- 증분형 마킹은 처리량을 약간 희생해서 반응성을 크게 개선하는 전략.
- 현대 애플리케이션에서는 이 트레이드오프가 훨씬 가치있음.
- STW에서만 가능한 작업과 애플리케이션과 동시 실행 가능한 작업을 분리해 STW 시간을 최소화한다.
- Write Barrier
- 포인터 변경을 감시하는 코드
- 객체 간의 참조가 바뀔 때마다 자동으로 실행되는 일종의 “감시자”
- 왜 필요한가?
1 2 3 4 5 6 7 8 9 10 11 12
// 증분형 GC 중에 이런 일이 벌어질 수 있어 func whyWriteBarrier() { // GC가 마킹 중인 상황 objA := &Object{marked: true} // 이미 마킹됨 (검은색) objB := &Object{marked: false} // 아직 마킹 안됨 (흰색) // 애플리케이션이 실행되면서... objA.child = objB // 검은 객체에서 흰 객체로 새 참조! // 문제: objB가 마킹되지 않은 채로 넘어갈 수 있음 // → 살아있는 객체가 해제될 위험! }
- 문제 상황
- GC가 objA를 이미 처리 완료 (검은색)
- GC가 objB를 아직 발견하지 못함 (흰색)
- 애플리케이션이 objA.child = objB 할당
- GC가 objB를 놓칠 수 있음 -> 메모리 오류
- 문제 상황
- 기본 개념
1 2 3 4 5 6 7 8 9 10
// Write Barrier가 없다면 func withoutWriteBarrier() { obj.field = newValue // 그냥 할당 } // Write Barrier가 있다면 func withWriteBarrier() { writeBarrier(&obj.field, newValue) // 감시 코드 실행 obj.field = newValue // 실제 할당 }
- 실제 구현 예시
1 2 3 4 5 6 7 8 9 10 11
// Go언어의 Write Barrier (의사코드) func writeBarrier(dst **Object, src *Object) { if gcPhase == GCMark { // 마킹 중이라면 if src != nil && !src.marked { // 새로 참조되는 객체를 gray 큐에 추가 markGray(src) } } *dst = src // 실제 포인터 업데이트 }
- 실제 구현 예시
- 다양한 Write Barrier 종류
- Incremental Write Barrier
- 새로 참조되는 객체를 마킹 (새 객체를 회색으로)
- Generational Write Barrier
- Java의 세대별 GC용
- Old 객체에서 Young 객체로의 참조 추적
- Concurrent Write Barrier
- JavaScript V8의 동시 마킹용
- 마킹 워크리스트에 추가
- Incremental Write Barrier
- 최적화 기법들
- 조건부 활성화
- 배치 처리
- 핵심 정리
- 감시자 역할
- 포인터 변경을 모니터링
- 안전성 보장
- 살아있는 객체가 실수로 해제되지 않도록
- GC 협력
- 증분형/동시 GC가 정확히 동작하도록 지원
- 성능 트레이드오프
- 안전성을 위해 약간의 오버헤드 감수
- 감시자 역할
- 비유로 설명
- 도서관에서 책을 다른 책장으로 옮길 때
- 사서(GC)가 정리 중이라면
- 옮기는 사람(애플리케이션)이 “이 책 여기로 옮겼어요!”라고 알려주는 것
- 사서가 놓치지 않도록 도와주는 시스템이 Write Barrier
- GC - Generational Hypothesis (세대 알고리즘)
- Weak Generational Hypothesis (약한 세대 가설)
- 가설 1: 부분의 객체는 젊은 나이에 죽는다.
- 가설 2: 젊은 객체에서 오래된 객체로의 참조는 드물다.
- 결론: 젊은 세대를 자주, 오래된 세대를 가끔 청소하자.
- 핵심 아이디어
- 젊은 객체: 금방 죽을 확률이 높음 -> 자주 검사
- 오래된 객체: 오래 살 확률이 높음 -> 가끔 검사
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
Java HotSpot JVM의 세대 구조 힙 메모리 레이아웃: Young Generation (전체 힙의 1/3) ┌─────────────────────────────────────────────────┐ │ Eden Space │ Survivor 0 │ Survivor 1 │ │ (새 객체들) │ (살아남은) │ (살아남은) │ │ 80% │ 10% │ 10% │ └─────────────────────────────────────────────────┘ Old Generation (전체 힙의 2/3) ┌─────────────────────────────────────────────────┐ │ Tenured Space (오래 살아남은 객체들) │ └─────────────────────────────────────────────────┘ Metaspace (JVM 8+, 네이티브 메모리) ┌─────────────────────────────────────────────────┐ │ Class metadata, Method area │ └─────────────────────────────────────────────────┘
- 세대별 특징 비교
세대 내용 GC시간 GC 빈도 사망률 Young (Gen 0) 새로 생성된 객체들 1-2ms 매우 자주 (수초~수분) 90% 이상 Old (Gen 1) 오래 살아남은 객체들 10-20ms 가끔 (수분~수시간) 10% 미만 Permanent/Metaspace (Gen 2) 클래스 메타데이터, 상수 100ms+ 매우 드물게 (수시간~수일) 5% 미만 - 세대 구분 기준: 객체의 생존 기간
- 0세대: 새로 생성된 객체
- 1세대: 한 번 이상 GC에서 살아남은 객체들
- 2세대: 여러 번 살아남은 장기 객체들
- 세대 간 전환 매커니즘
- 승진 과정
- 객체 생성 -> Eden 영역에 할당
- 첫 번째 Minor GC: -> 살이있음 -> Survivor 0 영역으로 이동 (age = 1)
- 두 번째 Minor GC: -> 살이있음 -> Survivor 1 영역으로 이동 (age = 2)
- 세 번째 Minor GC: -> 살이있음 -> Survivor 0 영역으로 이동 (age = 3)
- 승진 임계값 도달 -> age >= 15 또는 Survivor 영역 부족 -> Old Generation 으로 승진
- Old Generation 에서 -> Major GC에서만 수집 대상 -> 오래 살아남을 가능성 높음.
- 실제 승진 조건
- Age 임계값 도달 (기본 15)
- Survivor 영역 부족 (50% 이상 사용)
- 대형 객체 (Eden에 할당 불가)
- 동적 임계값 조정 (adaptive sizing)
- 강제 승진 (Out-Of-Memory Error 방지)
- 승진만 가능 (0 -> 1 -> 2 일방향)
- 강등 없음
- 한 번 승진하면 되돌아가지 않음.
- 승진 과정
- GC 전략:
- Minor GC: Young Generation만 (빠르고 자주)
- Major GC: 전체 힙 (느리고 드물게)
- Incremental: 세대별로 점진적 수집
- Minor GC vs Major GC 동작
- Minor GC 과정
- GC 전 상태
- Eden:
[obj1, obj2, obj3, obj4] (가득 참) - S0:
[oldObj1] (age=5) - S1:
[] (empty) - Old:
[veryOldObj1, verOldObj2]
- Eden:
- Minor GC 실행
- Eden + S0 스캔
- 살아있는 객체만 S0으로 복사
- 각 객체의 age++
- age >= 15 인 객체는 Old로 승진
- Eden + S0 완전 정리
- GC 후 상태
- Eden:
[] (완전히 비워짐) - S0:
[] (비워짐) - S1:
[obj2, obj4] (age=1), [oldObj1] (age=6) - Old:
[veryOldObj1, veryOldObj2] (변화 없음)
- Eden:
- 특징
- 매우 빠름 (1-2ms)
- 자주 발생
- Old Generation 영향 없음
- Young Generation 만 스캔
- GC 전 상태
- Magor GC 과정
- 실행 조건
- Old Generation 부족
- System.gc() 호출
- Metaspace 부족
- Major GC 실행
- 전체 힙 스캔 (Young + Old)
- 모든 세대에서 쓰레기 수집
- 메모리 압축 (fragmentation - 단편화 해결)
- 메타데이터 정리
- 특징
- 상대적으로 느림 (10-100ms)
- 드문 발생
- 전체 애플리케이션 일시 정지
- 실행 조건
- Minor GC 과정
- 세대 간 참조 문제와 해결책
- 문제점
- Old 객체 -> Young 객체 참조
- Minor GC 시 Young Generation만 스캔
- Old에서 참조되는 Young 객체는 놓칠 수 있음
- 해결책
- Old -> Young 참조를 별도로 추적
- Write Barrier로 참조 변경 감지
- Minor GC 시 Remembered Set도 루트로 사용
- 문제점
- Weak Generational Hypothesis (약한 세대 가설)
- Go의 GC
- 핵심 특징
- 저지연 목표
- STW 시간 < 10ms
- 삼색 마킹
- White (미방문) -> Gray (방문중) -> Black (방문완료)
- 동시 실행
- 애플리케이션과 GC가 동시에 실행
- Write Barrier
- 포인터 변경 추적
1 2 3 4 5 6 7 8 9
func writeBarrier(ptr **object, new *object) { // 포인터 변경 시 새 객체를 Gray로 마킹 if gcPhase == MARK && new != nil { if isWhite(new) { markGray(new) } } *ptr = new // 실제 포인터 업데이트 }
- 포인터 변경 추적
- 저지연 목표
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// Go GC의 동작 원리 (의사코드) func tricolorGC() { // Phase 1: STW - 루트 스캔 시작 stopTheWorld() markRoots() // 스택, 전역변수를 Gray로 마킹 startTheWorld() // Phase 2: 동시 마킹 (애플리케이션 실행 중) for hasGrayObjects() { obj := getGrayObject() markChildren(obj) // 자식들을 Gray로 markBlack(obj) // 자신을 Black으로 } // Phase 3: STW - 정리 stopTheWorld() sweep() // White 객체들 해제 startTheWorld() }
- 핵심 특징
- Java의 GC
- 다양한 알고리즘 존재
- G1GC (기본)
- Generational GC + Low Latency
1 2 3 4 5 6 7 8 9 10 11
public class G1GCExample { public static void main(String[] args) { // Young Generation: Eden + Survivor spaces // Old Generation: 여러 region으로 분할 // JVM 옵션: // -XX:+UseG1GC // -XX:MaxGCPauseMillis=200 // 목표 일시정지 시간 // -XX:G1HeapRegionSize=16m // 리전 크기 } }
- Generational GC + Low Latency
- ZGC
- Ultra Low Latency
- 힙 크기와 무관하게 10ms 일시정지
-XX:+UseZGC -XX:+UnlockExperimentalVMOptions- Colored Pointers 사용
- 64bit 포인터의 상위 비트를 GC 정보로 활용
- 동시 압축: 애플리케이션 실행 중 메모리 압축
- Load Barrier: 객체 접근 시 GC 상태 확인
- Generational Hypothesis
1 2 3 4 5 6 7 8 9 10 11 12 13
public class GenerationalGC { public void demonstrateGenerations() { // Young Generation - 빈번한 GC String temp = new String("temporary"); // 곧 죽을 객체 // Old Generation - 드문 GC static final Map<String, String> cache = new HashMap<>(); // 오래 살 객체 // Eden → Survivor0 → Survivor1 → Old Generation // Minor GC: Young Generation만 // Major GC: 전체 힙 } }
- Python의 GC
- 참조 카운팅
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
import sys import gc class RefCountExample: def __init__(self, name): self.name = name def __del__(self): print(f"{self.name} 객체가 해제됨") # 참조 카운팅 동작 obj = RefCountExample("test") # ref_count = 1 obj2 = obj # ref_count = 2 del obj # ref_count = 1 del obj2 # ref_count = 0 → 즉시 해제! print(f"참조 횟수: {sys.getrefcount(obj)}")
- 순환 참조 문제
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
class Node: def __init__(self, value): self.value = value self.children = [] self.parent = None # 순환 참조 생성 parent = Node("parent") child = Node("child") parent.children.append(child) # parent → child child.parent = parent # child → parent # 참조 카운팅으로는 해제 불가! del parent, child # 여전히 메모리에 남아있음 # 순환 GC가 주기적으로 해결 gc.collect() # 강제 순환 GC 실행
- 순환 참조 문제
- GC 세대별 관리
- Python의 3세대 GC
- 0세대: 자주 확인 (매 700회 할당마다)
- 1세대: 가끔 확인 (0세대 10번마다)
- 2세대: 드물게 확인 (1세대 10번마다)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
def gc_generations(): print("GC 통계:", gc.get_stats()) print("GC 임계값:", gc.get_threshold()) # GC 비활성화 (성능 최적화 시) gc.disable() # 수동 GC collected = gc.collect() print(f"해제된 객체 수: {collected}") gc.enable() # GIL의 영향 def gil_impact(): # GIL 때문에 멀티스레딩 시에도 GC는 안전 # 하지만 다른 스레드 블로킹 가능 import threading def heavy_allocation(): data = [[] for _ in range(100000)] # GC 실행 시 다른 스레드 일시정지 threads = [threading.Thread(target=heavy_allocation) for _ in range(4)] for t in threads: t.start()
- Python의 3세대 GC
- 참조 카운팅
- JavaScript (Node.js) V8의 GC (세대별 + 증분형)
- 세대별 GC 구조
- 증분형 마킹
- 기존 방식의 문제점 (전통적인 마크-스윕 GC)
- 힙 크기에 비례해서 일시정지 시간 증가
- 사용자 경험 악화 (UI 멈춤, 응답 지연)
- 예측하기 어려운 성능
- 증분형 마킹 동작 원리
- 메인 스레드와 번갈아 실행
- 작은 단위로 나누어 실행
- 증분형 마킹에서 가장 중요한 것은 Write Barrier
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
// Incremental Marking: 메인 스레드와 번갈아 실행 function incrementalMarking() { // 기존: 한번에 모든 마킹 (긴 일시정지) // 개선: 5ms씩 나누어 마킹 (짧은 일시정지) const markers = { step1: () => console.log("마킹 단계 1 (5ms)"), step2: () => console.log("애플리케이션 실행 (10ms)"), step3: () => console.log("마킹 단계 2 (5ms)"), step4: () => console.log("애플리케이션 실행 (10ms)"), // ... 반복 }; // Write barriers로 변경사항 추적 const writeBarrier = (obj, prop, value) => { if (gcPhase === 'marking' && value && typeof value === 'object') { markGray(value); // 새로 할당된 객체 마킹 대기열에 추가 } obj[prop] = value; }; }
- 기존 방식의 문제점 (전통적인 마크-스윕 GC)
- Memory Management API
| 특성 | Go | Java | Python | JavaScript(V8) |
|---|---|---|---|---|
| 알고리즘 | 삼색 동시 마크-스윕 | G1/ZGC/Shenandoah | 참조카운팅+순환탐지 | 세대별+증분형 |
| STW 시간 | < 10ms | 1-200ms (조절가능) | 수 ms | 1-5ms |
| 처리량 | 높음 | 매우 높음 | 보통 | 높음 |
| 메모리 오버헤드 | 낮음 | 보통-높음 | 낮음 | 보통 |
| 튜닝 옵션 | 제한적 | 매우 많음 | 제한적 | 제한적 |
| 동시성 | 완전 동시 | 부분 동시 | 제한적 (GIL) | 부분 동시 |
| 예측 가능성 | 높음 | 보통 | 높음 | 보통 |
Python
GIL (Global Interpreter Lock) (Python)
- 한 번에 하나의 스레드만 Python의 바이트코드를 실행할 수 있게 하는 잠금장치
- 목적
- 메모리 관리를 안전하게 하기 위해서
- 여러 스레드가 동시에 Python 객체에 접근하는 것을 막음
- 특징
- 한 번에 하나의 스레드만 Python 코드를 실행할 수 있음
- I/O 작업할 때는 GIL이 해제되어서 다른 스레드가 실행 가능
- CPU 집약적인 작업일 때에는 멀티스레딩의 효과가 제한적
- 우회 방법
- multiprocessing 모듈 사용 (멀티 프로세스 기반)
- asyncio 모듈 사용 (비동기 프로그래밍)
- C 확장 모듈 사용
- 단 이 때에는 명시적으로 GIL을 해제하고 작업을 수행해야 함
- 외부 코드 (C/C++/Rust) 또한 기본적으로 GIL 하에서 실행되기 때문
- Numpy, SciPy 같은 라이브러리들이 이렇게 구현되어 있어 멀티스레딩에서도 성능이 좋은 것.
- 그래서 잘 만들어진 C/C++/Rust 확장 모듈을 쓰면 GIL 제약 없이 진짜 병렬 처리가 가능
- asyncio
- GIL의 제약이 문제가 되지 않는 방식으로 동작하는 것
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import asyncio import aiohttp # 기존 멀티스레딩 방식 (GIL 제약) import threading import requests def sync_fetch(url): response = requests.get(url) # I/O 대기 중에도 GIL 점유 return response.text # asyncio 방식 (단일 스레드, GIL 경합 없음) async def async_fetch(url): async with aiohttp.ClientSession() as session: async with session.get(url) as response: return await response.text() # I/O 대기 중 다른 태스크 실행
- 멀티 스레딩과의 핵심 차이점
- 멀티 스레딩
- 여러 스레드가 GIL을 두고 경합 -> 컨텍스트 스위칭 오버헤드
- asyncio
- 단일 스레드에서 협력적 멀티태스킹 -> GIL 경합 없음
- 멀티 스레딩
- asyncio의 동작 방식
1 2 3 4 5 6 7 8 9 10
async def main(): # 이 모든 태스크가 하나의 스레드에서 실행됨 tasks = [ async_fetch("http://example1.com"), async_fetch("http://example2.com"), async_fetch("http://example3.com"), ] # I/O 대기 중에 태스크 간 자동 전환 results = await asyncio.gather(*tasks)
- 왜 효과적인가?
- 단일 스레드: GIL 경합 자체가 없음
- 이벤트 루프: I/O 대기 중 자동으로 다른 태스크 실행
- 낮은 오버헤드: 스레드 생성/전환 비용이 없음.
- GIL의 제약이 문제가 되지 않는 방식으로 동작하는 것
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import asyncio
async def task1():
print("Task1 시작")
await asyncio.sleep(2) # 여기서 일시정지, 다른 태스크로 전환
print("Task1 완료")
async def task2():
print("Task2 시작")
await asyncio.sleep(1) # 여기서 일시정지, 다른 태스크로 전환
print("Task2 완료")
async def main():
await asyncio.gather(task1(), task2())
# 실행 결과:
# Task1 시작
# Task2 시작
# Task2 완료 (1초 후)
# Task1 완료 (2초 후)
- 정확한 동작 과정
- await 만나면 -> 현재 태스크 일시 정지
- 이벤트 루프가 -> 실행 가능한 다른 태스크 찾음
- I/O 완료되면 -> 해당 태스크 다시 실행 가능 상태
- 핵심 원리
- I/O 대기 중 CPU는 놀고 있으니까 다른 태스크 실행
- 네트워크 응답 기다리는 동안 다른 요청 처리
- 파일 읽기 기다리는 동안 다른 파일 작업
- 그래서 asyncio는 “동시에 여러 I/O 작업을 기다리면서, 완료된 것부터 처리하는” 방식으로 동작.
- CPU 집약적 작업에는 효과 없지만, I/O 집약적 작업에서는 엄청 효율적.
Operating System
I/O 작업의 실제 과정
1
2
3
파일 읽기 요청 → 시스템 콜 → 커널 → 하드웨어 → 대기 → 완료 신호 → 커널 → 사용자 공간
↑ ↑ ↑ ↑
CPU 사용 CPU 사용 CPU 대기 CPU 사용
하드웨어 대기 시간
1
2
3
# 파일 읽기 예시
with open('large_file.txt', 'r') as f:
data = f.read() # 이 순간 실제로는...
- CPU가 하드디스크에 “이 파일 읽어줘” 명령
- 하드디스크가 물리적으로 데이터 읽는 동안 CPU는 대기
- 네트워크도 마찬가지로 패킷이 네트워크를 통해 오는 동안 CPU 대기
실제 시간 비교
1
2
3
4
5
CPU 연산: 나노초 (10^-9초)
메모리 접근: 마이크로초 (10^-6초)
SSD 접근: 밀리초 (10^-3초)
HDD 접근: 수 밀리초
네트워크: 수십-수백 밀리초
핵심
- I/O 요청/결과 처리할 때는 CPU 사용
- 하드웨어가 실제 I/O 수행하는 동안은 CPU가 다른 일 가능
- 이 “대기 시간”이 CPU 시간 대비 엄청 길어서 “논다”고 표현하는 거야
시스템 콜
사용자 프로그램이 운영체제 서비스를 요청하는 인터페이스
- 왜 시스템 콜이 필요한가
- 사용자 프로그램은 보안상 제한된 환경에서 실행됨
- 하드웨어의 직접 접근, 파일 시스템, 네트워크 등은 커널만 할 수 있음
- 그래서 이런 작업이 필요할 때 “커널, 대신 해줘” 라고 요청하는 것이 시스템 콜
- 시스템 콜 실행 과정
- 사용자 프로그램이 시스템 콜 요청
- 트랩(trap) 발생 → 커널 모드로 전환
- 커널이 요청 처리
- 결과 반환 → 사용자 모드로 복귀
- 중요한 점
- 시스템 콜 없이는 파일도 못 열고, 네트워크도 못 하고, 프로세스도 못 만든다
- 모든 의미있는 작업은 결국 시스템 콜을 통해 이뤄짐
- 운영체제와 사용자 프로그램 사이의 유일한 소통 창구
- 시스템 콜이 필요한 상황
- 운영체제가 관리하는 모든 것을 사용자 프로그램이 사용해야 할 때
- 메모리 할당
- 프로세스 / 스레드 생성 및 관리
- 시간 관련 함수들 (time, gettimeofday 등)
- 시그널 처리
- 파일 시스템 탐색 (ls, find 등)
- 네트워크 소켓 생성/관리
- 시스템 정보 조회 (ps, top 등)
- 시스템 콜 오버헤드 구성 요소
- 모드 전환 비용
- 사용자 모드 <-> 커널 모드
- 레지스터 저장/복원
- 컨텍스트 보존
- 매개변수 검증
- 커널에서 안전성 체크
- 권한 확인
- 해당 작업 수행 권한 체크
- 실제 커널 작업
- 요청된 작업 수행
- 모드 전환 비용
실제 측정 결과 (대략적)
1
2
3
4
5
getpid(): 20-50 나노초 (매우 빠름)
time(): 50-100 나노초
getcwd(): 1-5 마이크로초 (문자열 복사 때문)
malloc(): 100-500 나노초
fork(): 수백 마이크로초 (프로세스 생성)
- 시스템 콜이 부하가 되는 경우
- 빈번한 호출
- 타이트한 루프에서 반복 호출
- 무거운 시스템 콜
- fork(), exec(), mmap() 등
- 불필요한 호출
- 캐시 가능한 값을 계속 요청
- 빈번한 호출
Linux Hard Link and Soft Link
- 리눅스 하드링크와 소프트링크의 차이점
- 하드링크 (Hard Link)
- 기본 개념 같은 inode를 가리키는 여러 개의 파일명 원본 파일과 완전히 동일한 파일 (실제로는 구분이 없음)
- 특징 원본 파일이 삭제되어도 하드링크는 여전히 작동함 같은 파일시스템 내에서만 생성 가능 디렉토리에는 하드링크 생성 불가 디스크 공간을 추가로 사용하지 않음 파일의 권한, 소유자 정보 등이 모두 동일
- 소프트링크 (Soft Link/Symbolic Link)
- 기본 개념 원본 파일의 경로를 가리키는 포인터 역할 바로가기와 비슷한 개념
- 특징 원본 파일이 삭제되면 링크가 깨짐 (broken link) 다른 파일시스템의 파일도 가리킬 수 있음 디렉토리에도 소프트링크 생성 가능 별도의 inode를 가짐 (미미한 디스크 공간 사용) 원본과 다른 권한을 가질 수 있음
- 하드링크 (Hard Link)
- 하드링크 (Hard Link)
- 장점 ✅
- 데이터 안정성: 원본 파일이 삭제되어도 데이터가 보존됨
- 성능: 추가적인 파일 참조 과정이 없어서 접근 속도가 빠름
- 공간 절약: 실제 데이터는 하나만 존재하므로 디스크 공간을 절약
- 원자성: 원본과 완전히 동일한 파일이므로 일관성 보장
- 권한 동기화: 한 곳에서 권한을 변경하면 모든 하드링크에 반영
- 단점 ❌
- 파일시스템 제한: 같은 파일시스템 내에서만 생성 가능
- 디렉토리 불가: 디렉토리에는 하드링크 생성 불가능
- 순환 참조 위험: 시스템에서 디렉토리 하드링크를 막는 이유
- 관리 어려움: 어떤 파일들이 하드링크로 연결되어 있는지 파악하기 어려움
- 혼란 가능성: 여러 이름으로 같은 파일에 접근할 수 있어 헷갈릴 수 있음
- 장점 ✅
- 소프트링크 (Soft Link)
- 장점 ✅
- 유연성: 다른 파일시스템의 파일/디렉토리도 연결 가능
- 직관성: 실제 연결 대상을 쉽게 확인 가능 (ls -l로 확인)
- 디렉토리 지원: 디렉토리에도 심볼릭 링크 생성 가능
- 네트워크 지원: 네트워크 경로도 가리킬 수 있음
- 관리 용이: 링크와 원본의 관계가 명확함
- 상대/절대 경로: 두 방식 모두 지원
- 단점 ❌
- 의존성: 원본 파일이 삭제되면 링크가 깨짐 (broken link)
- 성능: 한 번 더 파일을 참조해야 하므로 약간의 오버헤드
- 경로 의존성: 원본 파일의 경로가 변경되면 링크가 깨짐
- 공간 사용: 미미하지만 별도의 inode와 디스크 공간 사용
- 권한 분리: 링크와 원본의 권한이 다를 수 있어 혼란 가능
- 장점 ✅
사용 권장 상황
- 하드링크 사용하면 좋을 때
- 백업 시스템: 데이터 손실 방지가 중요한 경우
- 버전 관리: 같은 내용의 파일을 여러 위치에서 안전하게 관리
- 성능 중요: 빠른 파일 접근이 필요한 경우
- 공간 절약: 큰 파일을 여러 곳에서 참조해야 하는 경우
- 소프트링크 사용하면 좋을 때
- 바로가기: 자주 사용하는 파일/디렉토리의 편리한 접근
- 설정 파일: 여러 위치에서 같은 설정을 참조
- 크로스 파일시스템: 다른 파티션이나 네트워크 리소스 연결
- 임시 연결: 필요에 따라 쉽게 생성/삭제가 가능한 링크
Kernel
- Kernel 의 역할
- 쉽게 말해서 커널은 컴퓨터의 “관리자” 같은 존재 모든 자원을 효율적으로 배분하고, 프로그램들이 안전하게 실행되도록 도와주는 역할을 함
- 하드웨어 관리
- CPU, 메모리, 디스크, 네트워크 카드 등 하드웨어 자원을 직접 제어
- 하드웨어와 소프트웨어 사이의 다리 역할
- 메모리 관리
- 물리 메모리와 가상 메모리 할당/해제
- 프로그램들이 서로의 메모리 영역을 침범하지 않도록 보호
- 메모리 부족 시 스왑 파일 관리
- 프로세스 관리
- 프로그램 실행, 종료, 일시정지
- CPU 스케줄링으로 여러 프로세스가 공평하게 CPU 사용
- 프로세스 간 통신(IPC) 관리
- 파일 시스템 관리
- 파일과 디렉토리 생성, 삭제, 읽기, 쓰기
- 여러 파일 시스템 지원 (NTFS, ext4, FAT32 등)
- 파일 권한 및 보안 관리
- 입출력(I/O) 관리
- 키보드, 마우스, 프린터, 네트워크 등 장치 제어
- 디바이스 드라이버를 통한 하드웨어 추상화
- 보안 및 권한 관리
- 사용자 인증 및 권한 검사
- 시스템 자원에 대한 접근 제어
- 악성 프로그램으로부터 시스템 보호
- 시스템 호출 제공
- 응용 프로그램이 커널 기능을 사용할 수 있는 인터페이스 제공
- 쉽게 말해서 커널은 컴퓨터의 “관리자” 같은 존재 모든 자원을 효율적으로 배분하고, 프로그램들이 안전하게 실행되도록 도와주는 역할을 함
TCP
- TCP Close Wait과 Time Wait의 차이
- close wait
- 첫 FIN을 받고 ACK를 보낸 상태, 어플리케이션의 종료를 기다리고 있다.
- FIN 신호를 받은 Passive Close 입장의 서버가 갖는 소켓 상태로서, Active Close에게 FIN 을 받은 뒤 Application의 연결 종료 프로세스가 완료되고 FIN 패킷을 보내기전 까지의 소켓 상태이다. 만약 소켓이 CLOSE_WAIT 상태로 계속 남아있다면 Application에 문제가 있다는 신호로 인식하고 적절한 조치를 취해야 한다.
- time wait
- 2번째 FIN을 받고 ACK를 보낸 상태, 동일 포트와 주소에 커넥션이 생성되지 않도록 하는 시간(2MSL time out)을 기다리는 상태
- 연결을 종료할때 발생하는 TCP 4 Way Handshake 에서 연결을 먼저 끊는 Active Close 쪽에서 발생하는 소켓 상태로 Active Close에서 마지막으로 보내는 ACK 패킷의 유실이나 패킷의 지연 도착에 대비하기 위해 발생되는 상태이다.
- close wait
https://medium.com/@hyukjuner/%EB%84%A4%ED%8A%B8%EC%9B%8C%ED%81%AC-%EC%86%8C%EC%BC%93-%EC%83%81%ED%83%9C-time-wait-close-wait-21813a5c625
- TIME_WAIT
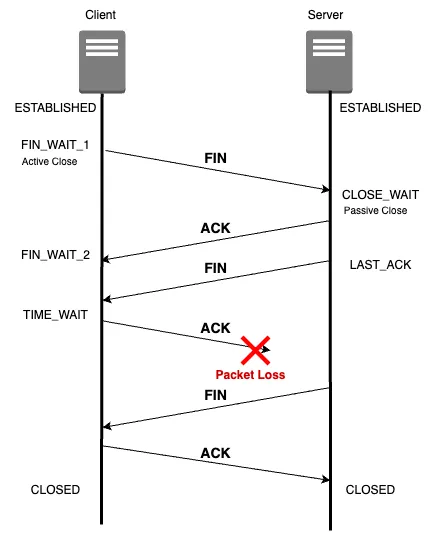
연결을 종료할때 발생하는 TCP 4 Way Handshake 에서 연결을 먼저 끊는 Active Close 쪽에서 발생하는 소켓 상태로 Active Close에서 마지막으로 보내는 ACK 패킷의 유실이나 패킷의 지연 도착에 대비하기 위해 발생되는 상태이다.
즉, 패킷이 유실되거나 지연 도착하는 것에 대비하도록 충분한 시간을 가지고 소켓을 정리하도록 하기 위함이고 이로써 네트워크 통신의 안정성을 향상시킬 수 있다.
그림 처럼 마지막 ACK 패킷이 유실 되었을 경우 서버 입장에선 ACK를 못받았기 때문에, 정상적인 연결 종료를 위해 FIN 패킷을 다시 보내게 된다. 이때 클라이언트는 TIME_WAIT 상태 덕분에 소켓을 아직 정리하지 않았고, 서버가 보낸 FIN 패킷을 다시 받아 마지막 ACK 패킷을 다시 전송할 수 있게 된다.
- CLOSE_WAIT
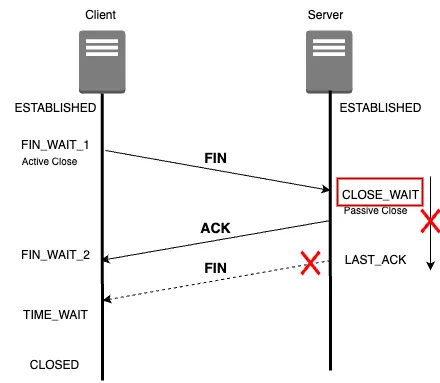
FIN 패킷을 받은 Passive Close 입장의 서버는 소켓의 상태를 CLOSE_WAIT 상태로 변환하고, OS 수준에서 ACK 패킷을 바로 보낸다.(리눅스는 커널, 윈도우는 시스템) 그와 동시에 Application에게 연결 종료를 요청하게 되고, Application의 연결 종료 프로세스 처리가 완료 되었을때 FIN 패킷을 보내게 된다.
만약, 소켓의 CLOSE_WAIT 상태가 지속된다면 OS 혹은 Application에 문제가 있는것이기 때문에 자연소멸되지 않는다. (Application이 FIN 패킷을 제대로 보내지 않은 것이기 때문)
CLOSE_WAIT 상태는 네트워크에 문제가 있다기 보다 Application에 문제가 발생하여 FIN 패킷을 만들어 내지 못하는 상태이기 때문에 엔지니어의 분석과 적절한 조치가 필요한 상태로 해석해야 한다.
- TCP 네이글 알고리즘이란?
- 보낼 수 있는 패킷을 바로 만들지 않고, 가능한 모아서 더 큰 패킷으로 만들어 한번에 보냄
- 네이글 알고리즘이 현재 잘 안쓰이는 이유
- 일반적으로 현재 네트워크 환경은 네이글 알고리즘의 작은 패킷을 잘 보내지 않는다. (대체로 페이로드가 큰 편임)
- 네이글 알고리즘은 설명하는 것과 같이 Delayed ACK와 상반되는 면이 있기 때문에, 네이글 알고리즘은 현재 잘 사용되지 않고 있다.
- packet / segment (tcp sequence number)
| 구분 | Segment | Packet |
|---|---|---|
| 계층 | 전송 계층 (Layer 4) | 네트워크 계층 (Layer 3) |
| 주소 | Port 번호 | IP 주소 |
| 역할 | 신뢰성, 흐름제어 | 라우팅, 주소지정 |
| 프로토콜 | TCP/UDP | IP |
- buffered io
- 100MB 파일 읽기 시나리오
- 상황: 프로그램이 한 줄씩 읽고 싶어 함.
- 가정: Buffered/IO 없다면?
- 프로그램:
1 2 3 4 5
프로그램: "한 줄 줘" → 디스크에서 50바이트 읽기 → 시스템 콜 1번 프로그램: "한 줄 줘" → 디스크에서 60바이트 읽기 → 시스템 콜 2번 프로그램: "한 줄 줘" → 디스크에서 40바이트 읽기 → 시스템 콜 3번 ... 100만번 반복 → 100만번 시스템 콜 → 개느림!
- 프로그램:
- 현실: Buffered IO를 도입한다면? ```
프로그램: “한 줄 줘” 라이브러리: “잠깐, 디스크에서 8KB 통째로 읽어올게” → 8192바이트를 내부 버퍼에 저장 → 버퍼에서 첫 번째 줄 리턴
프로그램: “한 줄 줘” 라이브러리: “버퍼에 있으니까 바로 줄게” → 버퍼에서 두 번째 줄 리턴 (디스크 접근 안 함!)
프로그램: “한 줄 줄” 라이브러리: “버퍼에서 세 번째 줄 리턴”
…100번 정도 반복…
- 프로그램: “한 줄 줘” 라이브러리: “버퍼 비었네, 다시 8KB 읽어올게” → 디스크에서 8192바이트 더 읽어옴 ```
- 핵심 포인트
- 너의 코드: “한 줄씩 줘” (작은 단위 요청)
- 라이브러리: “8KB씩 읽어서 버퍼에 저장하고 조금씩 나눠줄게” (큰 단위 실제 읽기)
- 결과: 100MB를 읽는데 디스크 접근은 12,800번만! 시스템 콜도 12,800번만!
- 100MB 파일 읽기 시나리오
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include <stdio.h>
#include <sys/time.h>
// Unbuffered 방식 (직접 read() 사용)
void read_unbuffered(const char* filename) {
int fd = open(filename, O_RDONLY);
char ch;
while (read(fd, &ch, 1) > 0) { // 1바이트씩 읽기
// process character
}
close(fd);
}
// Buffered 방식 (stdio 사용)
void read_buffered(const char* filename) {
FILE *fp = fopen(filename, "r");
int ch;
while ((ch = fgetc(fp)) != EOF) { // 1바이트씩 요청하지만 내부적으로 버퍼링
// process character
}
fclose(fp);
}
- skbuffer (sk_buff -> socket buffer)
- 커널 메모리에서 네트워크 패킷을 저장하고 관리하는 구조체
- 구조체 슈도코드
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
struct sk_buff { struct sk_buff *next; // 다음 패킷 포인터 struct sk_buff *prev; // 이전 패킷 포인터 unsigned char *head; // 버퍼 시작점 unsigned char *data; // 실제 데이터 시작점 unsigned char *tail; // 데이터 끝점 unsigned char *end; // 버퍼 끝점 unsigned int len; // 데이터 길이 unsigned int data_len; // 실제 데이터 길이 // 네트워크 계층별 헤더 포인터들 struct iphdr *iph; // IP 헤더 struct tcphdr *th; // TCP 헤더 struct ethhdr *mac; // MAC 헤더 // 기타 메타데이터... };
- 왜 필요한가?
- 계층 간 데이터 전달
1 2 3 4 5 6 7 8 9
애플리케이션 → 커널 → skbuffer 생성 ↓ 전송 계층 → TCP 헤더 추가 → skbuffer 수정 ↓ 네트워크 계층 → IP 헤더 추가 → skbuffer 수정 ↓ 데이터링크 계층 → MAC 헤더 추가 → skbuffer 수정 ↓ 물리 계층 → 네트워크로 전송 - 제로 카피 최적화
- 데이터를 복사하지 않고 포인터만 조작해서 성능을 크게 향상시키는 기법
-
skb_pusb(헤더 추가),skb_pull(헤더 제거),skb_put(데이터 추가) 등의 함수를 이용해 데이터를 조작할 수 있다.
- 계층 간 데이터 전달
- 커널 버퍼가 없다면?
- 메모리 복사 지옥
1 2 3 4 5 6
// 각 계층마다 새로운 버퍼 생성하고 복사 char *app_data = malloc(1500); char *tcp_data = malloc(1500 + 20); // TCP 헤더 공간 char *ip_data = malloc(1500 + 20 + 20); // IP 헤더 공간 char *eth_data = malloc(1500 + 20 + 20 + 14); // 이더넷 헤더 공간 // 총 4번의 메모리 복사 발생!
- 메모리 파편화 (각 패킷마다 여러개의 작은 버퍼들이 필요)
1 2 3 4 5 6
// 각 패킷마다 여러 개의 작은 버퍼들 malloc(1500); // 데이터 malloc(20); // TCP 헤더 malloc(20); // IP 헤더 malloc(14); // 이더넷 헤더 // → 메모리 파편화 심각!
- 성능 저하
1 2 3 4
// 100Mbps 네트워크에서 1500바이트 패킷 기준 // 초당 약 8,333개 패킷 // 각 패킷당 4번 복사 → 초당 33,332번 메모리 복사! // CPU 사용률 폭증!
- 동기화 문제
1 2 3 4 5 6
// 여러 스레드에서 동시에 패킷 처리 // 각 계층마다 별도 버퍼 → 복잡한 동기화 필요 mutex_lock(&tcp_buffer_lock); mutex_lock(&ip_buffer_lock); mutex_lock(ð_buffer_lock); // 데드락 위험!
- 메모리 복사 지옥
MAC Address 와 IP Address 를 이용한 컴퓨터 간 통신
- MAC Address 와 IP Address 를 이용한 컴퓨터 간 통신
-
https://run-it.tistory.com/18
- IP는 컴퓨터 간 대략적인 위치를 알아낼 때 (ex: xx시 yy동 zz아파트에 있어)
- MacAddress는 상세한 주소를 알고자 할 때 (ex: zz아파트 101동 503호야)
- 같은 네트워크에 있을 때
- A와 B가 통신을 하고 싶다고 가정하자.
- 1) A는 같은 네트워크에 있는 컴퓨터 전체에게 ARP Request를 브로드캐스트한다.
- 2) 브로드캐스트를 받은 컴퓨터 중 ARP Request가 적합한 컴퓨터가 A에게 ARP Reply를 전송한다.
- 3) 다른 컴퓨터는 받은 ARP Request를 폐기한다.
1
2
3
4
컴퓨터: 192.168.1.20은 같은 네트워크임
ARP Table 확인: "192.168.1.20의 MAC은 bb:bb:bb:bb:bb:bb"
프레임 생성: [목적지: bb:bb:bb:bb:bb:bb][출발지: aa:aa:aa:aa:aa:aa][IP패킷]
스위치: "bb:bb:bb:bb:bb:bb는 포트 2에 있네" → 포트 2로 전달
- 추가 질문
- 외부 아이피와 내부 아이피는 다르다. (외부: 112.216.3.62, 내부: 10.0.0.55) source 컴퓨터는 dest컴퓨터의 외부 아이피를 통해 전송하는데, 게이트웨이/라우터는 어떻게 외부 IP를 가지고 컴퓨터의 정확한 MAC Address를 식별하는가?
- 라우터는 Mac 주소로 찾는 게 아니라 NAT Table/포트포워딩으로 찾는다.
- NAT Table
- 라우터가 “누가 어떤 역할을 했는지” 기억해두는 메모장
- 포트 고갈 문제: 너무 많은 동시 연결
- 동일한 아이피의 다중 접속으로 인해 발생하는 문제
- 세션 만료: 장시간 비활성 연결
- P2P 문제: 외부에서 직접 접속 불가
- NAT Table
- 외부 IP -> 내부 IP 매핑은 미리 설정되어 있거나 기존 연결을 추적함.
- 라우팅 설정이 없으면 차단 (드랍)
- 포트포워딩 설정이 있으면 80번포트 -> 10.0.0.50:80, 22번포트 -> 10.0.0.51:22 전달
- 다른 네트워크에 있을 때
- A와 D가 통신을 하고 싶다고 가정하자.
그런데 A는 D의 IP 주소가 자신의 네트워크 대역과 다르 다는 것을 알고 있다.
- 1) A는 ARP로 라우터의 MAC주소를 알아내어 Default GateWay로 지정한다.
- 2) A는 Default GateWay에게 D에게 전달할 모든 패킷(전송할 데이터)을 전송한다.
- 3) Default GateWay는 라우팅을 통해 D가 속한 네트워크에 패킷을 보낸다.
- 4) D가 속한 네트워크에 패킷이 독착하면 ARP를 통해 D의 MAC주소를 알아낸 후, D에게 패킷을 전달한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
서울 → 부산 택배를 생각하라.
- 송장(IP): "부산 김철수"라고 끝까지 그대로
- 운송장(MAC): "서울 터미널 → 대전 터미널 → 부산 터미널" 각 구간마다 바뀜
PC A(192.168.1.10) → Server B(203.0.113.10)
1단계: PC A → 라우터1
프레임: [목적지MAC: 라우터1] [출발지MAC: PC A]
패킷: [목적지IP: 203.0.113.10] [출발지IP: 192.168.1.10]
2단계: 라우터1 → 라우터2
프레임: [목적지MAC: 라우터2] [출발지MAC: 라우터1] ← MAC 바뀜
패킷: [목적지IP: 203.0.113.10] [출발지IP: 192.168.1.10] ← IP 그대로
3단계: 라우터2 → Server B
프레임: [목적지MAC: Server B] [출발지MAC: 라우터2] ← 또 MAC 바뀜
패킷: [목적지IP: 203.0.113.10] [출발지IP: 192.168.1.10] ← IP 여전히 그대로
1.1.1.2 에서 상품 배송이 시작되었습니다.
배송할 상품이 EE::::EE 에 도착하였습니다.
EE:::::GG 에 배송 출발합니다.
배송할 상품이 HH:::::HH 에 도착하였습니다.
4.4.4.2에 배송이 완료되었습니다.
- 꼬리질문
- 동일 네트워크 대역에 있을 때에는 라우팅이 필요 없으니 IP가 없어도 통신되어야 하는 거 아님?
- 아니다. IP 있어야 한다.
- 어플리케이션 대상을 특정해야 하기 때문.
- 개발자가 코드에서 connect(“aa:bb:cc:dd:ee:ff”, 80) 이렇게 못 씀.
- connect(“192.168.0.4”, 80) 이렇게 써야지
- ARP는 IP -> MAC 변환 도구이기 때문에 IP가 필요함.
- ARP 자체가 IP 주소를 기반으로 동작함.
- IP 없이는 Mac을 찾을 방법이 없음. Computer A: “192.168.1.100이 누구야?” (ARP Request - 브로드캐스트) Computer B: “그거 나야, 내 MAC은 aa:bb:cc:dd:ee:ff” (ARP Reply)
- 포트/서비스 식별
- 네트워크 스택 구조 (Layer2, Layer3, Layer4)
- Layer3 IP (Internet Protocol) 필요!
- 동일 네트워크 대역에 있을 때에는 라우팅이 필요 없으니 IP가 없어도 통신되어야 하는 거 아님?
- 허브
- 1 계층 장비
- 들어온 패킷을 모든 포트로 브로드캐스팅
- 스위치
- 2 계층 장비
- Mac Table을 이용해 특정 포트로 전송하는 기능이 존재함.
- 목적지를 모르면 브로드캐스트, 알면 유니캐스트
- 유니캐스트: 1ㄷ1 통신 (A->B)
- 브로드캐스트: 1ㄷAll 통신 (A->B,C,D)
- 멀티캐스트: 1ㄷMany 통신 (A->B,C(그룹))
- 애니캐스트: 1ㄷNearest 통신 (A->가장 가까운 B)
- 목적지를 모르면 브로드캐스트, 알면 유니캐스트
- Full-duplex: 송신/수신 동시 가능
- Half-duplex (반이중)
- 한 번에 한 방향으로 통신 가능
- 송신 중에는 수신 불가, 수신 중에는 송신 불가
- 무전기
- Full-dplex (전이중)
- 동시에 송신/수신 가능
- 별도의 송신선과 수신선을 사용
- 전화기, 스위치
- Half-duplex (반이중)
- 각 포트가 독립적인 collision domain
- collision domain (충돌 도메인)
- 데이터 충돌이 발생할 수 있는 네트워크 영역
- 같은 collision doamin 안에서 동시에 두 기기가 데이터를 보내면 충돌 발생
- collision domain (충돌 도메인)
- 컴퓨터(Desktop)도 각 IP에 대한 Mac 주소 정보를 가지고 있는데 이것을 ARP Table이라고 한다.
- ARP Table을 활용해 어디 컴퓨터로 보낼지를 결정한다.
- 동일 네트워크면 해당 컴퓨터로
- 다른 네트워크면 게이트웨이/스위치/라우터로
- ARP Table을 활용해 어디 컴퓨터로 보낼지를 결정한다.
- Switch가 가지고 있는 Mac-Port 정보를 Mac Table이라고 한다.
- 일반적인 Layer 2 스위치
- ARP Table 없음
- IP 주소를 전혀 신경 쓰지 않아
- 오직 MAC 주소만 보고 프레임을 전달
- IP가 뭔지 모르겠고, MAC 주소만 알면 됨.
- Layer 3 스위치 (관리형/라우팅 기능 있는 스위치) (사실상 라우터임)
- 심지어 현재 가정용 공유기조차도 스위치 + 라우터 + Wifi 기능을 다 합쳐 놔서 Layer2 전용 스위치는 저가형 아니면 거의 없다고 봐도 됨.
- 포트 많은 라우터를 스위치라고 부르는 것이 현실임… ㅋㅋ
- ARP Table 있음
- 자신도 IP 주소를 가짐. (관리용)
- 라우팅 기능도 할 수 있음.
- VLAN 간 통신, 관리 인터페이스 등에 사용됨.
- 일반적인 Layer 2 스위치
TCP 프로토콜 소개
- TCP
- Sequence Number
- 순서 보장
- 패킷들이 다른 경로로 전송되어 순서가 바뀔 수 있음.
- sequence number로 원래 순서대로 재조립할 수 있음.
- 중복 제거
- 같은 패킷이 여러번 도착해도 sequence number로 중복을 감지하고 제거.
- 순서 보장
- Checksum
- 데이터 무결설 검증
- 전송 중에 데이터가 손상되었는지 확인
- 비트 에러나 패킷 변조 감지
- 네트워크 오류 방지
- 하드웨어 오류, 전자기 간섭 등으로 인한 데이터 손상 확인
- 손상된 패킷은 폐기 후 재전송 요청
- 데이터 무결설 검증
- Window Size
- Flow Control
- 수신자의 버퍼 크기에 맞춰 전송 속도 조절
- 수신자가 처리할 수 있는 만큼만 보내서 오버플로 방지
- 효율적인 전송
- 한 번에 여러패킷을 보낼 수 있음.
- ACK를 기다리지 않고 연속으로 전송 가능
- Flow Control
- Sequence Number
- 최적화 알고리즘
- Slow Start & Congestion Avoidance
- 초기 cwnd = 1 MSS
- Slow Start: cwnd를 지속적으로 증가 (매 RTT마다 2배)
- 임계점 도달 후: 선형적으로 증가 (Congestion Avoidance)
- Fast Retransmit & Fast Recovery
- 3개의 중복 ACK 받으면 즉시 재전송 (타임아웃 기다리지 않음)
- 패킷 손실 시 cwnd를 절반으로 줄이고 선형증가 시작
- Nagle Algorithm
- 작은 패킷들을 모아서 한 번에 전송
- 네트워크 효율성 증대
- Delayed ACK
- ACK를 즉시 보내지 않고 잠시 기다려서 여러 개를 묶어서 전송
- 또는 데이터와 함께 piggyback 해서 전송
- Sliding Window Protocol
- 송신자와 수신자가 각각 윈도우를 관리
- 파이프라인 방식으로 연속 전송 기능
- Selective Acknowledgment (SACK)
- 연속되지 않은 패킷들도 개별적으로 ACK 가능
- 불필요한 재전송 줄여서 효율성 향상
- TCP Tahoe, Reno, NewReno, CUBIC
- Tahoe: 패킷 손실 시 cwnd를 1로 리셋
- Reno: Fast Recovery 추가
- NewReno: 부분 ACK 처리 개선
- CUBIC: 고속 네트워크를 위한 3차 함수 기반 알고리즘
- Slow Start & Congestion Avoidance
- Sequence Number (SEQ)
- 전송하는 데이터의 첫 번째 바이트 번호
- 각 바이트마다 고유 번호를 가짐
- Acknowledgment Number
- 다음에 받고 싶은 바이트 번호
- 여기까지는 잘 받았으니 다음엔 이걸 보내줘. 라는 의미
- 정상 전송 과정 ``` 클라이언트 → 서버: “Hello” (5바이트) SEQ = 100, 데이터 = “Hello” (바이트 100~104)
서버 → 클라이언트: ACK ACK = 105 (“105번부터 보내줘” = “104번까지 잘 받았어”)
클라이언트 → 서버: “World” (5바이트) SEQ = 105, 데이터 = “World” (바이트 105~109)
서버 → 클라이언트: ACK ACK = 110
1
2
2. 패킷 순서가 바뀐 경우
전송 순서: 패킷A(SEQ=100, 데이터=”Hello”), 패킷B(SEQ=105, 데이터=”World”) 도착 순서: 패킷B 먼저, 패킷A 나중에
수신자 버퍼:
패킷B 도착 (SEQ=105): “어? 100~104가 없네?” → 임시 저장, ACK=100 전송 (여전히 100부터 원해)
패킷A 도착 (SEQ=100): “이제 순서대로 맞춰졌다!” → “HelloWorld” 순서대로 재조립 → ACK=110 전송 ```
누락 패킷 감지 및 재전송
- 타임아웃 기반 재전송 ``` 송신자:
- 패킷 전송 시 타이머 설정
- ACK 못 받으면 타임아웃 후 재전송
- RTT 기반으로 타임아웃 값 동적 조정 ```
- Fast Retransmit (빠른 재전송, 3ACK 수신 시 즉시 재전송)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
송신자가 보낸 패킷들: SEQ=100 "Hello" → 전송 성공 SEQ=105 "World" → 손실! SEQ=110 "Good" → 전송 성공 SEQ=114 "Day" → 전송 성공 수신자의 응답: ACK=105 (105부터 원해) ACK=105 (여전히 105부터 원해) - 중복 ACK ACK=105 (또 105부터 원해) - 중복 ACK ACK=105 (또또 105부터 원해) - 중복 ACK (3번째) 송신자: "3번 중복 ACK = 패킷 손실!" → 즉시 SEQ=105 패킷 재전송 (타임아웃 기다리지 않음)
- SACK (Selective Acknowledgment) 방식
1 2 3 4
일반 ACK: "105번까지 받았어, 106부터 보내줘" SACK: "105번까지 받았고, 110-114, 115-119도 받았어. 106-109만 보내줘" 더 정확한 누락 패킷 식별 가능!
- TCP는 메시지의 끝을 알려주는 플래그가 없다.
- ex) HTTP Keep-Alive 상태라서 TCP를 끊지 않는 상태. 이 상태에서 POST 요청의 끝을 TCP 헤더의 플래그나 옵션을 통해 상대방에게 알려줄 수 없음.
- TCP 자체에는 메시지의 끝을 알려주는 플래그가 없음 TCP는 스트림 기반 프로토콜이라서 바이트 스트림만 제공하고, 메시지 경계(message boundary)는 애플리케이션 계층에서 처리해야 함.
암호화 알고리즘
대칭키 암호화 방식 vs 비대칭키 암호화 방식 (공개키 암호화 방식)
- 대칭키 암호화 방식 vs 비대칭키 암호화 방식 (공개키 암호화 방식)
- 대칭키 암호화 방식 (비밀키 암호화 방식)
- 동일한 비밀키를 이용해 암/복호화
- 장점
- 매우 빠름 (하드웨어 가속 지원)
- 적은 연산량 (CPU 부담 적음)
- 강력한 보안 (AES-256 등)
- 작은 키 크기 (128~256bit)
- 단점
- 키 배포 문제 (어떻게 안전하게 키를 공유할 것인가?)
- 확장성 문제 (n명이면 n(n-1)/2 개의 키 필요)
- 디지털 서명 불가 (누가 보냈는지 확인 어려움)
- 대표 알고리즘
- AES (가장 많이 씀)
- ChaCha20
- 3DES (구식)
- 비대칭키 암호화 방식 (공개키 암호화 방식)
- 특정한 색깔에 대해서, 어떤 색깔 두개를 섞어 해당 특정한 색깔이 나오는지 구하는 것이 어렵다. 라는 것을 이용한 암호화 방식
- 장점
- 키 배포 쉬움 (공개키는 누구나 알아도 OK)
- 확장성 좋음 (n명이면 2n개의 키만 필요)
- 디지털 서명 가능 (누가 보냈는지 확인 가능)
- 키 관리 단순 (개인키만 비밀로)
- 단점
- 매우 느림 (대칭키보다 100~1000배 느림)
- 많은 연산량 (CPU 부담 큼)
- 큰 키 크기 (2048~4096bit)
- 큰 암호문 크기 (대칭키 암호화 방식보다 큼)
- 대표 알고리즘
- RSA (가장 유명)
- ECC (타원 곡선)
- EdDSA (서명용)
- 색깔로 이해하는 비대칭 키
- 기본 아이디어
- 섞기는 쉽지만, 분리하기는 어렵다.
- 빨강 + 파랑 = 보라 (쉬움)
- 보라 -> 빨강 + 파랑? (매우 어려움!)
- 섞기는 쉽지만, 분리하기는 어렵다.
- Diffie-Hellman 키 교환 방식 (색깔버전)
- 공통 색깔 정하기
- Alice와 Bob: “노란색을 공통으로 쓰자!” (공개) -> 공개 표준 파라메터
- 해커도 노란색을 알고 있음.
- 공통 색깔 정하기
- 각자 비밀 색깔 준비
- Alice의 비밀: 빨간색 🔴 (절대 비밀!) (클라이언트의 임시 개인키 a (빨간색) - 랜덤 생성, 세션 마다 다름)
- Bob의 비밀: 파란색 🔵 (절대 비밀!) (서버의 임시 개인키 b (파란색) - 랜덤 생성, 세션 마다 다름)
- 각자 비밀 색깔 준비
- 섞어서 교환
- Alice: 노란색 + 빨간색 = 주황색 🟠 → Bob에게 전송 (g^a mod p -> 주황색)
- Bob: 노란색 + 파란색 = 초록색 🟢 → Alice에게 전송 (g^b mod p -> 초록색)
- 해커: “주황색과 초록색을 봤지만, 원래 색깔을 모르겠네?”
- 섞어서 교환
- 최종 공통 색깔 만들기
- Alice: 초록색(받은 것 (노란색+파란색)) + 빨간색(자신의 비밀) = 갈색 🤎 (g^(ab) mod p -> 갈색)
- Bob: 주황색(받은 것 (노란색+빨간색)) + 파란색(자신의 비밀) = 갈색 🤎 (g^(ab) mod p -> 갈색)
- 양쪽 모두 동일한 공유 비밀 K 생성 (g^(ab) mod p)
- 참고로 이 갈색은 서로 연산해서 가진 결과지, 이 갈색을 네트워크 패킷에 실어 공유하지 않는다.
- 이후 이 갈색으로 대칭키 암호화 방식으로 암호화 통신을 진행한다.
- 결과: 둘 다 같은 갈색을 가짐! (공통 비밀키)
- 최종 공통 색깔 만들기
- 해커는??
- 해커가 아는 것: 노란색🟡, 주황색🟠, 초록색🟢
- 해커가 모르는 것: 빨간색🔴, 파란색🔵, 갈색🤎
- 해커: “갈색을 만들려면… 음… 불가능!” 😵
- 기본 아이디어
- 수학으로 번역
1 2 3 4 5 6 7
# 색깔 비유 실제 수학 노란색(공통) → g (생성원), p (소수) 빨간색(Alice) → a (Alice의 개인키) 파란색(Bob) → b (Bob의 개인키) 주황색 → g^a mod p (Alice 공개키) 초록색 → g^b mod p (Bob 공개키) 갈색(최종) → g^(ab) mod p (공통 비밀키)
- 수학적 어려움
- 쉬운 것:
g^a mod p계산 (빠른 거듭제곱) - 어려운 것:
g^a mod p에서a찾기 (이산로그 문제)
- 쉬운 것:
- RSA는 다른 비유
- 자물쇠 비유
- Bob이 열린 자물쇠📭를 Alice에게 줌 (공개키)
- Alice가 편지를 넣고 자물쇠를 잠금🔒
- Bob만 열쇠🗝️를 가지고 있어서 열 수 있음 (개인키)
- 자물쇠 비유
- 타원곡선은?
- 특별한 미로에서 출발점에서 n번 이동 → 도착점
- 이동은 쉬움 (공개키 계산)
- 역추적은 어려움 (개인키 찾기)
- 핵심 원리들
- 일방향 함수
- 🟡 + 🔴 = 🟠 (forward: 쉬움)
- 🟠 → 🟡 + 🔴? (backward: 어려움)
- 트랩도어 함수
- 특별한 정보(개인키)가 있으면 역방향도 쉬워짐!
- 🟠 + 🔴(비밀 정보) → 🟡 (가능!)
- 일방향 함수
SSL/TLS (Secure Sockets Layer / Transport Layer Security)
- SSL/TLS
- 공개키 암호화 알고리즘과 비밀키 암호화 알고리즘을 섞어 사용하는 하이브리드 암호화 통신 방식을 사용함.
- 현재 TLSv1.3 까지 존재함.
- TLSv1.3
- 보안 강화
- TLSv1.2 에서는 완전 순방향 비밀성 (PFS) 가 선택사항이었지만, TLSv1.3에서는 필수
- 각 세션마다 고유 임시 키를 생성해 서버의 개인키가 탈취되더라도 과거 통신 내용을 복호화해서 볼 수 없음.
- Diffie-Hellman Ephemeral (DFE) 알고리즘만 사용, 보안이 취약한 RSA 키 교환 방식은 완전히 제거
- Handshake(헨드셰이크) 과정의 획기적 개선
- 핸드셰이크 속도 2배 향상
- TLSv1.2 : 2-RTT (Round Trip Time) - 2번의 왕복 통신 필요
- Client Hello → Server Hello, Certificate, Server Hello Done
- Key Exchange, Client Finished → Server Finished
- TLSv1.3 : 1-RTT - 1 번의 왕복 통신으로 완료
- 1-RTT 통신을 위해 특정한 알고리즘만 사용함.
- ECDHE, DHE (Diffie Hellman Ephemeral)
- X25519, X448
- Client Hello (키 생성에 필요한 정보 포함) → Server Hello, Certificate, Server Finished
- 즉시 암호화된 데이터 교환 시작
- PFS (Perfect Forward Secrecy) 보장
- 과거 통신 내용이 나중에 털려도, 안전하게 지키는 기술
- 기존 문제점
- 서버의 개인키가 털리면 과거에 도청당한 모든 통신이 복호화 가능
- 예시: 해커가 1년전 네트워크 트래픽을 저장했다가, 나중에 서버 키를 털어서 모든 과거 통신 복호화 가능
- PFS 방식
- 매번 임시 키를 새로 만들어서 통신
- 통신 끝나면 그 임시 키는 완전히 삭제
- 서버 개인키가 털려도 -> 과거 통신은 여전히 안전!
- 1-RTT 통신을 위해 특정한 알고리즘만 사용함.
- 0-RTT (Zero Round Trip Time) 지원
- 이전에 방문한 사이트의 경우, 사전 공유 키(PSK)를 사용해서 핸드셰이크 과정 없이 즉시 데이터 전송 가능
- 다만 재전송 공격(replay attack) 위험이 있어서 권장되지 않음.
- TLSv1.2 : 2-RTT (Round Trip Time) - 2번의 왕복 통신 필요
- 핸드셰이크 속도 2배 향상
- 성능 개선
- 계산 오버헤드 감소
- 오래된 암호화 스위트 제거로 협상 과정 단순화
- Diffie-Hellman 키 교환 방식 통일로 처리 과정 최적화
- 클라이언트와 서버 모두의 계산 부담 감소
- 압축 기능 제거
- TLSv1.2에서 지원하던 압축 기능이 보안 공격에 악용될 수 있어 완전히 제거
- CRIME BREACH 같은 압축 기반 공격 방어
- CRIME: Compression Ratio Info-leak Made Easy
- TLS/SPDY 레벨 압축 악용
- 공격자가 희생자의 요청에 특정 내용 주입
- 압축된 데이터 크기 변화 관찰
- 크기 변화로 비밀 쿠키 값 추측
- BREACH: Browser Reconnaissance and Exfiltration via Adaptive Compression of Hypertext
- HTTP 응답 압축 악용
- 훨씬 더 광범위한 위험
- HTTP 압축 사용 (GZIP/DEFLATE)
- 사용자 입력이 응답에 반영
- 민감한 정보가 응답에 포함
- CRIME: Compression Ratio Info-leak Made Easy
- 계산 오버헤드 감소
- 버전 협상 매커니즘 개선
- 다운그레이드 공격 방지
- TLS 1.2까지는 버전 협상 과정에서 공격자가 개입해 이전 버전으로 강제 다운그레이드시킬 수 있었음
- TLS 1.3은 이런 공격을 원천 차단하도록 설계됨
- 다운그레이드 공격 방지
- 디지털 서명 개선
- ECDSA 강조
- TLS 1.2: RSA, DSA, ECDSA 등 다양한 서명 알고리즘 지원
- TLS 1.3: ECDSA와 RSA-PSS에 집중, 특히 ECDSA 강조
- ECDSA는 더 작은 키 크기로 더 빠른 연산과 적은 대역폭 사용 가능
- ECDSA 강조
- 보안 개선의 핵심
- 전체 핸드셰이크 암호화: TLS 1.3에서는 서버 인증서까지 암호화돼서 더 안전해
- 취약한 알고리즘 완전 제거: 알려진 보안 취약점이 있는 모든 암호화 방식 배제
- 강제적 PFS: 모든 연결에서 완전 순방향 비밀성 보장
- 보안 강화
- TLSv1.3
RSA (Rivest-Shamir-Adleman)
- 소인수 분해 문제
-
n = p × q에서 p, q 찾기 - 거꾸로 계산하기 엄청 어려운 수학 문제 중 하나.
- 큰 수를 소수로 나누기 = 쉬움
- 큰 수를 소수들의 곱으로 분해 = 어려움!
- 예시
- 15 = 3 × 5 ← 작은 수라 쉽게 분해 가능
- 12345678901234567890123456789 = ? × ?
- 이런 큰 수의 소인수 찾기는 극악의 난이도
- 키 생성 과정
- 두 개의 큰 소수 선택
- p = 매우 큰 소수 (예: 1024비트)
- q = 또 다른 매우 큰 소수 (예: 1024비트)
- 곱하기
- n = p × q <- 이게 공개키의 일부 (2048비트)
- 나머지 계산
-
φ(n) = (p-1) × (q-1)← 오일러 파이 함수 - e = 65537 (보통 이 값 사용) ← 공개키의 나머지
- d = e의 모듈로 역원 ← 개인키
-
- 두 개의 큰 소수 선택
- 공개되는 정보
- 공개키: (n, e)
- 모든 사람이 알 수 있음.
- 비밀 정보
- 개인키: (d, p, q)
- → 이걸 알려면 n을 p × q로 분해해야 함
- 공개키: (n, e)
- 공격자의 딜레마
- 공격자: “n을 보고 p, q를 찾아야 개인키를 알 수 있는데…”
- → 소인수분해 문제 = 현실적으로 불가능!
- 현실적인 크기 (RSA 키 크기별 보안성)
- 1024비트: 이미 위험 (권장 안 함)
- 2048비트: 2030년까지 안전
- 3072비트: 2050년까지 안전
- 4096비트: 더 오래 안전 (하지만 느림)
- 공격 기법
- 기본적인 방법
- 브루트 포스
- 모든 소수로 나눠보기 <- 비현실적
- 폴라드 로
- 조금 더 효율적 <- 여전히 어려움
- 브루트 포스
- 고급 방법
- 일반 수채 기법
- 가장 효율적 <- 그래도 지수적 시간
- 타원곡선 분해법
- 특수한 경우에만 효과적
- 일반 수채 기법
- 기본적인 방법
- 그러나 양자컴퓨터 나오면 다 깨짐.
- 이건 밑에 이산 로그 문제를 다루며 추가 설명.
-
- RSA (Rivest-Shamir-Adleman)
- Perfect Forward Secrecy (완전 순방향 비밀성) 이 없기 때문
- 정적 키 문제
- RSA는 정적 개인키 사용
- 서버의 개인키가 한 번 탈취되면 과거의 모든 통신을 복호화할 수 있음.
- 이건 매우 위험한 특성임
- RSA 키 교환 과정:
- 정수 분해의 어려움에 기반
- 클라이언트가 pre-master secret 생성
- 서버의 공개키로 암호화해서 전송
- 서버가 개인키로 복호화
- 정수 분해의 어려움에 기반
- 문제점:
- 서버의 개인키와 세션키 사이에 직접적인 연결이 있음
- 개인키가 탈취되면 → pre-master secret 복호화 → 모든 세션키 계산 가능
- 과거 통신까지 모두 노출
DHE / ECDHE
- 이산 로그 문제
-
g^x ≡ h (mod p)에서 x 찾기 - 거꾸로 계산하기 엄청 어려운 수학 문제 중 하나.
- 일반 로그
1 2
2^10 = 1024 log₂(1024) = 10 ← 이건 쉽게 계산 가능
- 이산 로그
1 2
g^x ≡ h (mod p)에서 x를 찾는 문제 예: 3^x ≡ 13 (mod 17)에서 x = ?
- 이산 로그 문제 설명:
- 주어진 것
- g (생성원): 기저값
- h (결과값): 계산 결과
- p (소수): 모듈로 값
- 찾아야 할 것
- x (지수): 얼마나 제곱했는지
- 핵심 포인트
- 순방향 계산: g^x mod p → 쉬움!
- 역방향 계산: x 찾기 → 극악의 난이도!
- 주어진 것
- 실제 예시
1 2 3 4 5 6 7 8 9
문제: 3^x ≡ 13 (mod 17)에서 x를 구하시오. 순방향으로 확인해보면: 3^1 mod 17 = 3 3^2 mod 17 = 9 3^3 mod 17 = 10 3^4 mod 17 = 13 ← 답: x = 4 작은 숫자라 금방 찾았지만...
- 왜 어려운가?
- 작은 숫자일 때
1 2
p = 17 정도면 직접 계산 가능 브루트 포스로 1, 2, 3, 4... 해보면 됨
- 큰 숫자일 때
1 2 3
p가 수백 자리 소수라면? 2^256 같은 경우의 수를 다 시도해야 함 → 우주가 멸망해도 계산 불가능!
- 현실적인 크기 ``` 실제 암호학에서 사용하는 크기:
- p: 2048비트 또는 3072비트 소수
- 경우의 수: 약 2^1024 ~ 2^1536
- 슈퍼컴퓨터로도 수십억 년 걸림 ```
- 작은 숫자일 때
- 암호학에서의 활용
- Diffie-Hellman 키 교환 ``` Alice: g^a mod p 계산해서 Bob에게 전송 Bob: g^b mod p 계산해서 Alice에게 전송 공통 키: g^(ab) mod p
→ 도청자는 g^a, g^b를 봐도 a, b를 모르니까 안전!
1
2. ElGamal 암호화
공개키: (g, p, h = g^x mod p) 개인키: x
→ h에서 x를 찾는 게 이산 로그 문제!
1
3. DSA 디지털 서명
서명 검증 시 이산 로그 문제의 어려움을 이용 ```
- 공격 기법
- 기본적인 방법
- 브루트 포스
- 모든 경우의 수를 시도 -> 비현실적
- Baby-step Giant-step 알고리즘
- 조금 더 효율적 -> 여전히 어려움
- 브루트 포스
- Pollard’s rho 알고리즘
- 좀 더 빠름 -> 그래도 지수적 시간
- Index Calculus 알고리즘
- 특수한 경우에만 효과적
- 기본적인 방법
- 타원곡선에서의 이산로그
- 일반 이산로그보다 더 어려운 문제
- 더 작은 키로도 같은 보안성 확보 -> ECC (Elliptic (일립틱) Curve Cryptography)(타원곡선 암호)의 기반
- 양자컴퓨터 나오면 다 깨지긴 함.
- Shor 의 알고리즘이 이산 로그 문제를 다항식 시간에 풀 수 있다.
- 몇 시간 ~ 며칠만에 해결
- 양자 컴퓨터에 뚫리는 암호들
- RSA
- DHE (Diffie Hellman Ephemeral(이페머럴))
- ECDHE (Elliptic Curve Diffie Hellman Ephemeral)
- DSA
- ECDSA
- ElGamal
- 공통점: 모두 이산 로그 문제나 소인수분해 문제에 의존
- 대안
- 양자 저항 암호 (Post-Quantum Cryptography)
- 살아남을 수 있는 것들
- 격자 기반 암호 (Lattice-based)
- CRYSTALS-Kyber (키 교환)
- CRYSTALS-Dilithium (디지털 서명)
- 해시 기반 암호
- SPHINCS+ (디지털 서명)
- 코드 기반 암호
- Classic McEliece (디지털 서명)
- 다변수 기반 암호
- Rainbow (하지만 최근에 깨짐)
- 양자 저항 암호 (Post-Quantum Cryptography)
- Shor 의 알고리즘이 이산 로그 문제를 다항식 시간에 풀 수 있다.
-
- DHE (Diffie-Hellman Ephemeral (이페머럴), Diffie-Hellman Exchange)
- Ephemeral: 임시적인, 한 번만 사용하는 것
- DHE 키 교환
- 이산 로그 문제의 어려움에 기반
- 양 쪽이 각각 임시 개인키 생성 (매번 다름)
- 공개 값 교환 (공개키 아님)
- 수학적 계산으로 동일한 공유 비밀 도출
- 이산 로그 문제의 어려움에 기반
- 보안 효과
- 세션 독립성: 각 세션이 완전히 독립적
- 과거 통신 보호: 현재 키가 탈취되어도 과거 통신은 안전
- 임시성: 세션 종료 후 키 폐기
- DFE 수학적 계산
- 공개 값 = g^(개인키) mod p
- 공유 비밀 = (상대방_공개값)^(내_개인키) mod p
- ECDFE 수학적 계산
- 공개점 = 개인키 × 생성점 (타원곡선 상의 점 연산)
- 공유 비밀 = 내_개인키 × 상대방_공개점 (타원곡선 상의 점 연산)
- DFE는 어떻게 매 세션마다 랜덤 키를 생성할 수 있는가?
- 클라이언트와 서버가 공개 파라미터 (p, g) 합의
- 클라이언트: 임시 개인키 a 생성 → A = g^a mod p 계산
- 서버: 임시 개인키 b 생성 → B = g^b mod p 계산
- 서버가 B를 클라이언트에게 전송
- 클라이언트가 A를 서버에게 전송
- 양쪽 모두 동일한 공유 비밀 K = g^(ab) mod p 계산
- 세션 종료 후 임시 키 a, b는 완전히 삭제
- 랜덤 키를 생성해 암호화를 진행한다면, 인증서는 왜 필요한가?
- 서버 인증에 여전히 인증서 필요 (MITM 공격 방지)
- 인증서가 없다면 공격자가 중간에서 각각 DHE 키교환 수행하는 중간자 공격 가능
- DFE 알고리즘은 서버에 dfparam.pem을 미리 등록해야 한다. 왜 등록하는가?
- 사실 필수로 등록할 필요 없음.
- dfparam.pem 사용하지 않으면 표준 파라메터가 사용됨.
- 표준 파라메터는 널리 사용되는 표준 파라메터에 대해 사전 계산 공격이 가능해 dhparam.pem을 따로 사용하는 경우는 있음.
- TLSv1.2 핸드셰이크 ```
- ClientHello (평문)
- 지원하는 cipher suites: DHE-RSA-AES256-GCM-SHA384, ECDHE-RSA-AES256-GCM-SHA384
- 지원하는 확장: supported_groups (ffdhe2048, ffdhe3072, secp256r1)
- ServerHello (평문)
- 선택된 cipher suite: DHE-RSA-AES256-GCM-SHA384
- 선택된 그룹: ffdhe3072
- Certificate (평문)
- 서버 인증서 (RSA 공개키 포함)
- ServerKeyExchange (평문이지만 서명됨!)
- DH 파라미터: p, g (ffdhe3072 표준 값들)
- 서버 DH 공개키: g^b mod p
- 서명: RSA_sign(hash(ClientRandom + ServerRandom + DH_params + DH_pubkey))
ServerHelloDone
- ClientKeyExchange (평문)
- 클라이언트 DH 공개키: g^a mod p
- 이후 암호화된 통신… ```
- ClientHello (평문)
- TLSv1.3 핸드셰이크 ```
- ClientHello (평문)
- supported_groups: ffdhe2048, ffdhe3072, X25519
- key_share: 각 그룹별 미리 계산된 공개키들!
- ServerHello (평문이지만 즉시 암호화 시작)
- 선택된 그룹: ffdhe3072
- key_share: 서버의 해당 그룹 공개키
- 이후 모든 메시지 암호화! ```
- ClientHello (평문)
- 중간자 공격 방어 매커니즘
- 디지털 서명으로 무결성 보장
1 2 3 4 5 6 7 8 9 10 11 12
ServerKeyExchange 메시지 = { DH_params (p, g), Server_DH_pubkey (g^b mod p), Signature = RSA_sign( hash( ClientRandom + ServerRandom + DH_params + Server_DH_pubkey ) ) } - 어떻게 평문만 교환했는데 암호화 통신이 가능한가? ``` 공개 파라미터: p (큰 소수), g (생성기) 이 공개 파라메터에는 표준 파라메터가 될 수도, dhparam.pem 이 될 수도 있다.
- 표준 파라메터는 아까 말했던 것처럼 이미 RFC등에서 정해둔 전 세계 표준 안전한 암호화 파라메터(p,q) 이고
- dhparam은 p,q 값을 커스텀해서 미리 생성한 뒤, pem 형식(base64 인코딩) 으로 인코딩한 값이다.
- dhparam.pem을 사용하면 1-RTT 안됨. 이는 이따 설명
- 아무튼 그래서 TLSv1.3에서는 dhparam.pem 사용을 막고 표준 그룹들만 강제로 사용하도록 함.
클라이언트:
- 비밀키 a 생성 (랜덤)
- 공개키 A = g^a mod p 계산
- A를 서버에 전송 (평문)
서버:
- 비밀키 b 생성 (랜덤)
- 공개키 B = g^b mod p 계산
- B를 클라이언트에 전송 (평문)
양쪽 모두:
- 공유 비밀 K = g^(ab) mod p 계산
예시 (작은 숫자로): p = 23, g = 5
클라이언트: a = 6 (비밀) A = 5^6 mod 23 = 15625 mod 23 = 8 → “8”을 서버에 전송
서버: b = 15 (비밀) B = 5^15 mod 23 = 30517578125 mod 23 = 19 → “19”를 클라이언트에 전송
공유 비밀 계산: 클라이언트: K = 19^6 mod 23 = 47045881 mod 23 = 2 서버: K = 8^15 mod 23 = 35184372088832 mod 23 = 2
→ 둘 다 같은 비밀 “2”를 얻음! ```
- 이것이 왜 안전한가?
- 공개 정보:
- p = 23
- g = 5
- A = 8 (클라이언트 공개키)
- B = 19 (서버 공개키)
- 공격자가 알고 싶은 것:
- a (클라이언트 비밀키)
- b (서버 비밀키)
- K = g^(ab) mod p (공유 비밀)
- 공격자의 딜레마
A = g^a mod p에서 a를 구하려면? → 8 = 5^a mod 23에서 a = ? → 이산 로그 문제: 매우 어려움!
-
실제 크기 (2048비트)에서는:
- p는 617자리 숫자
- 현재 기술로는 수십억 년 필요
- 공개 정보:
- 핵심 포인트
- 비밀은 절대 전송되지 않음
- 개인키 a, b는 각자 메모리에만 존재
- 네트워크로는 공개키 A, B만 전송
- 수학적 일방향성
- g^a mod p → a 계산은 매우 어려움 (이산 로그)
- 하지만 a → g^a mod p 계산은 쉬움
- 공유 비밀의 동일성
- (g^a)^b = (g^b)^a = g^(ab) mod p
- 수학적으로 보장된 동일한 결과
- 비밀은 절대 전송되지 않음
- 디지털 서명으로 무결성 보장
이것이 바로 “평문으로 교환했는데도 안전한 암호화가 가능”한 Diffie-Hellman 키 교환 알고리즘
- DHE를 사용한 TLSv1.3 통신 방식
- Client가 이미 지원하는 공개 파라메터 표준 그룹들(표준 파라메터들)에 대한 공개키를 미리 계산해서 같이 보냄.
- 즉, ClientHello를 보내기 이전에 이미 비밀키를 랜덤하게 생성하고, 표준 파라메터들을 통해 공개키를 계산
- Client -> Server: Client Hello (공개키 전송)
- Server -> Client: Server Hello + 나머지 (서버의 비밀키 랜덤 생성 후 공개키 계산 후 보냄)
- 서버의 공개키를 key_share로 응답
- 동시에 Certificate, CertificateVerify, Finished 도 같이 보냄.
- 끝!
- 클라이언트가 추가로 공개키 안보냄.
- 양쪽 다 공유 비밀 계산 완료.
- 클라이언트도 Certificate, CertificateVerify, Finished 보내면서 마무리.
- Client가 이미 지원하는 공개 파라메터 표준 그룹들(표준 파라메터들)에 대한 공개키를 미리 계산해서 같이 보냄.
- 이것처럼, dhparam.pem과 같은 커스텀을 막음으로써 1-RTT를 구현하였다.
- dhparam.pem이 허용된다면, ServerHello 시점 이후에서야 클라이언트가 공개 파라메터를 받을 수 있어 1-RTT가 아니라 2-RTT가 되어야 한다.
- ECDHE (Elliptic Curve Diffie-Hellman Ephemeral)
- DHE의 타원곡선 버전 (타원곡선 기반 Diffie-Hellman 키 교환 알고리즘)
- 타원곡선에서의 이산로그 문제
- DHE와의 차이점 (DFE vs ECDFE)
- 수학적 기반: 유한체에서의 이산 로그 vs 타원곡선에서의 이산 로그
- 키 크기: 2048bit 이상 필요 vs 256bit로도 충분
- 성능: 상대적으로 느림 vs 훨씬 빠름
- 메모리 사용: 많음 vs 적음
- 배터리 소모: 높음 vs 낮음
- ECDHE의 장점
- 효율성
- 256비트 ECDHE ≈ 3072비트 RSA 보안 수준
- 모바일 기기에 최적화
- 성능
- RSA 2048bit: 100
- DHE 2048bit: 80
- ECDHE 256bit: 200 (가장 빠름)
- 미래지향적
- 양자 컴퓨터 공격에 상대적으로 강함 (완전하지는 않음)
- 현대 암호학의 표준
- 효율성
- ECDHE의 단점
- 구현의 복잡성과 일부 곡선의 신뢰성 문제가 있음.
- 곡선: 주로 NIST P-256, P-384 등을 사용함
- 표준: 오래된 NIST 표준들
- 키 크기: 256bit
- 변형체
- X25519 (Curve25519 Bernstein 설계 - RFC 7748)
- X25519가 조금 더 빠름. (몽고메리 래더 알고리즘)
- ECDHE가 구현에 따라 사이드채널 공격에 취약할 수 있으나 X25519는 사이드채널 공격에 강하게 설계됨.
- 구현 복잡도가 훨씬 단순함.
- NIST_P256_구현 = 복잡함 (좌표 변환, 예외처리 많음)
- 이러한 복잡한 구현 및 예외 처리로 인해 사이드채널 공격 가능성 존재.
- X25519_구현 = 단순함 (항상 같은 공식)
- NIST_P256_구현 = 복잡함 (좌표 변환, 예외처리 많음)
- X448 (Curve448)
- X25519에 비해 보다 더 높은 보안 수준 제공
- TLS 1.3 지원 곡선들:
- secp256r1 (P-256) ← 기존 ECDHE
- secp384r1 (P-384) ← 기존 ECDHE
- x25519 ← 새로운 스타일
- x448 ← 새로운 스타일
- 몽고메리 래더 알고리즘
- 타원곡선에서 빠르고 안전하게 곱셈하는 알고리즘
- 항상 똑같은 패턴으로 계산해서 해커가 눈치 못 채게 하자.
- 일반적인 방법 문제점: 연산 시간이 달라서 해커가 비트 패턴을 추측 가능
1 2 3 4 5 6 7 8 9
# 예: 13 × P (P는 타원곡선 점) 13 = 1101₂ # 이진수로 변환 # 기존 방법: 비트에 따라 다른 연산 for bit in "1101": if bit == "1": 더하기_연산() # 시간 걸림 else: 아무것도_안함() # 빠름 ← 여기서 정보 누출!
- 몽고메리 래더의 해결책 -> 항상 똑같은 연산 -> 일정한 시간의 연산으로 해커가 비트를 추측 불가하게 만듬.
1 2 3 4 5
# 몽고메리 래더: 항상 똑같은 연산! for bit in "1101": 항상_더하기_연산() # 항상 실행 항상_두배_연산() # 항상 실행 # 시간이 항상 일정! 해커가 비트를 못 알아냄
- 보안상 장점
- 일정한 실행 시간: 타이밍 공격 방지
- 일정한 메모리 접근: 캐시 공격 방지
- 일정한 전력 소모: 전력 분석 공격 방지
- 성능상 장점
- 몽고메리 좌표계 사용으로 나눗셈 연산 최소화
- 고정된 메모리 접근 패턴으로 캐시 효율 극대화
- 쉬운 이유
- 일반 방법: 횡단보도에서 “빨간불이면 멈춤, 초록불이면 걸음” -> 관찰자가 신호등 색깔 유추 가능
- 몽고메리 래더: “항상 제자리걸음 + 한발짝 앞으로” -> 관찰자가 뭘 하는지 모름
- 사이드 채널 공격으로 개인키 추출을 노린다.
- 구체적인 공격 방법들
- 스칼라 곱셈 타이밍 공격
- 캐시 기반 공격
- 전력 분석 공격
- 예외 기반 공격
- 구체적인 공격 방법들
- 사이드채널 공격
- 암호 알고리즘 자체가 아니라 물리적 구현에서 새어나오는 정보를 노리는 공격
- 암호는 안전하지만, 그걸 실행하는 컴퓨터가 흔적을 남긴다
- 타이밍 공격
1 2 3 4 5 6 7 8
# 패스워드 체크 함수 def check_password(input_pw, real_pw): for i in range(len(real_pw)): if input_pw[i] != real_pw[i]: return False # 여기서 바로 리턴! return True # 해커: "첫 글자가 맞으면 더 오래 걸리네?" # 시간 측정으로 패스워드를 한 글자씩 맞춰감!
- 전력 분석 공격 ```py 스마트카드가 암호화 할 때:
- 0 처리할 때: 전력 소모 적음
- 1 처리할 때: 전력 소모 많음 해커: 전력 소모 패턴 보고 암호키 추측! ```
- 전자기파 공격
- CPU가 연산할 때 전자기파를 방출
- 해커가 안테나로 측정해서 내부 데이터 유추
- 캐시 공격
1 2 3 4 5 6
# 메모리 접근 패턴으로 정보 누출 if secret_bit == 1: array[1000].read() # 캐시 미스 발생 else: array[0].read() # 캐시 히트 # 해커: 캐시 히트/미스 패턴으로 secret_bit 추측!
- 음향 공격
- 키보드 타자 소리로 패스워드 유추 (과거 폰 다이얼 소리로 개인정보 유추)
- CPU 팬 소리 변화로 연산 내용 추측
- 방어 방법
- 일정한 실행 시간
- 마스킹
- 블라인딩
- 중요한 이유
- 수학적으로 완벽한 암호도 물리적 구현에서 털릴 수 있음.
- IoT, 스마트카드 등에서 특히 취약
- DHE의 타원곡선 버전 (타원곡선 기반 Diffie-Hellman 키 교환 알고리즘)
ECDSA
-
ECDSA (Elliptic Curve Digital Signature Algorithm)
- 타원곡선 디지털 서명 알고리즘
- 기본 개념
- 타원곡선 암호학 (ECC) 을 기반으로 하는 디지털 서명 알고리즘
- RSA와 비슷한 보안성을 제공하지만 훨씬 작은 키 크기 사용
- 장점
- 효율성
- RSA 2048 bit 와 같은 보안 수준을 256 bit 로 달성
- 빠른 연산
- 키 생성, 서명, 검증이 모두 빠름
- 작은 메모리
- 모바일이나 IoT 디바이스에 적합
- 낮은 대역폭
- 네트워크 전송에 유리
- 효율성
- 단점
- 구현 복잡성
- RSA보다 구현이 훨씬 복잡
- 타원곡선 수학에 대한 깊은 이해 필요
- 잘못 구현하면 보안 취약점이 생기기 쉬움
- 사이드 채널 공격 취약성
- 타이밍 공격
- 연산 시간으로 개인키 유추 가능
- 전력 분석 공격
- 전력 소비 패턴으로 개인키 유추 가능
- 전자기 공격
- 전자기 신호 분석
- 하드웨어 구현 시 특히 주의해야 함.
- 타이밍 공격
- 양자 컴퓨텅 취약성
- Shor’s Algorithm
- 양자 컴퓨터로 쉽게 깨짐
- RSA보다 더 빨리 무력화될 가능성
- 양자 내성 암호로 교체 필요
- Shor’s Algorithm
- 난수 생성의 중요성
- k값 재사용
- 치명적 보안 취약점
- 약한 난수 생성기
- 개인키 노출 위험
- 플레이스테이션 3 해킹 사례 (k값 고정 사용)
- k값 재사용
- 표준화 및 곡선 선택 이슈
- NSA 백도어 의혹
- 일부 표준 곡선에 대한 우려
- Dual_EC_DRBG 사건
- NSA가 의도적으로 약한 곡선 추천
- 어떤 곡선을 선택할지 결정하기 어려움
- NSA 백도어 의혹
- 특허 문제
- 일부 ECC 기술에 특허 존재
- 상업적 사용 시 라이선스 비용 발생 가능
- 성능 예측의 어려움
- 플랫폼별로 성능 차이가 큼
- 최적화가 복잡하고 어려움
- 디버깅 어려움
- 수학적 복잡성으로 인한 디버깅 어려움
- 오류 발견이 늦어질 수 있음
- 상호 운영성
- 다양한 구현체 간 호환성 문제
- 파라미터 설정 차이로 인한 문제
- 구현 복잡성
- 사용 사례
- 비트코인
- 트랜잭션 서명에 사용
- SSL / TLS
- 웹 보안 인증서
- SSH
- 공개 키 인증
- JWT
- 토큰 서명
- 모바일 앱
- 앱 스토어 서명
- 비트코인
- 실제 사고 사례
- 플레이스테이션 3 (2010)
- k값을 고정으로 사용해서 개인 키 노출
- 콘솔 완전 해킹됨
- 안드로이드 (2013)
- 약한 난수 생성기로 인한 비트코인 지갑 해킹
- Duel_EC_DRBG (2013)
- NSA가 의도적으로 약한 곡선 표준화
- 플레이스테이션 3 (2010)
- 동작 방식
- 키 생성
- 타원곡선과 기준점(G) 선택
- 개인키(d) 랜덤 정수
- 공개키(Q): d * G (타원곡선 상의 점)
- 키 생성
- 서명 생성
- 메시지 해시 계산
- 랜덤 수 k 생성
- r = (k * G) 의 x좌표
- s = k^(-1) * (메시지 해시 + d * r) mod n
- 서명 (r, s) 생성
- 서명 검증
- 공개키와 서명으로 점 계산
- 원래 메시지 해시와 비교
- 메시지 해시 계산
- u1 = s^(-1) * 메시지 해시
- u2 = s^(-1) * r
- 검증 점: u1 * G + u2 * Q
- 보안 강도 비교
- ECDSA 256 bit ≈ RSA 3072 bit
- ECDSA 384 bit ≈ RSA 7680 bit
- 요약
- 암호화폐나 최신 웹 서비스에서 널리 쓰이는 현대적인 서명 알고리즘
TLS Certificate
- TLS Certificate
- Certificate: “내 신분증이야”
- 서버의 인증서를 클라이언트에게 보내는 메시지
- 인증서 = “내가 example.com이야!” 라는 신분증
- CA(인증기관)가 서명한 공개키와 도메인 정보 포함
- TLS CertificateVerify
- CertificateVerify: “내가 진짜 주인이야”
- 서버가 실제로 인증서의 개인키를 가지고 있다는 증명
- 지금까지의 핸드셰이크 메시지들을 개인키로 서명해서 보냄
- “내가 진짜 이 인증서 주인이야!” 라는 증명
- Finished
- Finished: “우리 대화 변조 안됐지?”
- 핸드셰이크 무결성 검증
- 지금까지 주고받은 모든 메시지들의 해시값을 계산
- 공유비밀로 MAC을 만들어서 보냄
- “우리가 주고받은 메시지들이 변조되지 않았어!” 확인
- 대칭키 알고리즘은 초당 수 GB 단위 처리가 가능
- ECHDE: 초당 수천~만번 연산
- 그래서 TLS에서
- 핸드셰이크: ECDHE로 키 교환 (한번만)
- 실제 통신: AES같은 빠른 대칭키 사용
- 그리고 TLSv1.3에서 KeyUpdate 매커니즘은 실제로 존재함.
- 초기 DHE/ECDHE로 Master Secret 생성
- 파생: 여러 application traffic secret들 갱신
- 업데이트: 필요 시 새로운 키들로 갱신
- 그러나 자동 주기적 업데이트는 없고, 디폴트로 활성화도 안되어 있다.
- 수동 트리거만 가능.
- 언제 KeyUpdate 하나?
- 애플리케이션 명시적 요청
- 대량 데이터 전송 후(보안 강화)
- 라이브러리/서버 설정에 따라서 다름
- 현실적으로
- 대부분의 웹 브라우징에서는 KeyUpdate 안함
- 단기 연결이 많아서 굳이?
- 장기 연결 (WebSocket, gRPC 등) 에서만 가끔 사용
- 대부분의 웹 브라우징에서는 KeyUpdate 안함
- MTLS (Mutual TLS)
- 클라이언트와 서버 모두 인증서 제공
- 양방향 인증
- TLSv1.3 MTLS 통신 과정 (1-RTT)
- C->S: Client Hello
- S->C: Server Hello, Certificate, Server Key Exchange, Certificate Request, Server Hello Done
- C->S: Certificate, Client Key Exchange, Certificate Verify, Change Cipher Spec, (Finished, Encrypted Handshake Message)
- nginx 설정 예시
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
server { listen 443 ssl; server_name example.com; # 서버 인증서 설정 (서버가 클라이언트에게 보여줄 신분증) ssl_certificate /path/to/server.crt; ssl_certificate_key /path/to/server.key; # 클라이언트 인증서 검증 설정 (핵심!) ssl_client_certificate /path/to/ca.crt; # 클라이언트 인증서를 검증할 CA ssl_verify_client on; # 클라이언트 인증서 검증 활성화 # SSL 프로토콜 설정 ssl_protocols TLSv1.2 TLSv1.3; ssl_ciphers ECDHE-RSA-AES256-GCM-SHA384:ECDHE-RSA-AES128-GCM-SHA256; ssl_prefer_server_ciphers off; # 추가 보안 설정 ssl_session_cache shared:SSL:10m; ssl_session_timeout 10m; location / { # 클라이언트 인증서 정보를 백엔드에 전달 (선택사항) proxy_set_header X-SSL-Client-Cert $ssl_client_cert; proxy_set_header X-SSL-Client-Verify $ssl_client_verify; proxy_set_header X-SSL-Client-S-DN $ssl_client_s_dn; proxy_pass http://backend; } }
- 왜 ca 인증서가 필요한가?
ssl_client_certificate /path/to/ca.crt; # 클라이언트 인증서를 검증할 CA- 클라이언트 인증서가 아니라, 클라이언트의 ca 인증서를 입력하고 있다. why?
- 클라이언트 인증서 검증 방식
1 2
클라이언트 → 서버: "여기 내 인증서야!" (클라이언트가 자신의 .crt 보냄) 서버: "이 인증서가 진짜인지 어떻게 확인하지?" 🤔
- CA 인증서의 역할
- CA 인증서는 도장 같은 역할
- 클라이언트 인증서에는 CA가 서명한 디지털 서명이 들어있음.
- 서버는 CA인증서로 “이 서명이 진짜 그 CA가 한 거 맞나?” 를 확인.
1 2
클라이언트 인증서 = 졸업증명서 CA 인증서 = 학교 도장 (서명)
- CA 인증서는 도장 같은 역할
- 실제 검증 과정
- 클라이언트가 자신의 인증서르 서버로 보냄
- 서버가 받은 클라이언트 인증서를 분석
- “이 인증서는 누가 발급했나?” -> CA 정보 확인
- “이 CA 서명이 진짜인가?” -> CA 인증서로 검증
- “유효가긴아 안 지났나?” -> 날짜 확인
- “폐기되지 않았나?” -> CRL 확인
- 비유로 설명
1 2 3 4 5 6 7
직원 신분증 (클라이언트 인증서) = 개인 사원증 회사 도장 (CA 인증서) = 인사팀 서명/도장 보안요원: "사원증 보여주세요" 직원: "여기 제 사원증이요" (클라이언트 .crt) 보안요원: "이 사원증이 진짜 우리 회사 것인가?" → 인사팀 도장 확인 (CA 인증서로 검증) - 왜 모든 클라이언트 인증서를 서버에 저장하지 않나?
1 2 3 4 5
# 이건 비효율적! ssl_client_certificate /etc/nginx/ssl/client1.crt; ssl_client_certificate /etc/nginx/ssl/client2.crt; # 이런 식으로 안 됨 ssl_client_certificate /etc/nginx/ssl/client3.crt; # ... 수백 개의 클라이언트마다 각각 설정?
1 2
# 이게 효율적! ssl_client_certificate /etc/nginx/ssl/ca.crt; # CA 하나로 모든 클라이언트 검증
- 실제 파일 구조
1 2 3 4 5 6 7 8 9
클라이언트 측: ├── client.crt ← 클라이언트가 서버에 보내는 인증서 ├── client.key ← 클라이언트의 개인키 (서버로 안 감!) └── ca.crt ← 서버 검증용 (클라이언트도 가지고 있음) 서버 측: ├── server.crt ← 서버 인증서 ├── server.key ← 서버 개인키 └── ca.crt ← 클라이언트 인증서 검증용
- PDP (Policy Decision Point) - Control Server
- 정책 결정을 내리는 지점
- PIP (Policy Information Point)
- 정책 결정에 필요한 추가 정보를 제공
- PEP (Policy Enforcement Point)
- 실제로 정책을 시행하는 지점
- PAP (Policy Administration Point)
- 정책을 작성/관리하는 지점
-
인증 / 인가
- 인증 (Authentication)
- “당신이 누구인지” 확인하는 과정
- “Who are you?” (신원 확인)
- 사용자 신분을 검증하는 단계
- 본인임을 증명하는 과정
- 방법
- 지식 기반: 패스워드, PIN 번호
- 소유 기반: 스마트카드, OTP, 휴대폰
- 생체 기반: 지문, 홍채 , 얼굴인식
- 다중 인증: 2FA, MFA (위 방법들 포함)
- 인가 (Authorization)
- “당신이 무엇을 할 수 있는지” 결정하는 과정
- “What can you do?” (권한 부여)
- 인증된 사용자의 접근 권한 설정
- 리소스에 대한 접근 범위 설정
- 방법
- 역할 기반: RBAC (Role-Based Access Control)
- 속성 기반: ABAC (Attribute-Based Access Control)
- 접근제어 목록: ACL (Access Control List)
- 정책 기반: PBAC (Policy-Based Access Control)
구분 인증 (Authentication) 인가 (Authorization) 질문 “당신이 누구인가?” “무엇을 할 수 있는가?” 목적 신원 확인 권한 부여 순서 먼저 실행 인증 후 실행 결과 로그인 성공/실패 접근 허용/거부 - 인증 (Authentication)
-
보안의 3대 요소 (6대 요소) (CIA + AAN)
- 전통적 3대 요소 (CIA Triad)
- 기밀성 (Confidentiality)
- 허가된 사람만 정보에 접근 가능
- 암호화, 접근제어, 권한 관리
- 예: 개인정보, 기업 기밀, 군사 정보
- 무결성 (Integrity)
- 정보가 무단으로 변경되지 않음을 보장
- 해시, 디지털 서명, 체크섬
- 예: 파일 변조 방지, 메시지 위변조 방지
- 가용성 (Availability)
- 필요할 때 시스템과 데이터에 접근 가능
- 이중화, 백업, 복구 시스템
- 예: 서버 다운타임 최소화, DDoS 방어
- 인증성 (Authentication)
- 사용자나 시스템의 신원 확인
- 패스워드, 생체인식, 2FA, 인증서
- 예: 로그인 시스템, 신분 확인
- 인가/접근제어 (Authorization)
- 인증된 사용자의 권한 범위 결정
- 역할 기반 접근제어(RBAC), ACL
- 예: 관리자 권한, 파일 접근 권한
- 부인 방지 (Non-repudiation)
- 행위에 대한 증거 제공, 부인 불가능
- 디지털 서명, 로그 기록, 타임스탬프
- 예: 전자계약, 거래 기록
- 기밀성 (Confidentiality)
- 실제 적용 예시
- 기밀성: 계좌정보 암호화
- 무결성: 거래 내역 위변조 방지
- 가용성: 24시간 서비스 제공
- 인증성: 공인인증서, OTP
- 인가: 본인 계좌만 접근
- 부인 방지: 거래 로그, 전자서명
- 전통적 3대 요소 (CIA Triad)
-
무결성과 정합성
- 무결성
- 데이터가 변조되지 않고 원래 상태를 유지
- 데이터의 정확성과 완전성 보장
- 외부 공격이나 오류로부터 데이터 보호
- 데이터가 손상되지 않았는가?
- 종류
- 개체 무결성: 기본키 중복 금지
- 참조 무결성: 외래키 관계 유지
- 도메인 무결성: 데이터 타입/범위 준수
- 사용자 정의 무결성: 비즈니스 규칙 준수
- 정합성
- 데이터들 간의 논리적 관계가 올바르게 유지되는 것
- 시스템 전체의 일관된 상태 유지
- 데이터들 사이의 모순이 없는 상태
- 데이터들이 서로 맞아떨어지는가?
- 종류
- 강한 정합성: 모든 노드가 동일한 데이터
- 약한 정합성: 일시적 불일치 허용
- 최종 정합성: 시간이 지나면 일치
- 보안 관점
- 무결성 보장 기술:
- 해시 함수: SHA-256, MD5
- 디지털 서명: RSA, ECDSA
- 체크섬: CRC, 패리티 비트
- MAC: HMAC
- 정합성 보장 기술:
- 트랜잭션: 원자성 보장
- 락 메커니즘: 동시 접근 제어
- 복제: 마스터-슬레이브 동기화
- 합의 알고리즘: Raft, PBFT
- 무결성 보장 기술:
- 분산 시스템에서의 차이
- CAP 정리:
- Consistency (정합성)
- Availability (가용성)
- Partition tolerance (분할 내성)
- CAP 정리:
구분 무결성 (Integrity) 정합성 (Consistency) 초점 데이터 자체의 정확성 데이터 간의 관계 관점 개별 데이터 보호 시스템 전체 일관성 질문 “변조되었나?” “일치하나?” 범위 단일 데이터/테이블 시스템 전체 - 무결성
PKI
- PKI (Public Key Infrastructure)
- 공개 키 암호화 시스템을 관리하는 전체적인 체계
- 핵심 요소
- 공개키/개인키 쌍
- 수학적으로 연결된 두 개의 키
- 공개키: 누구나 알 수 있는 키 (암호화용)
- 개인키: 본인만 알고 있는 키 (복호화용)
- 디지털 인증서
- 공개키가 진짜 그 사람 것인지 증명하는 전자 신분증 같은 것
- 마치 주민등록증처럼 “이 공개키는 진짜 김철수 것이 맞습니다.” 라고 보증해 줌.
- 인증기관 (CA, Certificate Authority)
- 디지털 인증서를 발급하고 관리하는 기관
- 정부 기관이나 신뢰할 수 있는 회사들이 운영
- 등록기관 (RA, Registration Authority)
- 인증서 발급 전에 신원을 확인하는 곳
- 공개키/개인키 쌍
- 하는 일
- 암호화
- 중요한 데이터를 안전하게 전송
- 디지털 서명
- 문서가 위변조되지 않았음을 증명
- 인증
- “너 정말 김철수 맞아?” 같은 신원 확인
- 부인방지
- “나 그런 문서 보낸 적 없어!” 같은 부인을 방지
- 암호화
- 실생활 예시
- 온라인 뱅킹
- 은행 사이트 접속할 때 SSL/TLS 인증서
- 전자세금계산서
- 국세청에서 쓰는 공인인증서
- 이메일 보안
- 중요한 메일 암호화
- 코드 서명
- 프로그램이 안전한지 검증
- 온라인 뱅킹
Zero Trust
- 절대 믿지 말고 항상 확인하라.
- 기존 보안 모델
- “내부 네트워크는 안전하다.” 라고 가정
- ZeroTrust
- “내부든 외부든 상관없이 모든 접근을 의심하자.”
- 기존 보안 모델
- 주요 원칙
- Never Trust, Always Verify
- 그 누구도 믿지 말고 항상 검증
- 최소 권한 원칙
- 꼭 필요한 권한만 부여
- 모든 트래픽 검사
- 내부/외부 구분 없이 모든 네트워크 트래픽 검사
- ID 기반 접근제어
- 사용자/디바이스 신원 확인이 최우선
- Never Trust, Always Verify
- 사용자가 로그인할 때마다 인증
- 디바이스 상태 확인 (패치 여부, 보안 정책 준수 등)
- 네트워크 위치 상관없이 모든 리소스 접근 시 검증
- 마이크로 세그멘테이션으로 네트워크 분할
인증/인가 관련
- MFA (Multi-Factor Authentication) - 다중 인증
- SSO (Single Sign-On) - 단일 로그인
- SAML (Security Assertion Markup Language) - 인증 정보 교환 표준
- OAuth 2.0 / OpenID Connect - 인가/인증 프로토콜
- RBAC (Role-Based Access Control) - 역할 기반 접근 제어
- ABAC (Attribute-Based Access Control) - 속성 기반 접근 제어
- PAM (Privileged Access Management) - 특권 계정 관리
네트워크 보안
- SASE (Secure Access Service Edge) - 보안 + 네트워크 융합
- SD-WAN (Software-Defined WAN) - 소프트웨어 정의 WAN
- Micro-segmentation - 마이크로 세그멘테이션
- SDP (Software-Defined Perimeter) - 소프트웨어 정의 경계
- ZTNA (Zero Trust Network Access) - 제로트러스트 네트워크 접근
모니터링/분석
- SIEM (Security Information and Event Management) - 보안 정보 통합 관리
- SOAR (Security Orchestration, Automation and Response) - 보안 오케스트레이션
- UEBA (User and Entity Behavior Analytics) - 사용자 행동 분석
- EDR (Endpoint Detection and Response) - 엔드포인트 탐지 대응
클라우드 보안
- CASB (Cloud Access Security Broker) - 클라우드 접근 보안 브로커
- CWPP (Cloud Workload Protection Platform) - 클라우드 워크로드 보호
디바이스 관리
- MDM (Mobile Device Management) - 모바일 디바이스 관리
- UEM (Unified Endpoint Management) - 통합 엔드포인트 관리
- Device Trust - 디바이스 신뢰성 평가
이 용어들 조합해서 ZeroTrust 아키텍처를 구성하는 거야!
용어 정리집
- Big O : Big Ordnung (오르드눙) Notation
- 오르드눙 (Ordnung)은 질서 , 규율, 규칙, 배열, 조직 또는 시스템을 의미하는 독일어 입니다
- CPU: central processing unit 중앙 처리 장치
- GPU: graphic processing unit 그래픽 처리 장치
- RAM: Random Access Memory 사용자가 자유롭게 내용을 읽고 쓰고 지울 수 있는 기억장치
- ROM: Read Only Memory 메모리의 주요 용도는 컴퓨터의 바이오스나 UEFI 같은 펌웨어를 저장
- HDD: Hard Disk Drive
SSD: Solid State Drive
- inode: index node
- 리눅스 OS에서 개별 파일에 관련된 속성 정보를 가지고 있는 약 120byte의 구조체로, 모든 파일은 정확히 하나의 inode를 가진다.
- MTU (Maximum Transmission Unit) : 네트워크에서 한 번에 전송할 수 있는 최대 데이터 패킷 크기
- MSS (Maximum Segment Size) : TCP 연결에서 한 번에 전송할 수 있는 최대 세그먼트 크기
- TCP 헤더 20byte, IP 헤더 20byte로 MTU가 1500byte 일 경우 MSS는 1460byte
- ARP : Address Resolution Protocol (주소 확인 프로토콜)
- IP : Internet Protocol
- TCP : Transmission Control Protocol (전송 제어 프로토콜)
- UDP : User Datagram Protocol (사용자 데이터그램 프로토콜)
- SSL : Secure Sockets Layer (보안 소켓 계층)
- TLS : Transport Layer Security (전송 계층 보안)
- SSH : Secure SHell
- HTTP : HyperText Transfer Protocol
SFTP : Secure File Transfer Protocol
- SQL : Structured Query Language
- NoSQL : Not Only Structured Query Language